
迴圈遞迴神經網路
1、在自然語言處理過程中,神經網路中輸入的語言中的每個單詞都是以向量的形式送入的,那個該怎樣將語言轉化為向量形式呢?
一般採用1-of-N編碼方式處理,處理過程如下:

具體原理參考筆記:
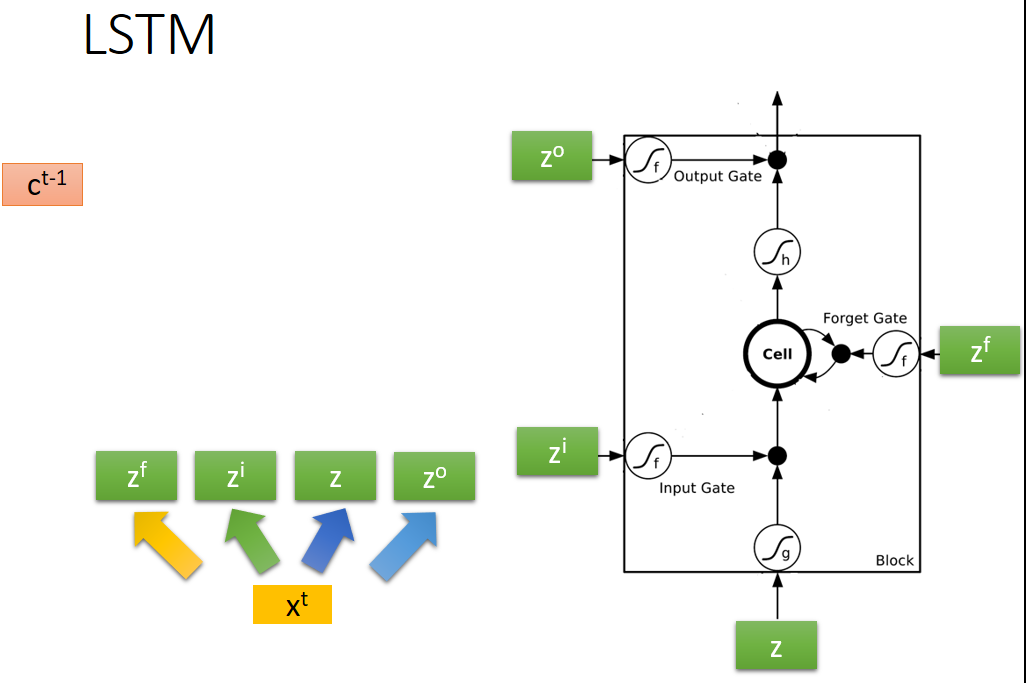
2、Long Short-term Memory(LSTM)結構框架如下圖所示:

由圖可知:LSTM共有三個門和一個記憶體單元,顧名思義,是門就有開和關兩種狀態,所以三個門都有各自的訊號控制部分分別控制三個門的狀態,像一般的神經網路節點只有一個輸入和輸出,而對於LSTM來說,該網路有四個輸入(一個網路輸入和三個門控訊號)和一個輸出。
其執行過程如下圖所示:

這裡的啟用函式一般是sigmoid函式,sigmoid函式的輸出為0~1之間的值。注意這裡遺忘門的輸入是相乘,而輸出是相加。
LSTM實際執行例子如下:
輸入向量為x,輸出為y
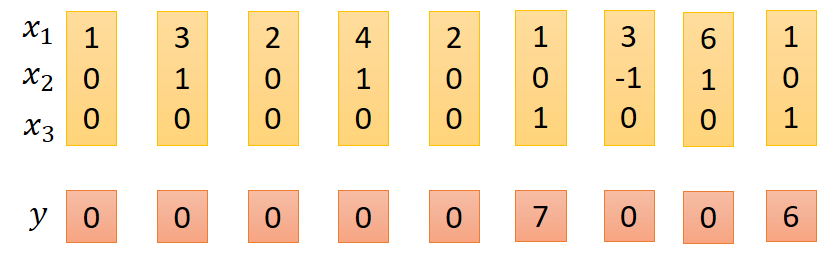
其中x1為網路需要處理的資料,定義x2、x3的功能分別如下:

注意這裡遺忘門和輸入門都是由x2控制,故x2可以有三-1、0、1種狀態,x3是輸出門控制訊號,實際結果處理如下:
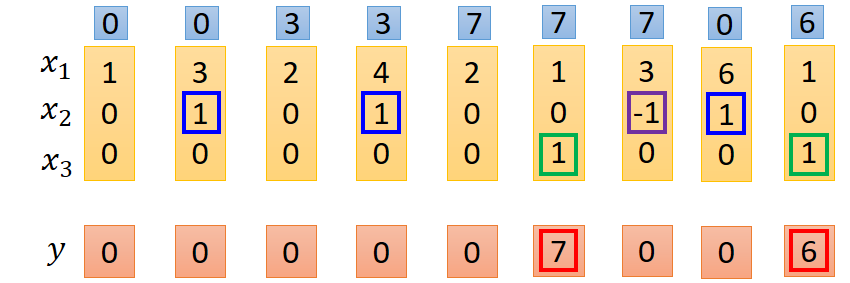
第一排資料是記憶體中的資料改變值過程。
具體處理過程的方式如下,只例舉了其中部分
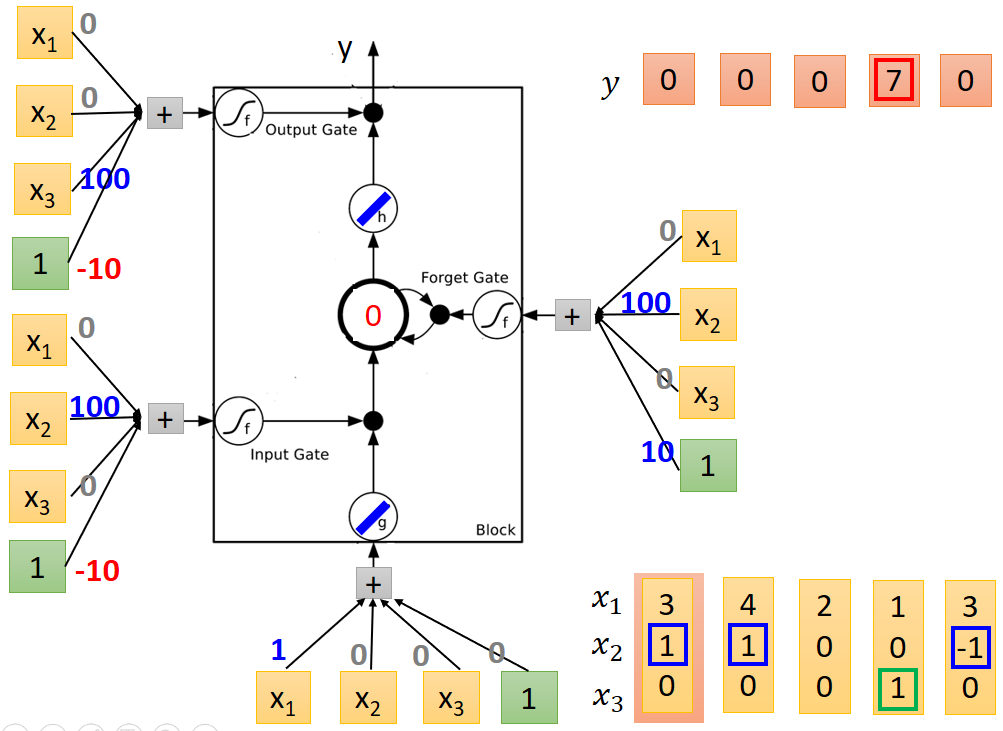
由圖中注意到,每一個輸入的節點都有相同的輸入,而每個節點不同的效果則由各個輸入的權重值決定,實際的輸入除了x1、x2、x3之外,還有一個1,這個輸入1的作用後面再解釋,下面就從權重這個角度解釋各個門的作用效果,LSTM單元輸入模組中,只有x1的權重不為0,而其他的權重均為0,所以所以給模組輸入只有x1有作用。同理對於輸入門和輸出門而言,只有x2、1有作用,輸出門只有x3、1有作用。
由以上分析可知,1只有在輸入、輸出和遺忘門中才有作用,而在遺忘門中和另外兩個門的作用效果又不相同,1的實際作用需要從啟用函式說起,一般來說LSTM的門節點的啟用函式均為sigmoid函式,輸出範圍為0~1之間,而實際輸出則為0和1兩個狀態,所以在sigmoid輸出後會進行歸一化處理,以0.5作為閾值,大於0.5則輸出1,否則為0。因為輸入門和輸出門1的權重相同,所以作用效果也一樣,只要分析其中一個即可,對於輸入門而言x2其作用,而x2有三種不同的取值,分別為-1、0、1;當取值為1時,啟用函式輸入值為100-10=90,sigmoid函式輸出值大於0.5,標準化後輸出為1,即輸入門開,當為-1時,sigmoid輸入值為-110,此時sigmoid輸出小於0.5,標準化後為0,輸入門關閉。當為0時,1的作用體現出來了,如果沒有1,則sigmoid函式輸入值為0輸出值為0.5,此時就無法將其標準化為0或者1了,如果有一個1,則sigmoid函式輸入值為-10,輸出值小於0.5,可將其標準化為0。輸出門的作用也是同樣的道理。對於遺忘門而言,x2為-1才有作用,復位記憶體,即sigmoid函式輸出為0,當x2為-1時,sigmoid輸入值為-90,輸出小於0.5標準化後為0,復位記憶體,同理當x2為1是,sigmoid輸出標準化後輸出為1,當x2為0是,如果沒有1,則會出現輸入門一樣的情況,無法標準化為0或者1,有1後就可以標準化為1.
資料流向過程如下圖所示:
剛開始記憶體中的值為0。
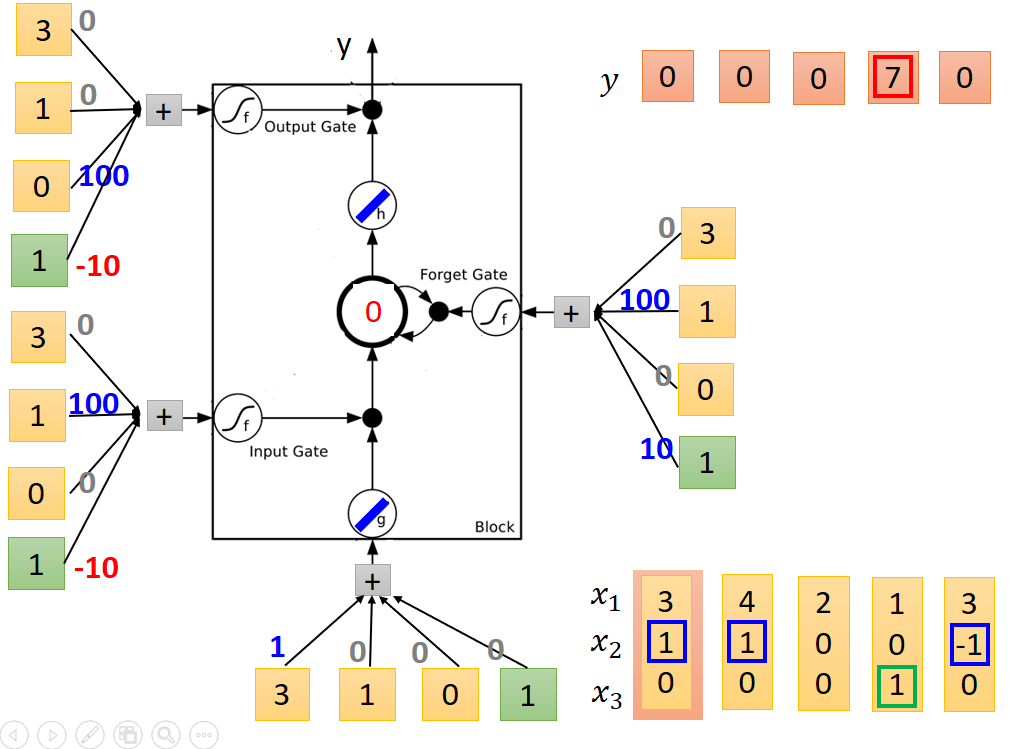
送入第一列值後個節點輸出結果如下:
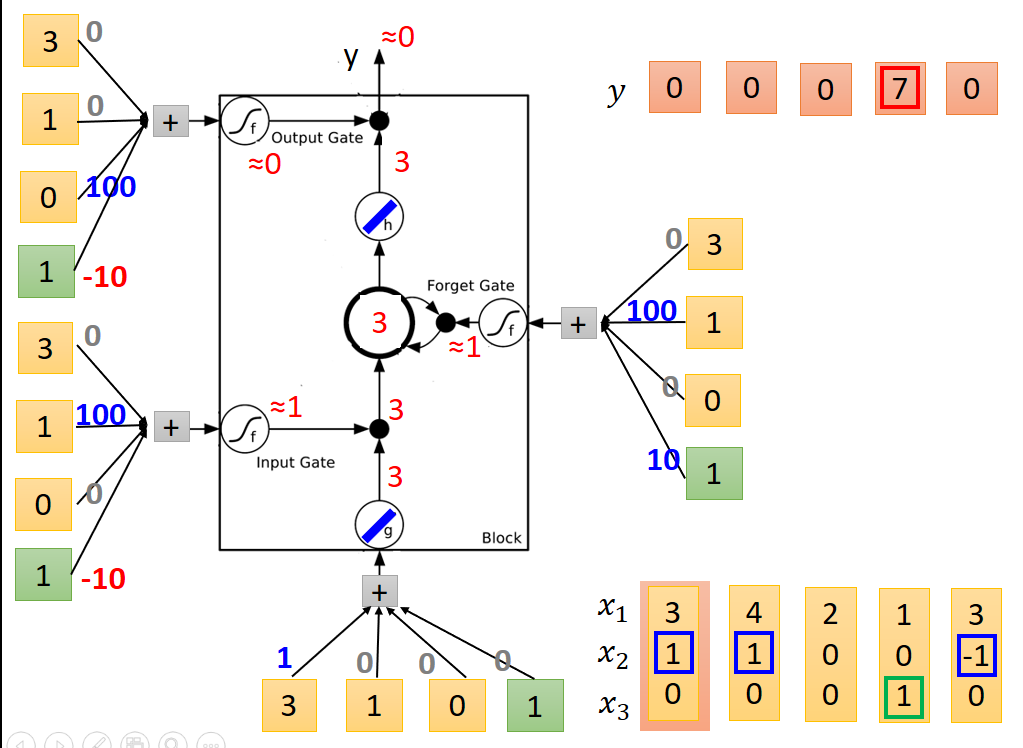
送入第二列值後節點輸出結果如下:注意記憶體中的值為和上一次相加。
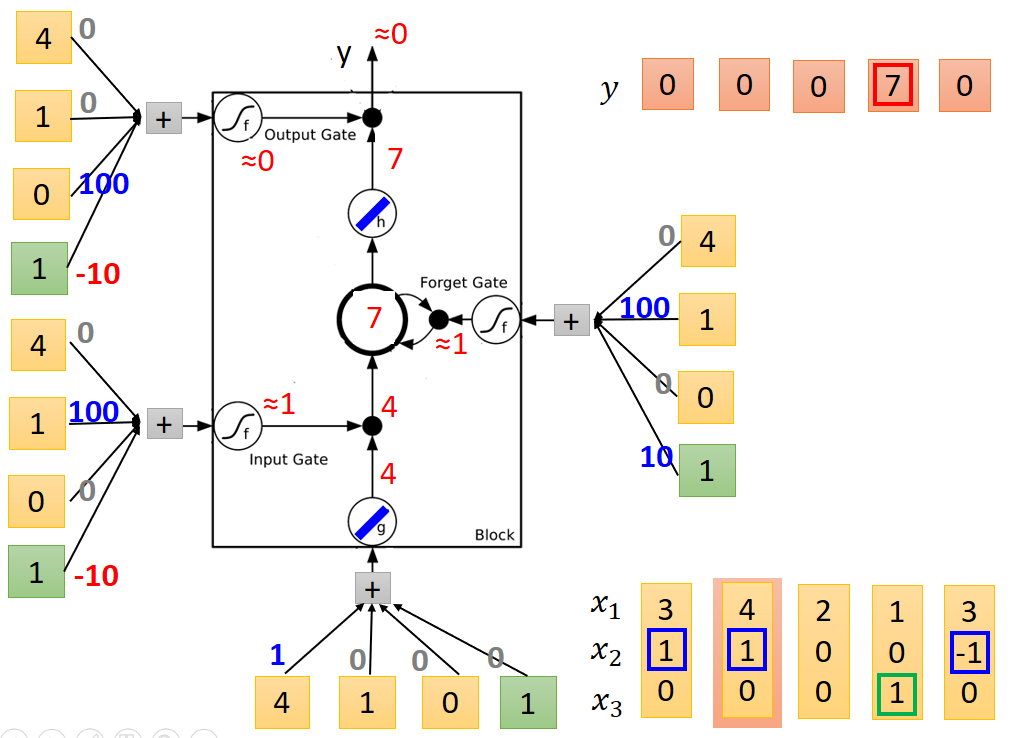
第三列
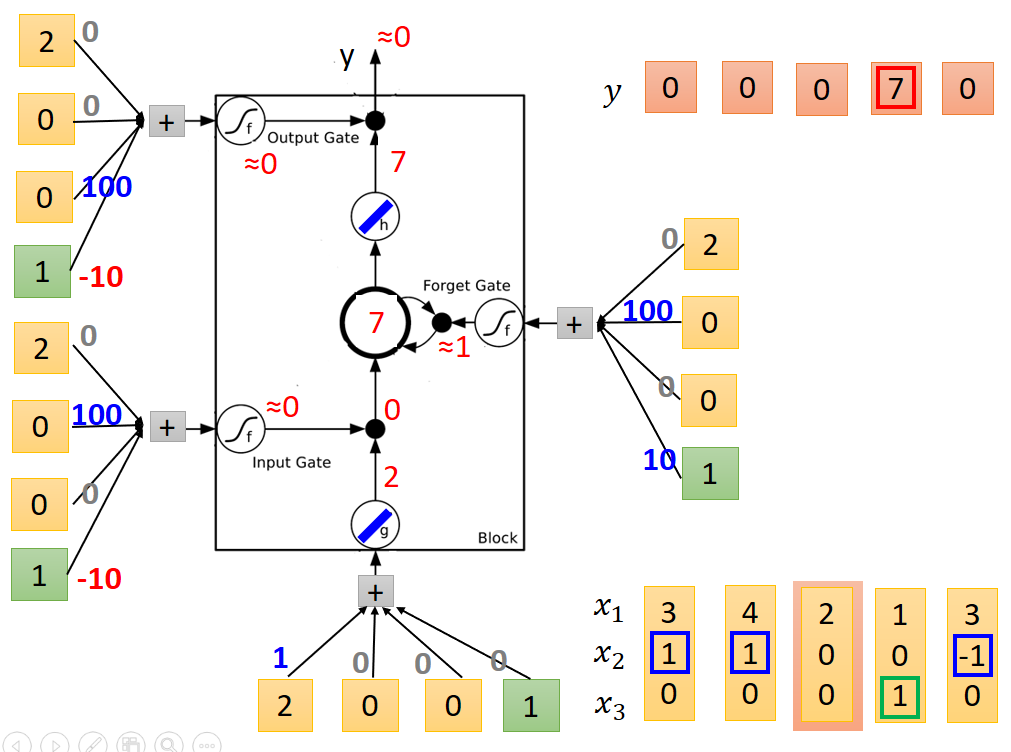
第四列,輸出結果為7

第五列
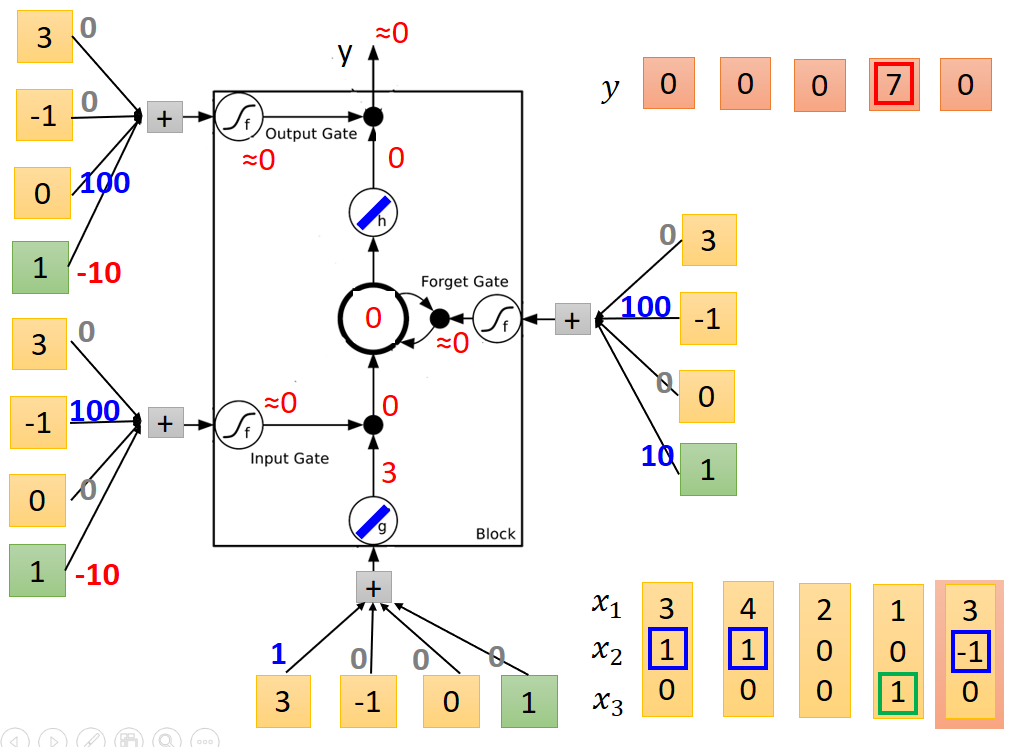
至此,整個例子執行結束。
以上就是LSTM網路結構原理圖解
3、LSTM的特點
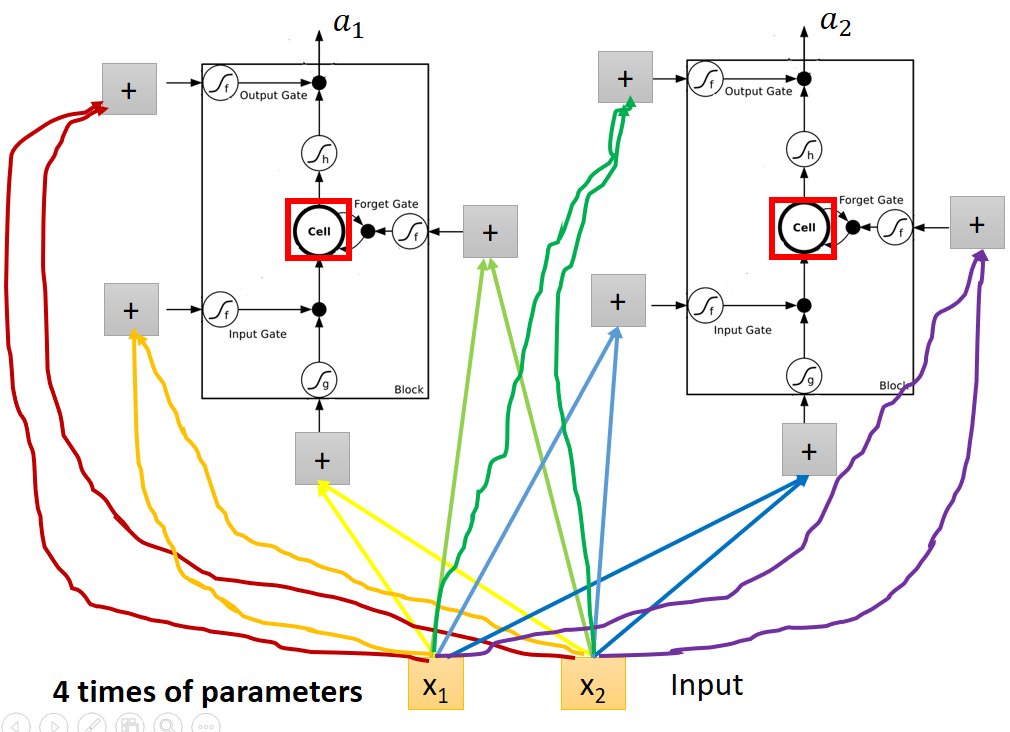
一般的神經網路如下:

用LSTM代替後引數數量變為原來的四倍
4、LSTM變體
上圖中向量c表示記憶體中原有的值,輸入向量xt經過不同的權值處理後分別產生了四個z分別對應LSTM的四個輸入。

上圖中,每個LSTM輸入中都包含有上一個LSTM的記憶體值和輸出值,再分別作用到四個輸入埠,也可以等價的理解,將上一次LSTM的記憶體值和輸出值分別作用到下一個LSTM的四個輸入埠,此連線成為peephole連線。
多層連線
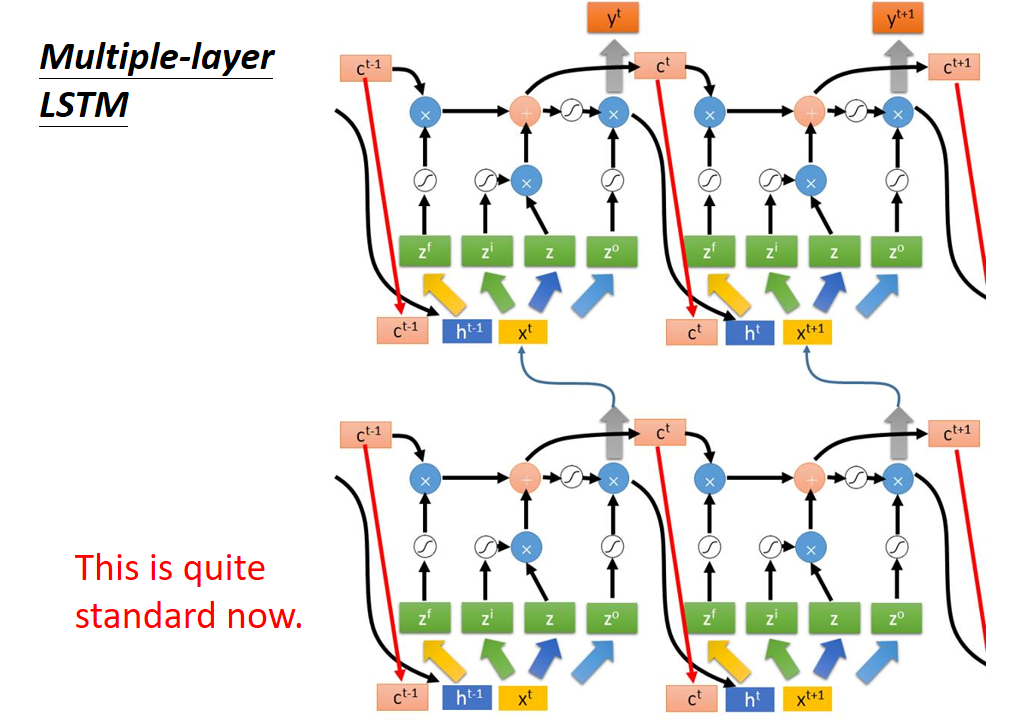
當前形式為標準形式
LSTM主要學習的什麼呢?
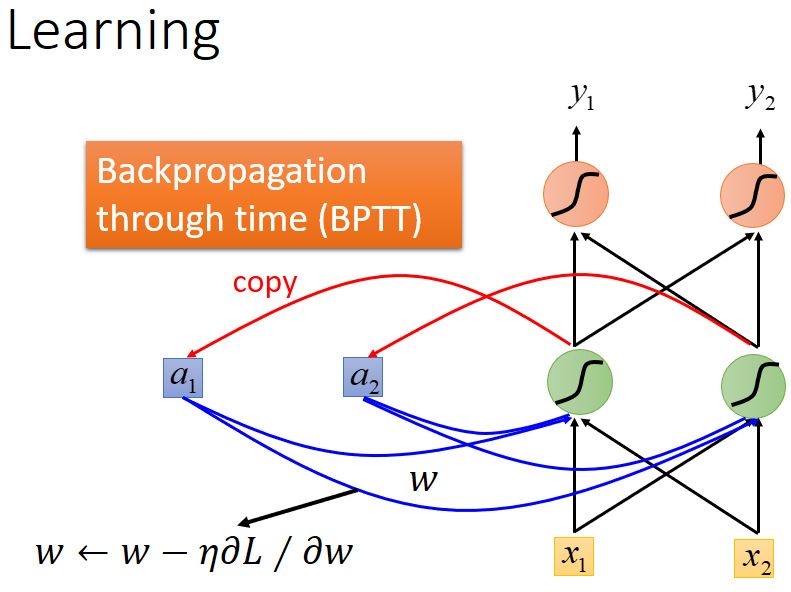
學習的主要是記憶體單元值回送至下一次記憶體中的權重值,如圖中w值。
學習演算法為:Back Propagation Through Time(BPTT)反向傳播演算法(演算法原理稍後再講)
然而基於以上討論的RNN在實際訓練過程中並不總是可以得到理想的結果,代價函式有時會出現巨大的波動,如下圖所示:

主要是代價函式曲線誤差面不是梯度消失就是梯度爆炸,如下圖所示:
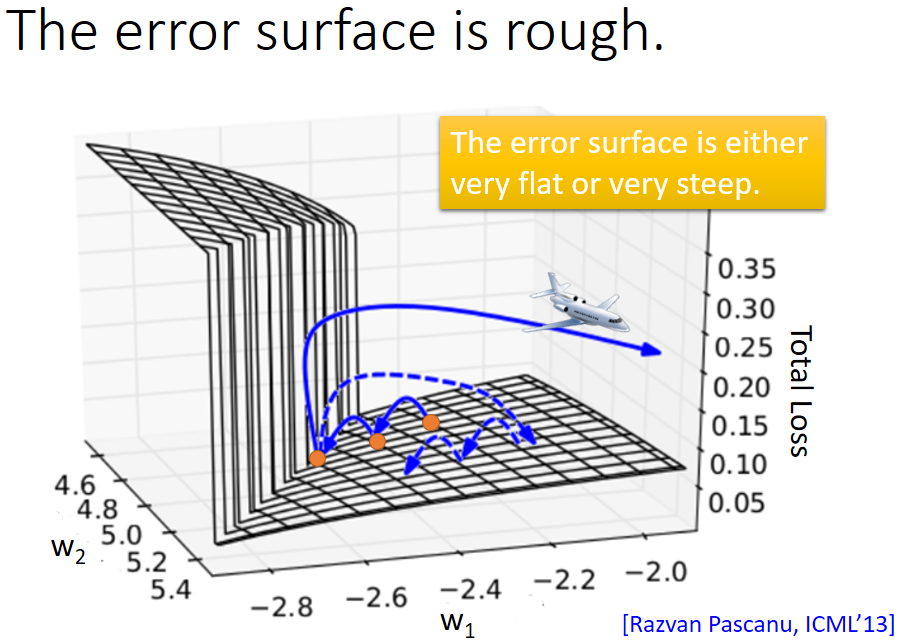
主要原因就是學習引數w導致,原因如下:
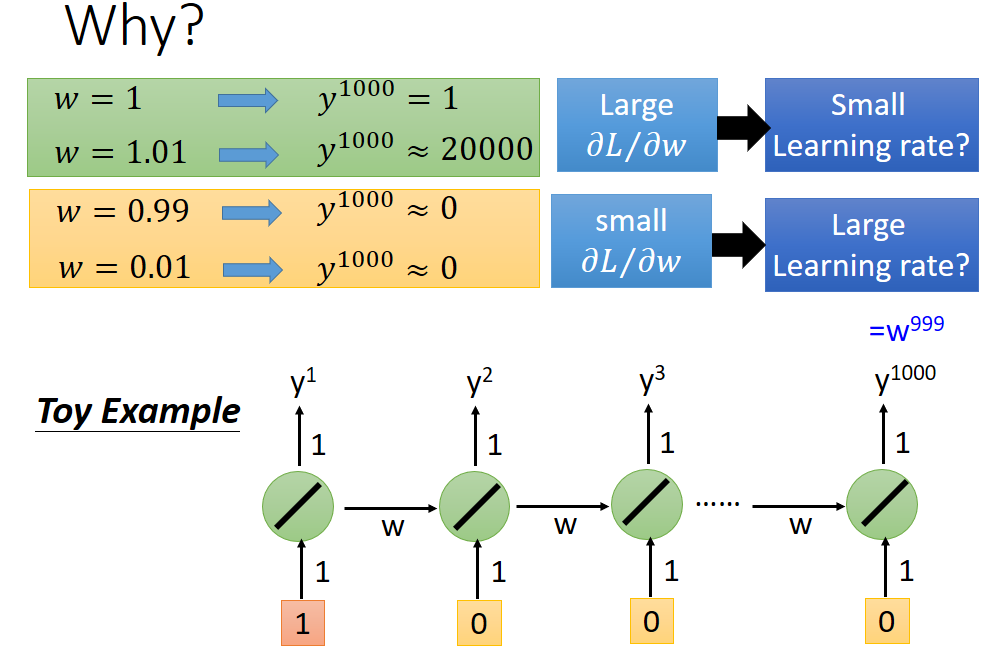
如果直接取w為1,即相當於將原始記憶體值直接加到新的記憶體中可以解決梯度消失問題,如下圖所示:

因為w始終為恆定值1,所以基於上述圖解

w=1時,輸出就是輸入值,而不會受到w的影響而改變,只要輸入不為0,就不存在輸出值y為0的情況,所以也就不會有梯度消失的情形。
w=1時的LSTM就是GRU單元。