
Matlab灰色預測和統計分析
阿新 • • 發佈:2019-02-01
如何利用Matlab讀取資料進行統計分析?
假設有我在D盤根目錄下有5個txt文字,其檔案格式如下:
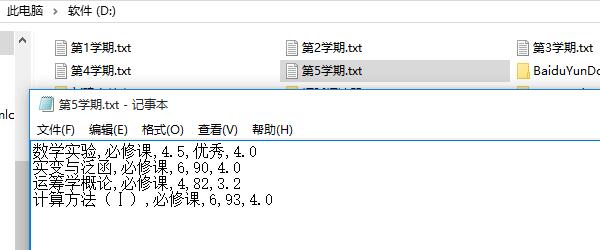
我們需要如何讀取這個這樣中英文數字混編的資料進行統計分析呢?
假設我們的資料都是以ANSI編碼,如果不是,需要進行另存為覆蓋儲存為這種編碼格式。
接下來,老規矩,廢話不多說,直接上程式碼。
- 編寫drop.m函式檔案,功能是篩去校選修課資料(院選修課我沒見過,故不能臆斷)。
function s=drop(s,term_type)
[bool,inx]=ismember('校_任選課',term_type);
if bool
s(inx)=[];
end- 編寫grade.m函式檔案,以zzu績點計算規則,計算每學期的平均績點。
function grade=grade(term_credit,term_grade,term_type)
credit=drop(term_credit,term_type);
weight=credit/sum(credit);
grade=str2double(drop(term_grade,term_type));
grade=sum(weight.*grade);
end- 編寫主函式,作圖分析,分析包括簡單灰色預測,預測準確性不做評判。
%% 初始化變數。
clc
clear
for i=1:5
str_i=num2str(i);
filename = ['D:\第' - 結果如下:
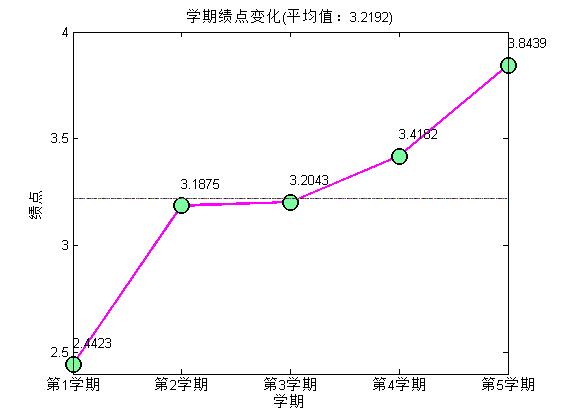
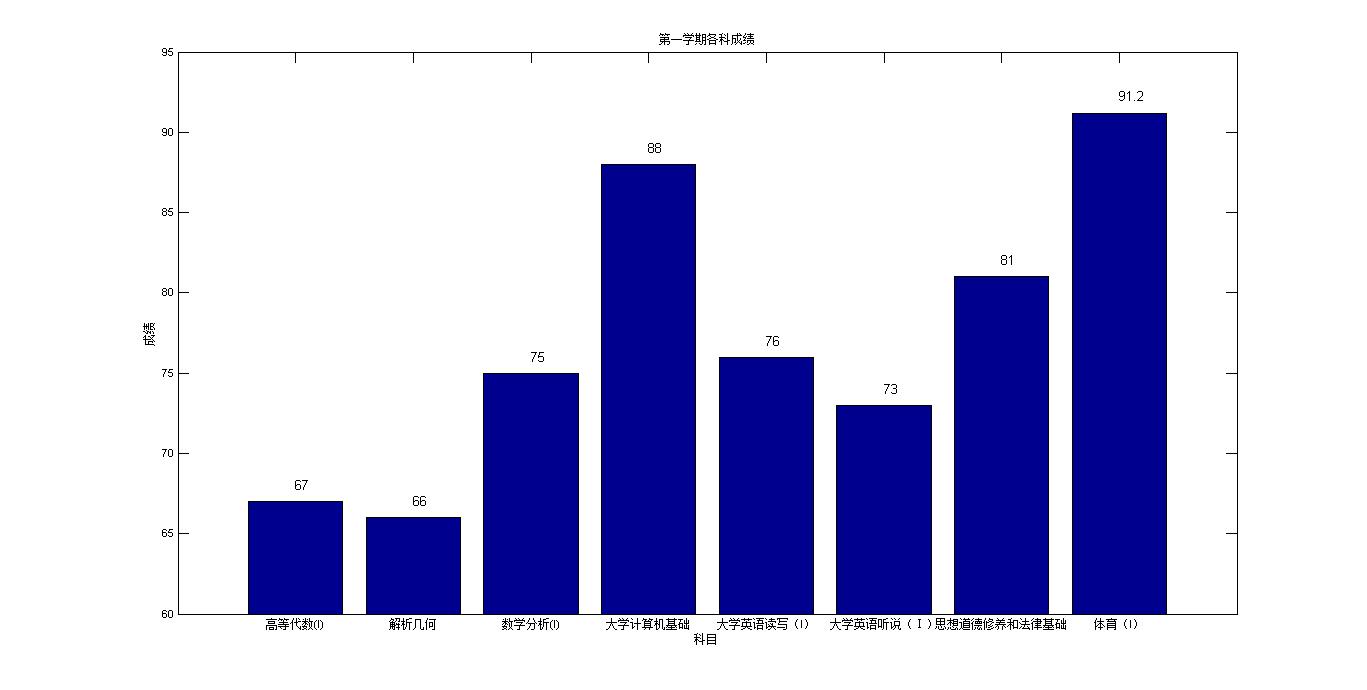
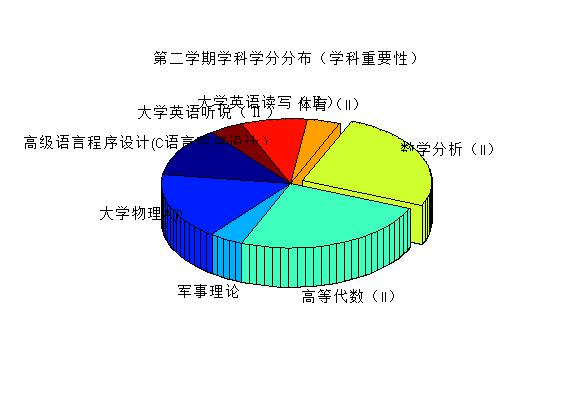
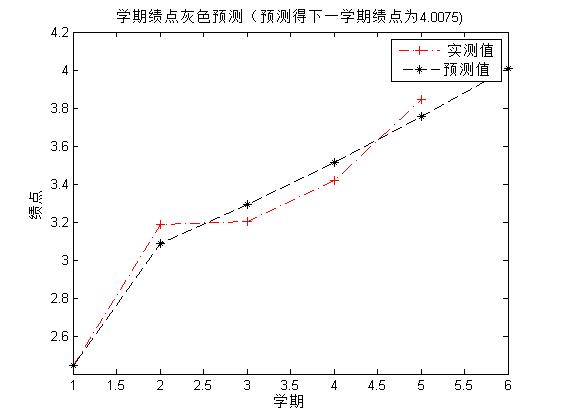
也沒有其他要說的,強調一下eval函式的妙用,可以自動命名變數並進行賦值。另外,除了學分是純的數字以外,其他列的資料或多或少都摻雜著兩種以上的資料型別,因此都當做字串的格式讀入。之後再根據需要進行轉化處理。