
RNN LSTM與GRU深度學習模型學習筆記
阿新 • • 發佈:2019-02-02
RNN(Recurrent Neural Network), LSTM(Long Short-Term Memory)與GRU(Gated Recurrent Unit)都是自然語言處理領域常見的深度學習模型。本文是一個關於這些模型的筆記,依次簡單介紹了RNN, LSTM和GRU。在學習了大量的語言樣本,從而建立一個自然語言的模型之後,可以實現下列兩種功能。
- 可以為一個句子打分,通過分值來評估句子的語法和語義的正確性。這個功能在機器翻譯系統中非常有用。
- 可以造句,能夠模仿樣本中語言的文風造出類似的句子。
RNN
RNN的定義
在傳統的神經網路中,輸入是相互獨立的,但是在RNN中則不是這樣。一條語句可以被視為RNN的一個輸入樣本,句子中的字或者詞之間是有關係的,後面字詞的出現要依賴於前面的字詞。RNN被稱為併發的(recurrent),是因為它以同樣的方式處理句子中的每個字詞,並且對後面字詞的計算依賴於前面的字詞。一個典型的RNN如下圖所示。
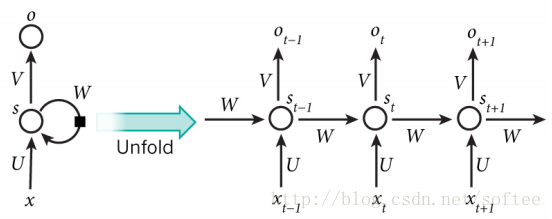
圖中左邊是RNN的一個基本模型,右邊是模型展開之後的樣子。展開是為了與輸入樣本匹配。假若輸入時漢語句子,每個句子最長不超過20(包含標點符號),則把模型展開20次。
xt 代表輸入序列中的第t 步元素,例如語句中的一個漢字。一般使用一個one-hot向量來表示,向量的長度是訓練所用的漢字的總數(或稱之為字典大小),而唯一為1的向量元素代表當前的漢字。st 代表第t 步的隱藏狀態,其計算公式為st=tanh(Uxt+Wst−1) 。也就是說,當前的隱藏狀態由前一個狀態和當前輸入計算得到。考慮每一步隱藏狀態的定義,可以把st 視為一塊記憶體,它儲存了之前所有步驟的輸入和隱藏狀態資訊。s−1 是初始狀態,被設定為全0。ot 是第t 步的輸出。可以把它看作是對第t+1 步的輸入的預測,計算公式為:ot=softmax(Vst) 。可以通過比較ot 和xt+1 之間的誤差來訓練模型。U,V,W 是RNN的引數,並且在展開之後的每一步中依然保持不變。這就大大減少了RNN中引數的數量。
假設我們要訓練的中文樣本中一共使用了3000個漢字,每個句子中最多包含50個字元,則RNN中每個引數的型別可以定義如下。
xt∈R3000 ,第t 步的輸入,是一個one-hot向量,代表3000個漢字中的某一個。ot∈R3000 ,第t 步的輸出,型別同xt 。st∈R50 ,第t 步的隱藏狀態,是一個包含50個元素的向量。RNN展開後每一步的隱藏狀態是不同的。U∈R50 ,在展開後的每一步都是相同的。∗3000V∈R3000∗50 ,在展開後的每一步都是相同的。W∈R50∗50 ,在展開後的每一步都是相同的。
其中
st=tanh(Uxt+Wst−1) ot=softmax(Vst)
RNN的訓練
為了訓練網路,必須對其進行訓練。需要計算預測字和輸入字之間的誤差來修改網路中的引數,進而優化模型。使用cross-entropy損失函式來計算誤差。假設輸入文字中有
訓練的目的是找到合適的
為方便描述,在誤差函式
那麼,根據之前的定義,可以知道