
機器學習演算法調優的一般步驟
引言
假設我們實現了一個機器學習演算法用於做分類,但在測試集上結果不好,下一步應該怎麼辦呢?有沒有一些一般性的指導原則對我們的演算法調優進行指導?
除了模型本身的一些引數調節,大部分人都知道去嘗試下面一些通用的調整方法:
- 增加訓練集
- 減少特徵維度(從已有的特徵中挑選出一部分)
- 增加新特徵
- 增加多項式元素(比如將特徵平方後疊加到原特徵上,相當於增加了非線性的輸入)
- 減小正則化引數的
λ 值 - 增大正則化引數的
λ 值
正如Andrew NG在機器學習課程上所說,上面提到的每一個方法,都可以擴充套件成一個6個月的專案;而大部分人都是憑直覺選擇這些方法的,這浪費了大量的調優時間。有沒有科學的指導原則來幫助我們選擇這些通用的調整方法呢?
本文就以線性迴歸為例,詳細講解如何選擇這些通用的調整方法,得出的結論也適用於其他的機器學習演算法。下面先介紹正則化的作用。
正則化
這裡先引入正則化的概念。
直觀理解
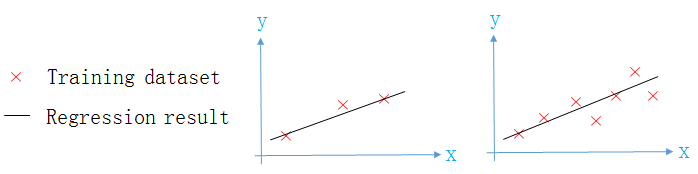
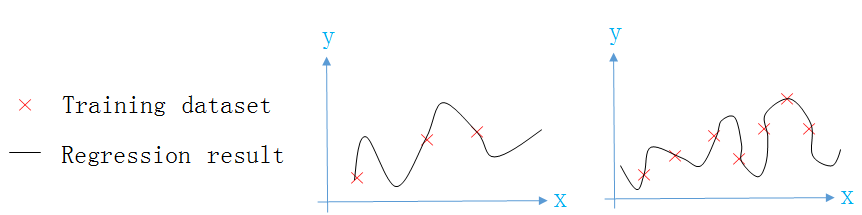
兩個模型的迴歸曲線如下圖所示,從圖中可以看出,第二個模型已經過擬合(overfitting)。
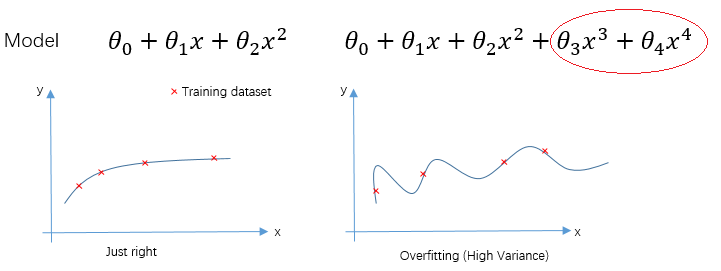
如果我們減小正則化要做的,就是適當減小
正則化定義
正則化引數
過擬合
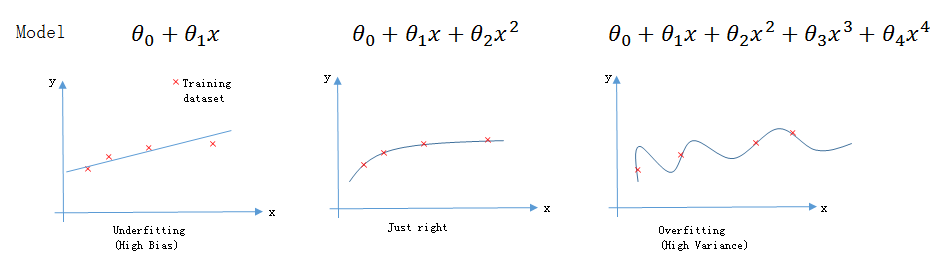
三種擬合的情況
欠擬合: 連訓練集都不能很好的擬合,又叫High BiasJust Right: 能很好的擬合訓練集與測試集過擬合: 能很好的擬合訓練集,但不能很好的擬合測試集,又叫High Variance
從下圖可以直觀的看出三種擬合情況之間的區別。
調優時,首先需要判斷模型處於哪種擬合情況。怎麼判斷呢?就是劃分訓練集後,繪製Learning Curve即可。
訓練集劃分(train & validation & test)
一般按6:2:2的比例,將資料集分為訓練集,驗證集,測試集。
為什麼需要驗證集呢?
- 如果沒有validation dataset,則可能訓練出來的模型僅僅匹配測試集,而不適用於將來的資料。驗證集能提高一定的泛化能力
- 驗證集能保證模型訓練到最優(比如可以用early stop策略)
Learning Curve(學習曲線)
Learning Curve是訓練集誤差與驗證集誤差相對於訓練集數目m的二維曲線圖。這裡和下面的m,表示有多少個訓練集。比如我有1000個手寫數字訓練樣本,m=10,表示從中取10個做訓練集;m=1000,表示從中取1000個做訓練集。
訓練集誤差:是根據訓練集predic結果h,與真實結果y計算得到的。
- 這裡m是橫軸,動態變化。
驗證集誤差:同理,是根據驗證集結果計算得到的。
- mcv是訓練集個數,固定值。
將Learning Curve。

下面介紹三種擬合情況的Learning Curve。
Learning Curve of Just Right
假設Just Right情況下的線性模型為
下面是訓練集個數m不同時,模型擬合訓練集的情況。
可見
- 隨著訓練集數量m的增加,模型遇到的情況就越複雜,在
訓練集上的誤差會逐漸增加,但都會保持在較小的一個範圍內 - 隨著訓練集數量m的增加,模型見多識廣,所以模型在
驗證集上的誤差就逐漸減少,且越來越接近訓練集誤差
所以Just Right情況下的Learning Curve如下圖所示
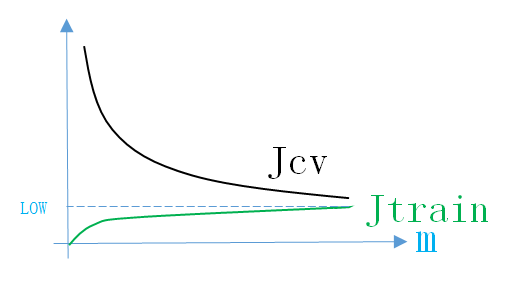
同理,畫出Learning Curve後,如果滿足上面的條件,就說明模型處於Just Right情況。說明模型的結構正確,接下來就不用調整結構引數,調節模型其它引數(正則化引數
Learning Curve of High Bias
假設High Bias情況下的線性模型為
下面是訓練集個數m不同時,模型擬合訓練集的情況。
可見
- 隨著訓練集數量m的增加,模型在
訓練集上的誤差會逐漸增加,且誤差會越來越大 - 隨著訓練集數量m的增加,模型在
驗證集上的誤差會有所下降,誤差依然很大,且越來越接近訓練集誤差
所以High Bias情況下的Learning Curve如下圖所示
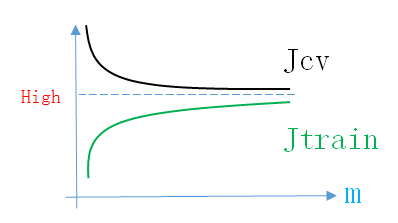
同理,畫出Learning Curve後,如果滿足上面的條件,就說明模型處於High Bias情況。說明模型的結構不正確,接下來就應該先調整結構引數(增加新feature,增加多項式項,減小正則化引數,增加神經網路隱層神經元個數)。
Learning Curve of High Variance
假設High Variance情況下的線性模型為
下面是訓練集個數m不同時,模型擬合訓練集的情況。
可見
- 隨著訓練集數量m的增加,模型在
訓練集上的誤差會逐漸增加(不可能擬合的天衣無縫),但由於模型的擬合能力較強,所以誤差都會很小 - 隨著訓練集數量m的增加,模型在
驗證集上的誤差會有所下降,但由於模型擬擬合能力強,把訓練集上的毛刺都擬合了,所以誤差依然很大,且與訓練集誤差有較大的差距。但驗證集誤差會隨著m的增加而減少
所以High Variance情況下的Learning Curve如下圖所示
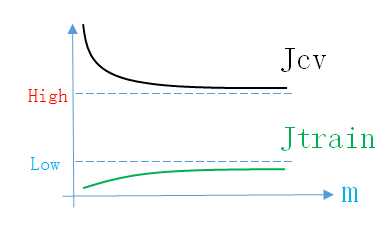
同理,畫出Learning Curve後,如果滿足上面的條件,就說明模型處於High Variance情況。說明模型的結構不正確,接下來就應該先調整結構引數(減小feature數量,增加正則化引數,減小神經網路隱層神經元個數)。High Variance情況下,也可以採用增加m的方法使誤差下降。
結論
綜上,我們可以發現,對機器學習演算法進行調優,首先要根據Learning Curve來判斷模型處於哪種擬合情況,從而判斷模型結構是否正確。調整時,先進行模型結構調整(feature數量,多項式元素),讓模型處於Just Right的情況,再調整非結構引數(正則化引數)。
所以,下面給出開頭給出問題的解答
- 增加訓練集: Fix High Variance
- 減少特徵維度(從已有的特徵中挑選出一部分): Fix High Variance
- 增加新特徵: Fix High Bias
- 增加多項式元素(比如將特徵平方後疊加到原特徵上,相當於增加了非線性的輸入): Fix High Bias
- 減小正則化引數的
λ 值: Fix High Bias - 增大正則化引數的
λ 值: Fix High Variance
例項分析
下圖是未經調優模型的Learning Curve,訓練模型用到的Feature是1維的。
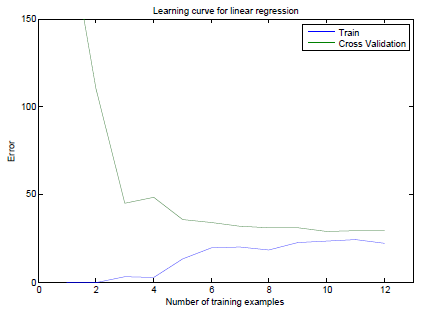
可見訓練集誤差曲線變動較大,隨著訓練集數量m的增加還一直增加,誤差較大。且訓練集誤差接近驗證集誤差。這說明模型處於High Bias的狀態。所以我們將一維的Feature做乘方後擴充到8維,得出的Learning Curve見下圖。
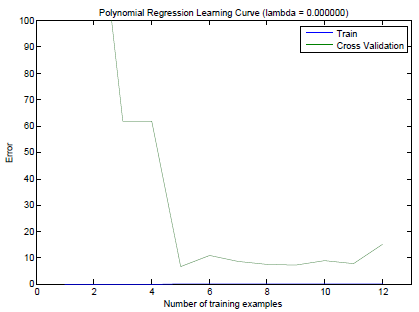
此時訓練集誤差隨著m增加都維持在一個較小的範圍,且驗證集誤差也隨著m的增加而下降,訓練集誤差與驗證集誤差都較小,這就說明通過新增多項式特徵,將模型的High Bias狀態調整到了Just Right狀態。此時模型的結構到達了正常狀態。
將模型結構調整正確後,接下來再為模型調整正則化引數