
如何對PDF文獻做視覺化分析?
看了大量文獻後,你的硬碟上想必存下不少PDF檔案。能否充分利用它們,挖掘出你獨特的領域知識地圖呢?本文為你提供一種簡便易行的辦法。

疑問
在網上寫文章最大的好處,是經常可以收到讀者的反饋。不少讀者會提出一些好問題,時常給我以啟發。
前些日子,我寫了《如何快速梳理領域文獻》一文,為大家講解了如何使用VosViewer這一文獻視覺化分析工具,快速梳理領域文獻。
有讀者來信,提出一個疑問:
是否有軟體支援匯入PDF檔案,直接做文獻視覺化分析呢?
我看到這個問題,開始一愣,繼而會心一笑。
愣的原因是,我之前沒有想過會有這樣的需求。因為做文獻視覺化分析的時機,往往是我們剛剛接觸某一個領域,不確定
這時候,資訊的來源是文獻資料庫(Web of Science, Scopus等)的檢索結果。這些匯出的檢索結果裡面包含了足夠的可供分析的元資料資訊(作者、機構、時間、國別、期刊等)。
然而PDF檔案可就不一樣了。雖然它包含了文獻的全文,但是卻並不更適合提煉元資料資訊,做文獻視覺化分析。尤其是比起元資料匯出格式(例如RIS等),它的體積又大得多。
因此,很難想象一個文獻視覺化工具會選用PDF作為資料來源。
於是,我打算如實回答,在我接觸過的若干種主流文獻視覺化工具裡,沒有哪一款支援這樣的功能。
但是,我旋即想起了哈佛大學營銷學教授萊維特(Theodore Levitt)的那句經典名言:
人們其實不想買一個1/4英寸的鑽頭。他們只想要一個1/4英寸的洞。
如果透過表象,洞察使用者的實際需求,我就立刻能理解這位讀者的痛點在哪裡了。
痛點
對科研工作者來說,已閱讀文獻(大多是PDF格式)的管理,確實是個非常實際的難題。
我們經常會從各種文獻資料庫裡下載閱讀文獻,也因此會在硬盤裡積攢下大量的PDF檔案。這些文獻往往是在相對較長的一段時間內積累起來的,許多都經過了研究者的掃讀(skimming)甚至是精讀,確認和研究主題密切相關,才被一直保留下來。
當然,如果你閱讀後發現文獻不相關,都懶得整理……算我沒說。(幸好做視覺化分析的時候,這部分文獻可以相對容易地被識別出來。)
跟文獻資料庫裡檢索結果全集比起來,這些PDF數量雖多,一般也只是一個子集,並不夠全面和完備。但是我們對其更熟悉,而且這些文獻也更能準確刻畫我們對某個領域的掌握程度。
有的學科發展很快,研究熱點文獻噴湧而出。例如雙中子星合併被人類首次觀測當夜,就有若干篇相關文章發了出來。研究者硬盤裡PDF檔案積累成百上千篇,毫不稀奇。
一旦文獻數量超越了鄧巴數,你再想要“如數家珍”,難度就會大幅上升。大部分人甚至都會忘記,自己曾經下載、儲存並瀏覽過某個PDF檔案。
如果能夠利用文獻視覺化工具,對這些文獻做梳理,會有助於我們理清自己掌握文獻的脈絡,做到心中有數。
更進一步,如果我們把手頭PDF檔案的視覺化結果,與全域性檢索結果的分析圖形進行對比,還可以明顯看出自己對領域掃描是否全面。這將有助於我們找準大方向,避免在文獻叢林中迷失。
這樣看來,讀者的問題就透露出非常有意義的需求。
這種需求,未必需要通過一個全功能的,可以直接從PDF做出分析的文獻視覺化工具一站式完成。
我們可以把它拆解為兩個環節:
- 從PDF檔案提煉文獻元資料資訊;
- 將元資料資訊輸入到文獻視覺化工具做分析。
第二個環節,我在《如何快速梳理領域文獻》一文中,已經做了詳細的介紹。需要補充的是,後來我的學生還做了一個全中文的視訊教程,從頭到尾展示了一次文獻採集和分析過程。歡迎訪問這個連結來觀看。
我今天向你展示,如何從PDF檔案提煉文獻元資料資訊。
當然,你完全可以開啟PDF檔案,把其中各種元資料資訊手工提煉出來,然後照葫蘆畫瓢,儲存成Web of Science等文獻資料庫的匯出格式,輸入到VosViewer中。
但是,這顯然效率很低,而且非常容易出錯誤。
工欲善其事,必先利其器。我們會採用一款非常優秀的文獻管理工具,完成這一過程。
工具
這款工具,叫做Zotero。
安仁心智的董事長陽志平先生,曾經撰寫了系列文章,詳細介紹了Zotero的特色、功用和操作方法。建議你讀完本文後,認真通讀該系列文章。
本文只涉及到Zotero的幾個非常簡單實用的功能。因此如果你沒有聽說過Zotero,對它不熟悉,也不要緊。一步步按照下文的步驟操作就可以了。
請到這個網址下載最新版本的Zotero。

我使用的是macOS版本。下載後的格式為dmg。雙擊開啟該檔案後,拖拽Zotero應用圖示到Application目錄的快捷方式裡,即可完成安裝。
從Application目錄下,找到Zotero應用,開啟。
你就可以看到Zotero的主介面了。我很想給你展示一個空白的Zotero介面,可惜我已經在其中儲存了許多文獻內容了。
下文中,我新建了一個空白類別目錄,為你演示。
工具準備好了,下面我們來逐步展示操作流程。
操作
Zotero匯入PDF檔案,是非常方便的,只需要拖拽即可。下面這個GIF動圖為你演示了使用方法。
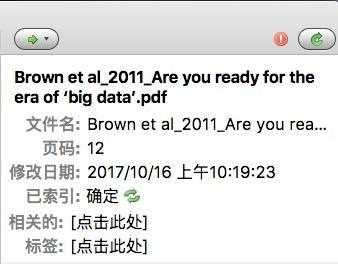
這時,你點選某個PDF檔案,右側的狀態列會有檔案描述。但是你可以看到,目前描述內容很少。只有檔名、頁碼和修改日期等。
不過我們可以很方便地利用Zotero的“重新抓取PDF元資料”功能,獲得完整的文獻描述資訊。
例如下面這個動圖,演示瞭如何右鍵選單選擇“重新抓取PDF元資料”,將PDF檔案變成元資料完備的文獻記錄。
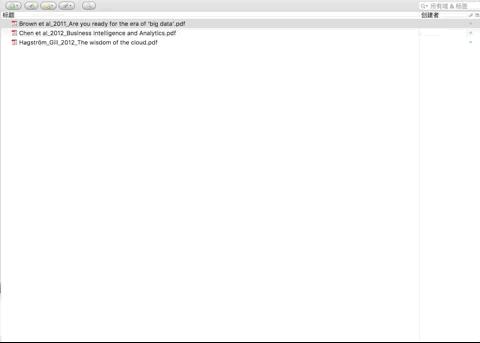
此時,右側的狀態列裡,文獻資訊可就清晰多了。

可以看到,標題、作者、期刊……甚至是頁碼都採集完整了。
下面我們需要把文獻集合的資訊匯出。為了和後續的文獻視覺化工具配合,請注意一定要選擇RIS格式。
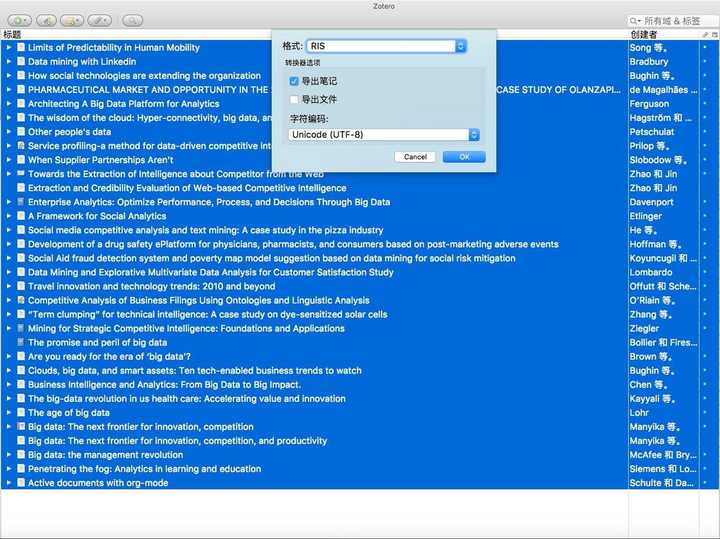
我們開啟匯出後的RIS檔案,預覽內容:

RIS檔案裡包含了許多做文獻分析需要用到的元資料。但是眼尖的你一定會發現,這裡缺少參考文獻列表資訊。因此,你無法做用它做文獻網路分析。但是它依然可以幫助我們挖掘很多有用的資訊。
我們在VosViewer下新建一個專案。
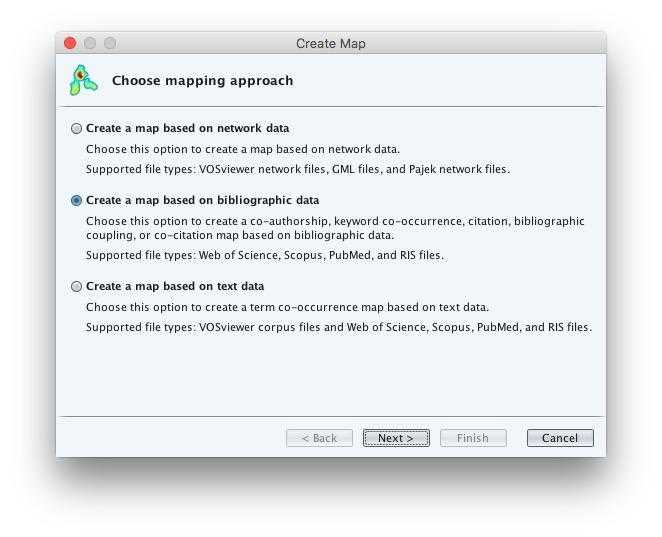
從選項中,可以看到第二項(Create a map based on bibliographic data)或者第三項(Create a map based on text data)功能的資料讀入方式,都支援RIS格式。
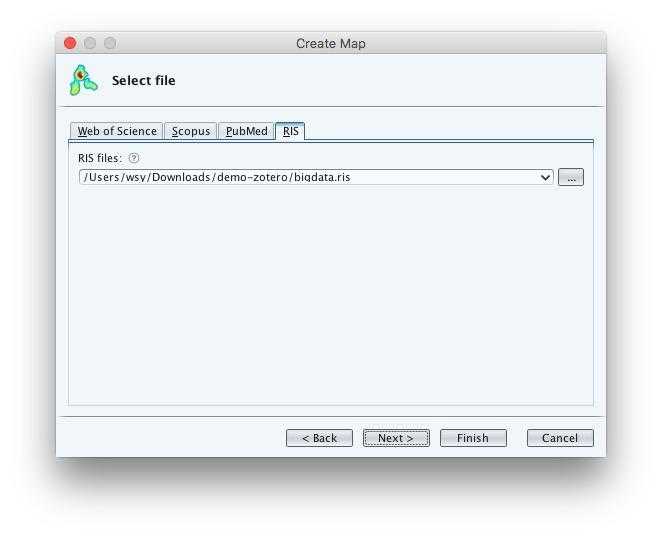
我們用第二項試試看。預設選項下,它可以抽取合著者(co-authorship)資訊。
因為樣例中文獻數量較少,所以我們降低了預設閾值,以獲得更為豐富的結果。
分析結果的密度圖如下:

可以看到,你收集的文獻中有哪些作者相對高產,以及他們之間的聯絡。
我們再試試第三項。分析主題資訊。
由於過程與第二項類似,我們就不再贅述了。分析結果如下圖所示。
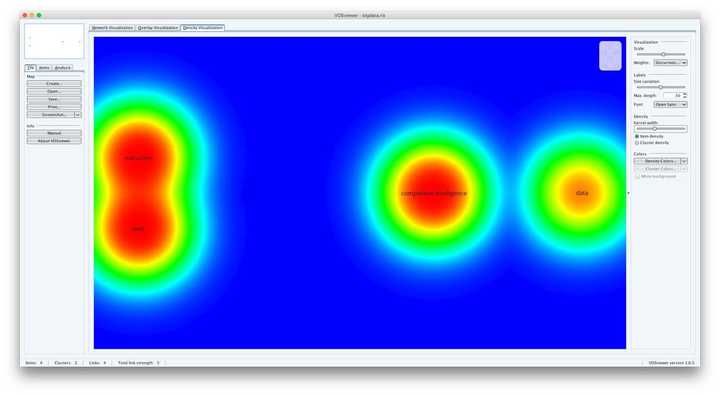
VosViewer正確識別出了我們查詢的文獻主題是大資料和競爭情報的關聯,而且揭示了許多文獻採用的方法是Web資訊抽取。
必須說明,此處我們只是為了展示操作方法,採用了非常簡單的文獻集。引數設定也沒有經過合理的調整。從數量這麼小的文獻集合裡,能獲得的知識和洞見是非常有限的。如果你積攢的PDF檔案數量足夠多,那效果就會大不一樣了。
小結
讀過本文後,希望你已瞭解以下內容:
- 如何用Zotero匯入和管理PDF文獻;
- 如何用Zotero抓取PDF文獻的元資料;
- 如何將Zotero中的文獻集合資訊輸出給VosViewer等視覺化分析工具;
- 如何挖掘和準確定義使用者的需求;
- 如何結合不同的工具來綜合解決問題,嘗試滿足使用者需求。
與Zotero類似的文獻管理工具還有很多。Mendeley, Papers, ReadCube等工具都很優秀,也具備PDF元資訊獲取功能。我個人偏好Zotero,因為它小巧、強大,還免費。