
L1範數和L2範數的區別
正則化(Regularization)
機器學習中幾乎都可以看到損失函式後面會新增一個額外項,常用的額外項一般有兩種,一般英文稱作
L1正則化和L2正則化可以看做是損失函式的懲罰項。對於線性迴歸模型,使用L1正則化的模型建叫做Lasso迴歸,使用L2正則化的模型叫做Ridge迴歸(嶺迴歸)。下圖是Python中Lasso迴歸的損失函式,式中加號後面一項
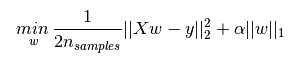
下圖是Python中Ridge迴歸的損失函式,式中加號後面一項
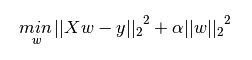
一般迴歸分析中迴歸
- L1正則化是指權值向量
w 中各個元素的絕對值之和,通常表示為||w||1 - L2正則化是指權值向量
w 中各個元素的平方和然後再求平方根(可以看到Ridge迴歸的L2正則化項有平方符號),通常表示為||w||2
一般都會在正則化項之前新增一個係數,Python中用
那新增L1和L2正則化有什麼用?下面是L1正則化和L2正則化的作用,這些表述可以在很多文章中找到。
- L1正則化可以產生稀疏權值矩陣,即產生一個稀疏模型,因此可以用於特徵選擇
- L2正則化可以防止模型過擬合(overfitting);一定程度上,L1也可以防止過擬合
稀疏模型與特徵選擇
上面提到L1正則化有助於生成一個稀疏權值矩陣,進而可以用於特徵選擇。為什麼要生成一個稀疏矩陣?
稀疏矩陣指的是很多元素為0,只有少數元素是非零值的矩陣,即得到的線性迴歸模型的大部分系數都是0. 通常機器學習中特徵數量很多,例如文字處理時,如果將一個片語(term)作為一個特徵,那麼特徵數量會達到上萬個(bigram)。在預測或分類時,那麼多特徵顯然難以選擇,但是如果代入這些特徵得到的模型是一個稀疏模型,表示只有少數特徵對這個模型有貢獻,絕大部分特徵是沒有貢獻的,或者貢獻微小(因為它們前面的係數是0或者是很小的值,即使去掉對模型也沒有什麼影響),此時我們就可以只關注係數是非零值的特徵。這就是稀疏模型與特徵選擇的關係。
L1和L2正則化的直觀理解
這部分內容將解釋為什麼L1正則化可以產生稀疏模型(L1是怎麼讓係數等於零的),以及為什麼L2正則化可以防止過擬合。
L1正則化和特徵選擇
假設有如下帶L1正則化的損失函式:
其中
相關推薦
L1範數和L2範數的區別
正則化(Regularization) 機器學習中幾乎都可以看到損失函式後面會新增一個額外項,常用的額外項一般有兩種,一般英文稱作ℓ1-norm和ℓ2-norm,中文稱作L1正則化和L2正則化,或者L1範數和L2範數。 L1正則化和L2正則化可以看做是損失
關於L0,L1和L2範數的規則化
本文主要整理一下機器學習中的範數規則化學習的內容: 規則化 -什麼是規則化 -為什麼要規則化 -規則化的理解 -怎麼規則化 -規則化的作用 範數 -L0範數和L1範數 -L2範數 -L1範數和L2範數 補充 -condition numbe
深度學習基礎--正則化與norm--L1範數與L2範數的聯絡
L1範數與L2範數的聯絡 假設需要求解的目標函式為:E(x) = f(x) + r(x) 其中f(x)為損失函式,用來評價模型訓練損失,必須是任意的可微凸函式,r(x)為規範化約束因子,用來對模型進行限制。 根據模型引數的概率分佈不同,r(x)一般有: 1)L1正規化
L1和L2範式
知識 tin gis res 學習 sdn 一個 們的 ssi 監督機器學習問題無非就是再規則化參數的同時最小化誤差。 *最小化誤差是為了讓我們的模型擬合我們的訓練數據,而規則化參數是防止我們的模型過分擬合我們的訓練數據 規則化參數的作用: *使得模型簡單,且具有好的
向量範數和矩陣範數
-m des ash comm pat 矩陣 status edi src 原文:https://www.zhihu.com/question/20473040以下分別列舉常用的向量範數和矩陣範數的定義。 向量範數 1-範數: ,即向
常見向量範數和矩陣範數
1、向量範數1-範數:,即向量元素絕對值之和,matlab呼叫函式norm(x, 1) 。2-範數:,Euclid範數(歐幾里得範數,常用計算向量長度),即向量元素絕對值的平方和再開方,matlab呼叫函式norm(x, 2)。∞-範數:,即所有向量元素絕對值中的最大值,ma
python全棧開發【補充】map函數和reduce函數的區別
lambda mage 多個 計算 兩個 數值 ima 所有 post ①從參數方面來講:map()函數: map()包含兩個參數,第一個是參數是一個函數,第二個是序列(列表或元組)。其中,函數(即map的第一個參數位置的函數)可以接收一個或多個參數。reduce()函數
C/C++之巨集、行內函數和普通函式的區別
轉載:https://www.cnblogs.com/ht-927/p/4726570.html C/C++之巨集、行內函數和普通函式的區別 行內函數的執行過程與帶引數巨集定義很相似,但引數的處理不同。帶引數的巨集定義並不對引數進行運算,而是直接替換;行內函數首先是函式,這就意味著函式的很多
回調函數和鉤子函數的區別
特殊性 監聽 define 因此 調用 消息 ntb 特殊 listener 在消息處理機制中必不可少的一組CP,即回調和鉤子。鉤子的概念源於Windows的消息處理機制,通過設置鉤子,應用程序可以對所有的消息事件進行攔截,然後執行鉤子函數,對消息進行想要的處理方式。接下來
面試---行內函數和巨集定義的區別
用行內函數取代巨集: 1.行內函數在執行時可除錯,而巨集定義不可以; 2.編譯器會對行內函數的引數型別做安全檢查或自動型別轉換(同普通函式),而巨集定 義則不會; 3.行內函數可以訪問類的成員變數,巨集定義則不能; 4.在類中宣告同時定義的成員函式,自
行內函數和巨集定義的區別和聯絡
深入到計算機的本質,其實,很多東西還是細節需要深入分析的,比如我最近的一份工作 行內函數和巨集很類似,都是以空間換時間,都能一定程度上加快程式的執行。而區別在於,巨集是由前處理器對巨集進行替代,而行內函數是通過編譯器控制來實現的。而且行內函數是真正的函式,只是在需要用到的時候,行內函數像巨集一樣的展
行內函數和巨集定義的區別
使用巨集和行內函數都可以節省在函式呼叫方面所帶來的時間和空間開銷。二者都採用了空間換時間的方式,在其呼叫處進行展開: (1) 在預編譯時期,巨集定義在呼叫處執行字串的原樣替換。在編譯時期,行內函數在
行內函數和預處理巨集區別
行內函數的功能和預處理巨集的功能相似。相信大家都用過預處理巨集,我們會經常定義一些巨集,如 #define TABLE_COMP(x) ((x)>0?(x):0) 就定義了一個巨集。 為什麼要使用巨集呢?因為函式的呼叫必須要將程式執行的順序轉移到函式 所存放
JS 中構造函數和普通函數的區別(詳)
.com 函數名 src func 普通 函數的調用 () inf size 1、構造函數也是一個普通函數,創建方式和普通函數一樣,但構造函數習慣上首字母大寫 2、構造函數和普通函數的區別在於:調用方式不一樣。作用也不一樣(構造函數用來新建實例對象)
Java - split()函數和trim()函數的使用方法
rac out api src ber div 使用 spa tro split()函數和trim()函數的使用方法 本文地址: http://blog.csdn.net/caroline_wendy/article/details/24465141 詳細參考J
oracle decode函數和 sign函數
mon 否則 dual lsi oracl 缺省值 符號 com oracle 流程控制函數 DECODE decode()函數簡介: 主要作用: 將查詢結果翻譯成其他值(即以其他形式表現出來,以下舉例說明); 使用方法: Select decode(columnname
strip()函數和 split()函數
字符串 erl syn nbsp 類型 lba ner ring ont 一:python strip()函數介紹 函數原型:strip可以刪除字符串的某些字符 聲明:s為字符串,rm為要刪除的字符序列 s.strip(rm) 刪除s字符串中開頭、結尾處,位於
C語言itoa()函數和atoi()函數詳解(整數轉字符C實現)
獲取 c++語言 end atof 定位 ray iostream 寫入 blog C語言提供了幾個標準庫函數,可以將任意類型(整型、長整型、浮點型等)的數字轉換為字符串。 1.int/float to string/array: C語言提供了幾個標準庫函數,可以將任意類型
構析函數和構造函數
顯式 生成 它的 構造函數 函數名 類型 標識 不能 調用 一、構造函數的介紹 1. 構造函數的作用 構造函數主要用來在創建對象時完成對對象屬性的一些初始化等操作, 當創建對象時, 對象會自動調用它的構造函數。一般來說, 構造函數有以下三個方面的作用:
python函數(6):內置函數和匿名函數
a20 *args -s 執行 code str 思維導圖 inpu 其他 我們學了這麽多關於函數的知識基本都是自己定義自己使用,那麽我們之前用的一些函數並不是我們自己定義的比如說print(),len(),type()等等,它們是哪來的呢? 一、內置函數 由pytho