
Stanford 機器學習筆記 Week8 Dimensionality Reduction
Motivation
Motivation I: Data Compression
降維可以做資料壓縮,減少冗餘資訊從而減小儲存空間。
2D向1D降維:
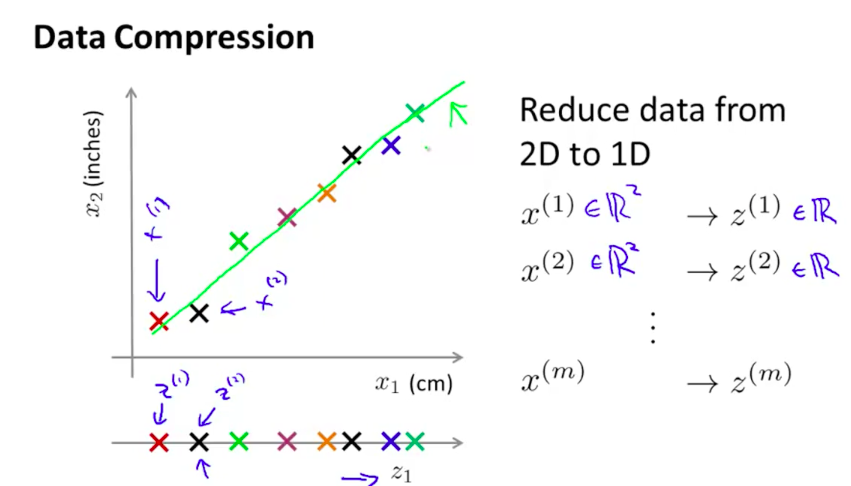
cm 和 inches都表示長度,屬於冗餘資訊,可以用z向量做新的維度,用1維就可以表示長度。
3D向2D降維:
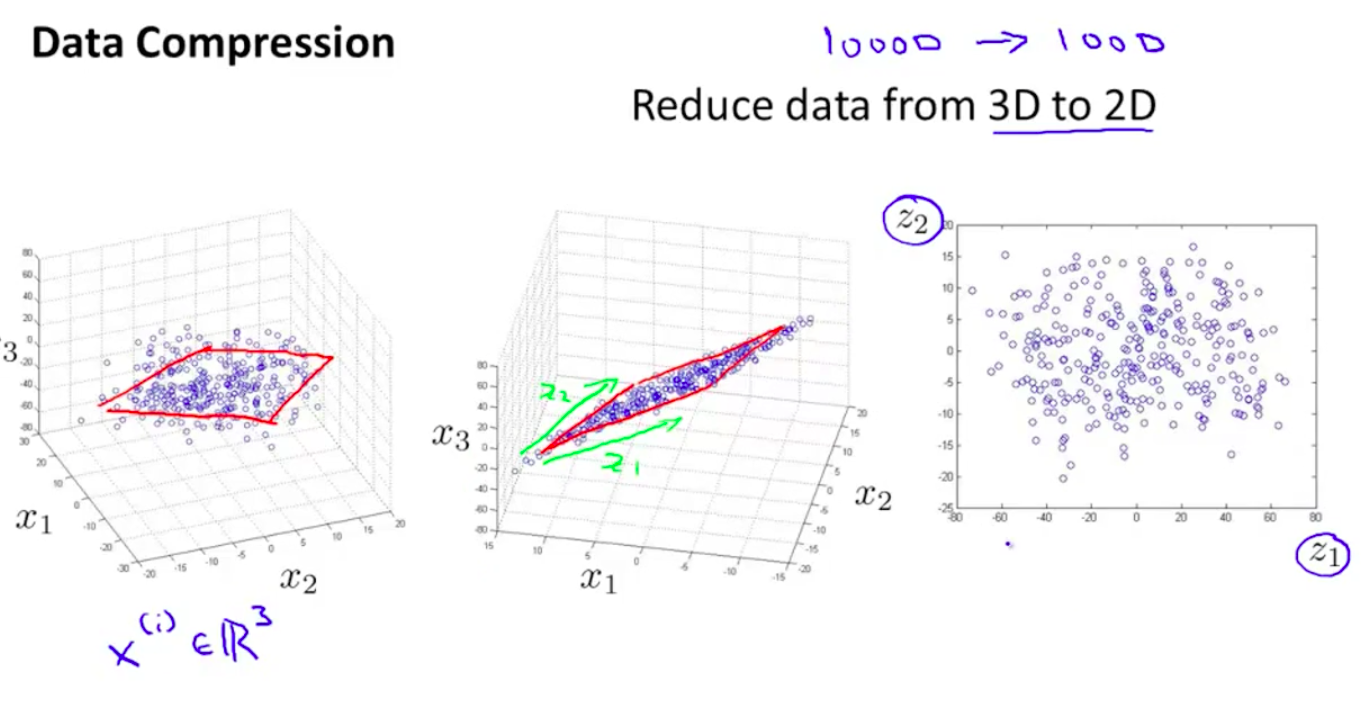
在左側的原始資料中,所有點都接近一個平面,這說明存在冗餘維度。將所有點投影到該平面形成中間圖。用向量z1,z2做新的維度,降到2維。
Motivation II: Visualization
降維還可以用於視覺化。
因為人類能理解的只有2維或3維影象,因此如果能把資料集降到<=3維的情況,就可以繪出人能理解的影象。
在這種情況下,每個維度沒有具體的意義,它的意義是多個正相關屬性共同決定的。
Principal Component Analysis
Principal Component Analysis Problem Formulation
projection error指的是原training set的每個點到降維後投影的點的距離之和。
主成分分析(PCA)的定義就是:
將高維資料降為K維資料時,找到K個向量(構成K維),使得training set到這個K維平面的projection error最小。
對於2D to 1D問題,就是找一條直線使得資料集中每個點到該直線距離之和最小。
注意這和linear regression是不一樣的:
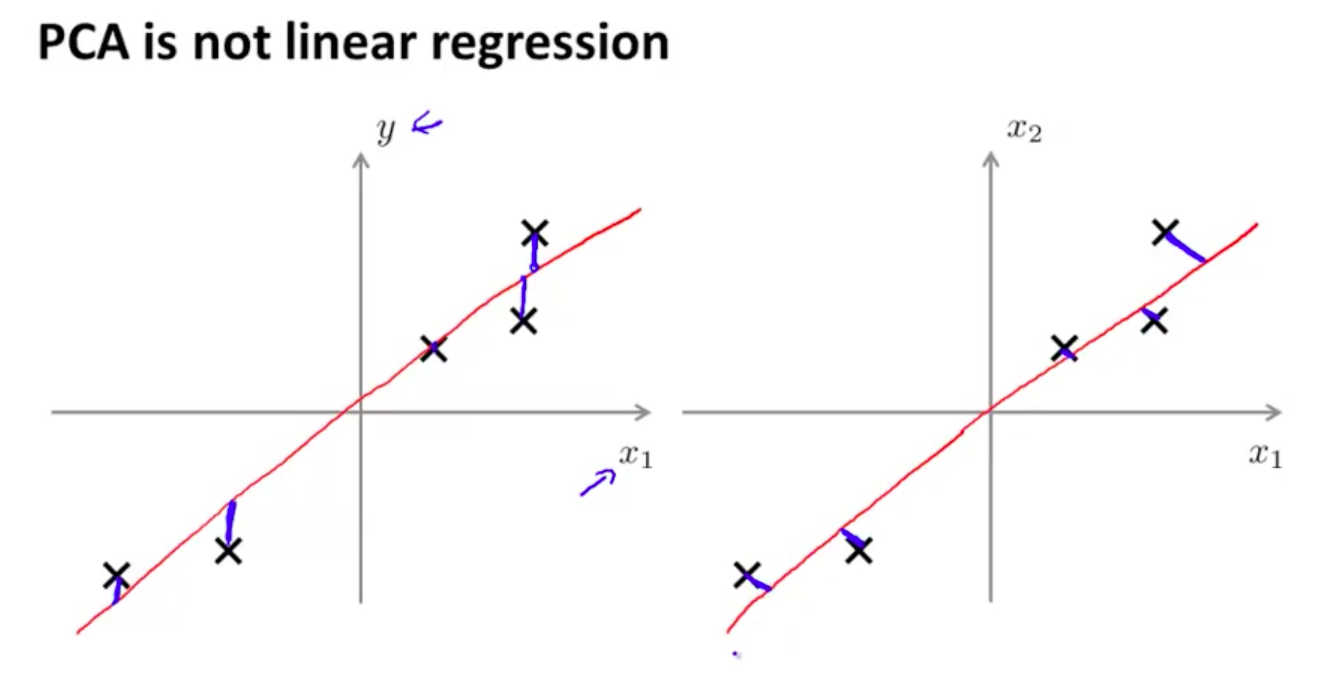
左圖是Linear Regression,每個點的cost是該點按y軸方向到直線的距離。而右圖PCA就是點到直線的距離。
Principal Component Analysis Algorithm
PCA演算法步驟:
1.做歸一化:
x(i)j = (x(i)j - uj)/sj
其中x(i)j是第i個數據的第j個屬性值,uj是所有資料第j個屬性的平均值,sj表示資料離散情況,可以用所有資料第j個屬性的max-min或標準差。
2.計算covariance(共變)矩陣sigma
3.對sigma做奇異值分解(SVD)

SVD得到3個矩陣,我們使用第一個矩陣U,這也是一個n*n的矩陣。
這一步的意義:
轉自http://blog.csdn.net/abcjennifer/article/details/7758797:
在matlab中有函式[U,S,V] = svd(A) 返回一個與A同大小的對角矩陣S(由Σ的特徵值組成),兩個酉矩陣U和V,且滿足Σ= U*S*V’。若A為m×n陣,則U為m×m陣,V為n×n陣。奇異值在S的對角線上,非負且按降序排列。
那麼對於方陣Σ呢,就有
Σ = USV’
ΣΣ’ = USV’*VS’U’ = U(ΣΣ’)U’
Σ’Σ = VS’U’*USV’ = V(Σ’Σ)V’
i.e. U是ΣΣ’的特徵向量矩陣;V是Σ’Σ的特徵向量矩陣,都是n*n的矩陣
由於方陣的SVD相當於特徵值分解,所以事實上U = V, 即Σ = USU’, U是特徵向量組成的正交矩陣
我們的目的是,從n維降維到k維,也就是選出這n個特徵中最重要的k個,也就是選出特徵值最大的k個
4.因為SVD後S對角矩陣已經是按特徵值排過序的了,因此U的前k個特徵向量就是最重要的k個,將它們截取出來得到Ureduce
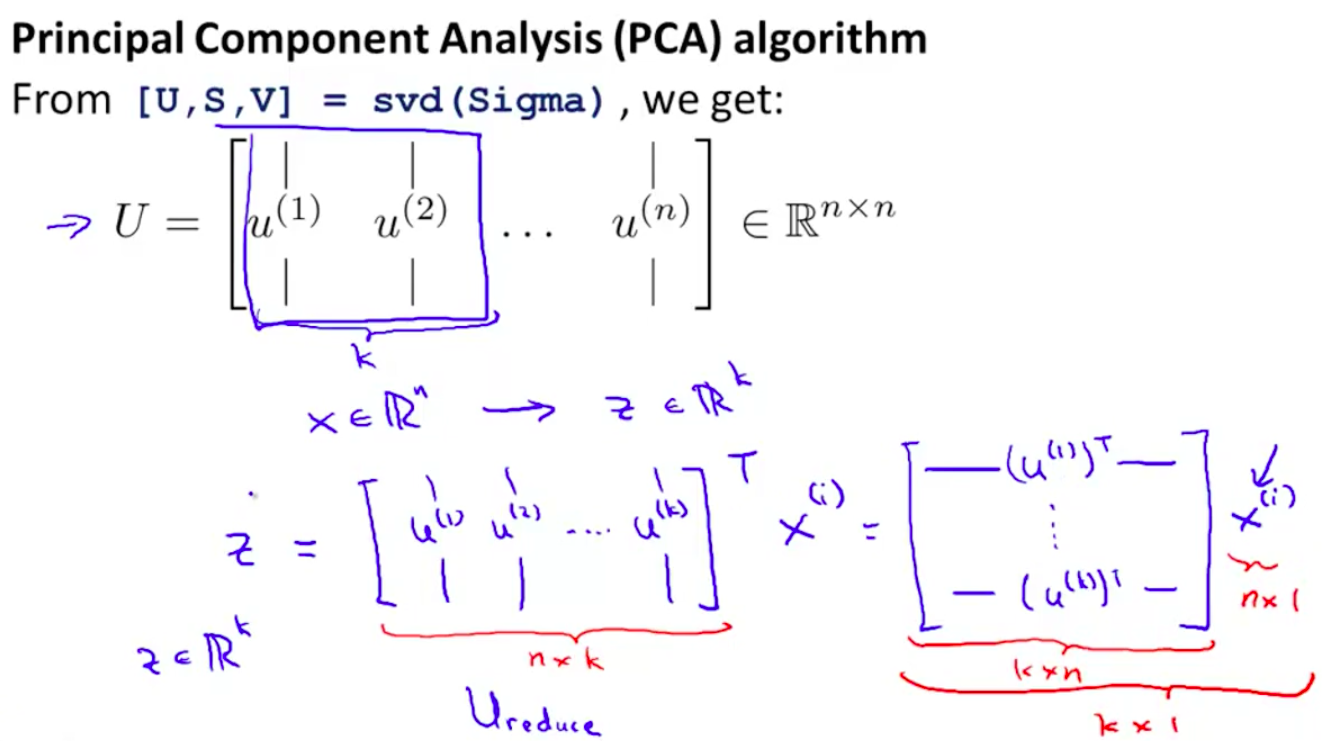
之後如果我們想把一個n維向量x(i)轉成k維向量,就用Ureduce(T) * x(i)就完成了降維。
Applying PCA
Reconstruction from Compressed Representation
把降維後的向量還原回去的方法很簡單,上一節已經求出Ureduce了,直接用Ureduce*降維後向量就還原了Xapprox(i),這個值接近於原x(i)。
Chosing the Number of Principle Components
如何選擇K使得可以儘可能降到一個很低的維度同時不丟失太多資訊?
如下圖,提出兩個定義:

如果滿足這個性質就說明99%的資訊都沒丟失。
可以通過從小到大列舉K,計算上面的公式,令K等於第一個滿足上面條件的值。

如上圖,需要check的公式可以變換為另一個公式(右側),該公式僅使用SVD後計算出的S矩陣中的特徵值。
Advice for Applying PCA
PCA可以用來加速機器學習演算法。因為降維之後資料集大小減小,這可以顯著減少演算法執行時間。
不要用PCA來防止過擬合
因為PCA減少了屬性的數量,一定程度可以減小過擬合。但是PCA付出的代價是丟失資訊,即使丟失的很少這也是沒必要的,因為使用regularization可以保證100%不丟失資訊。
僅當演算法在原資料集上的執行時間或儲存空間無法實現,再採用PCA,不要開始就使用PCA