
挖掘建模-分類與預測-迴歸分析-邏輯迴歸
阿新 • • 發佈:2019-02-14
利用Scikit-Learn對以下資料集進行邏輯迴歸分析。首先進行特徵篩選,特徵篩選的方法很多,主要包含在Scikit-Learn的feature-selection庫中,比較簡單的有通過F檢驗(f_regression)來給出各個特徵的F值和p值,從而可以篩選變數(選擇F值大的或者p值小的特徵)。其次有遞迴特徵消除(Recursive Feature Elimination, RFE)和穩定性選擇(Stability Selection)等比較新的方法。這裡使用了穩定性選擇方法中的隨機邏輯迴歸進行特徵篩選,然後利用篩選後的特徵建立邏輯迴歸模型,輸出平均正確率,程式碼如下:
程式碼來源: Python資料分析與挖掘實戰
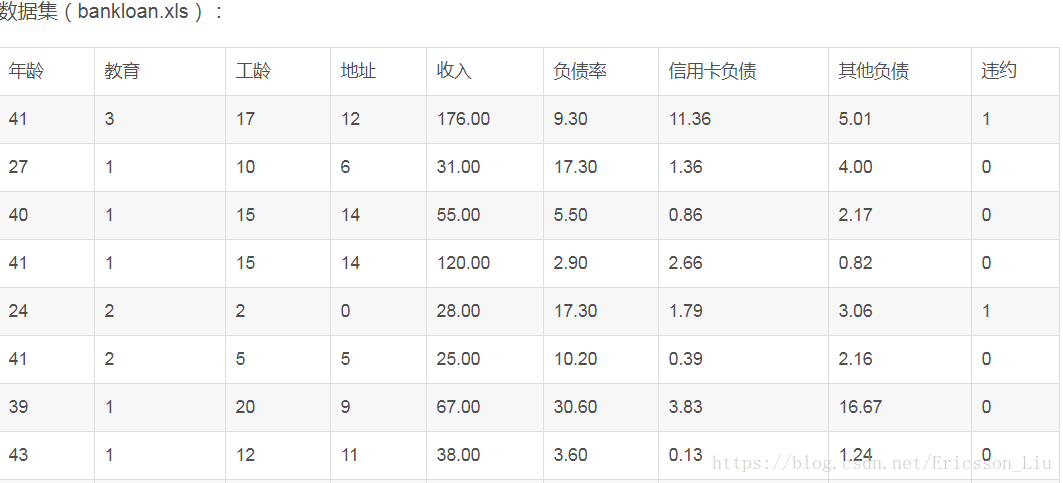
#-*- coding: utf-8 -*- import pandas as pd import numpy as np from sklearn.linear_model import LogisticRegression as LR from sklearn.linear_model import RandomizedLogisticRegression as RLR filename = '../data/bankloan.xls' data = pd.read_excel(filename) x = data.iloc[:,:8].as_matrix() #自變數;data.iloc[:,:8]取除違約列的資料,官方文件說明as_matrix()方法將會在pandas 0.23.0開始被values()代替,as_matrix()這裡將所有記錄轉換為陣列表示 y = data.iloc[:,8].as_matrix() #data[:,8]只取違約列的資料; y在這裡做為邏輯迴歸的因變數,取值只能為0,1 rlr = RLR() #建立隨機邏輯迴歸模型,篩選變數 rlr.fit(x, y) #訓練模型 rlr.get_support(indices=True) #獲取特徵篩選結果:返回為True的索引[2 3 5 6];也可以用.score_方法獲取各個特徵的分數 print(u'通過隨機邏輯迴歸模型篩選特徵結束') print(u'有效特徵為: %s' % ','.join(data.columns[rlr.get_support(indices=True)])) #','.join(...)表示後面的各個元素以逗號分割, data.columns: Index([u'年齡', u'教育', u'工齡', u'地址', u'收入', u'負債率', u'信用卡負債', u'其他負債', u'違約'], dtype='object') x = data[data.columns[rlr.get_support(indices=True)]].as_matrix() #篩選好特徵 lr = LR() #建立邏輯貨櫃模型 lr.fit(x, y) #用篩選後的特徵資料來訓練模型 print(u'邏輯迴歸模型訓練結束。') print(u'模型的平均正確率為: %s' % lr.score(x, y)) #給出模型的平均正確率,本例為81.4%
返回值:
通過隨機邏輯迴歸模型篩選特徵結束
有效特徵為: 工齡,地址,負債率,信用卡負債
邏輯迴歸模型訓練結束。
模型的平均正確率為: 0.8142857142857143