機器學習之決策樹演算法python實現
阿新 • • 發佈:2019-02-16
一. 理論基礎
1. 特徵選擇
a. 資訊熵
b. 條件熵
c. 資訊增益
d. 資訊增益比
以資訊增益作為劃分訓練資料集的特徵,存在偏向於選擇取值較多的特徵的問題,使用資訊增益比可以對這一問題進行校正。
其中,
n是特徵A取值的個數.
2. 決策樹的生成
ID3演算法是用資訊增益進行特徵的選擇,C4.5演算法使用資訊增益比來進行特徵的選擇。
3. 決策樹的剪枝
決策樹生成演算法容易出現過擬合現象, 將已生成的樹進行簡化的過程稱為剪枝。決策樹的剪枝往往通過極小化決策樹整體的損失函式來實現。
設樹T的葉結點個數為|T|,t是樹T的葉結點,該葉結點有
其中經驗熵為:
這時損失函式可以寫為
決策樹生成學習區域性的模型,決策樹剪枝學習整體的模型。
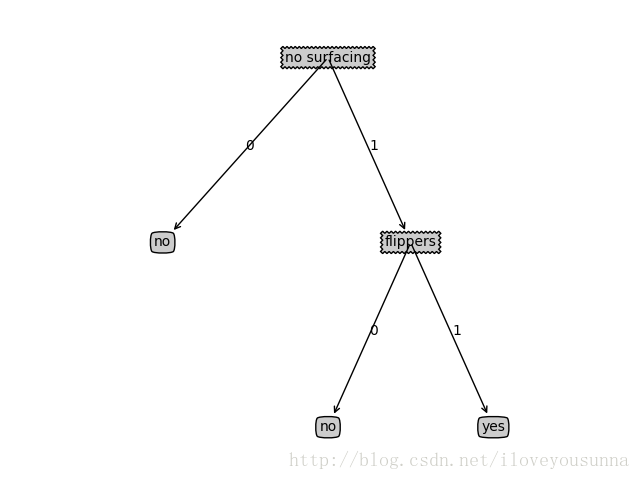
二. python實現
1. 程式碼
DecisionTreeClassifier.py
#encoding=utf-8
'''
implement tree algorithm
'''
from math import log
import matplotlib.pyplot as plt
class DecisionTreeClassifier:
'''
implement decision tree classifier
'''
def __init__(self):
pass
def create_dataset(self):
'''
create the dataset
'''