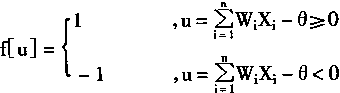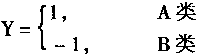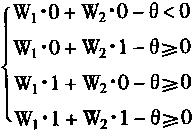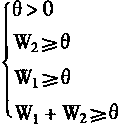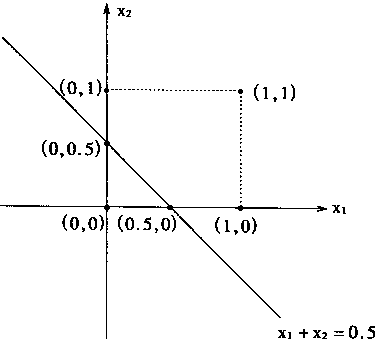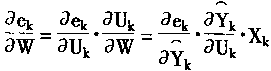BP演算法的推導(注意殘差的定義)
|
反向傳播BP模型 |
|||||||
|
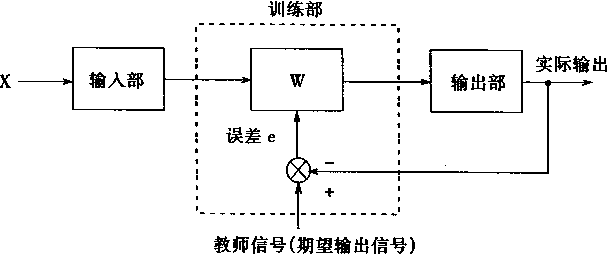
學習是神經網路一種最重要也最令人注目的特點。在神經網路的發展程序中,學習演算法的研究有著十分重要的地位。目前,人們所提出的神經網路模型都是和學習演算法相應的。所以,有時人們並不去祈求對模型和演算法進行嚴格的定義或區分。有的模型可以有多種演算法.而有的演算法可能可用於多種模型。不過,有時人們也稱演算法 為模型。 自從40年代Hebb提出的學習規則以來,人們相繼提出了各種各樣的學習演算法。其中以在1986年Rumelhart等提出的誤差反向傳播法,即BP(error BackPropagation)法影響最為廣泛。直到今天,BP演算法仍然是自動控制上最重要、應用最多的有效演算法。 1.2.1 神經網路的學習機理和機構 在神經網路中,對外部環境提供的模式樣本進行學習訓練,並能儲存這種模式,則稱為感知器;對外部環境有適應能力,能自動提取外部環境變化特徵,則稱為認知器。 神經網路在學習中,一般分為有教師和無教師(有監督和無監督)學習兩種。感知器採用有教師訊號進行學習,而認知器則採用無教師訊號學習的。在主要神經網路如BP網路,Hopfield網路,ART網路和Kohonen網路中;BP網路和Hopfield網路是需要教師訊號才能進行學習的;而ART網路和 Kohonen網路則無需教師訊號就可以學習。所謂教師訊號,就是在神經網路學習中由外部提供的模式樣本訊號。 一、感知器的學習結構 感知器的學習是神經網路最典型的學習。 目前,在控制上應用的是多層前饋網路,這是一種感知器模型,學習演算法是BP法,故是有教師學習演算法。 一個有教師的學習系統可以用圖1—7表示。這種學習系統分成三個部分:輸入部,訓練部和輸出部。
|
|||||||
|
圖1-7 神經網路學習系統框圖 |
|||||||
|
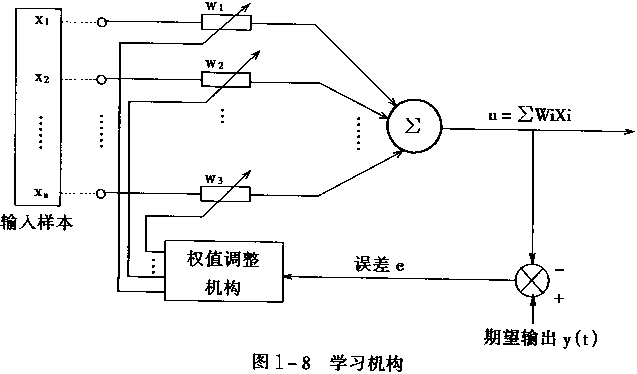
輸入部接收外來的輸入樣本X,由訓練部進行網路的權係數W調整,然後由輸出部輸出結果。在這個過程中,期望的輸出訊號可以作為教師訊號輸入,由該教師訊號與實際輸出進行比較,產生的誤差去控制修改權係數W。 學習機構可用圖1—8所示的結構表示。 在圖中,Xl ,X2 ,…,Xn ,是輸入樣本訊號,W1 ,W2 ,…,Wn 是權係數。輸入樣本訊號Xi u=∑Wi Xi =W1 X1 +W2 X2 +…+Wn Xn 再把期望輸出訊號Y(t)和u進行比較,從而產生誤差訊號e。權值調整機構根據誤差e去對學習系統的權係數進行修改,修改方向應使誤差e變小,不斷進行下去,使到誤差e為零,這時實際輸出值u和期望輸出值Y(t)完全一樣,則學習過程結束。
|
|||||||
|
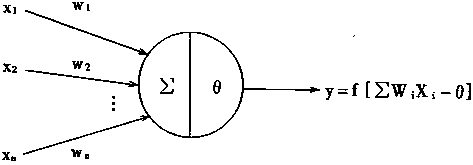
神經網路的學習一般需要多次重複訓練,使誤差值逐漸向零趨近,最後到達零。則這時才會使輸出與期望一致。故而神經網路的學習是消耗一定時期的,有的學習過程要重複很多次,甚至達萬次級。原因在於神經網路的權係數W有很多分量W1 ,W2,----Wn ;也即是一個多引數修改系統。系統的引數的調整就必定耗時耗量。目前,提高神經網路的學習速度,減少學習重複次數是十分重要的研究課題,也是實時控制中的關鍵問題。 二、感知器的學習演算法 感知器是有單層計算單元的神經網路,由線性元件及閥值元件組成。感知器如圖1-9所示。
|
|||||||
|
圖1-9 感知器結構 感知器的數學模型:
|
|||||||
|
其中:f[.]是階躍函式,並且有
|
|||||||
|
θ是閥值。 感知器的最大作用就是可以對輸入的樣本分類,故它可作分類器,感知器對輸入訊號的分類如下:
|
|||||||
|
即是,當感知器的輸出為1時,輸入樣本稱為A類;輸出為-1時,輸入樣本稱為B類。從上可知感知器的分類邊界是:
|
|||||||
|
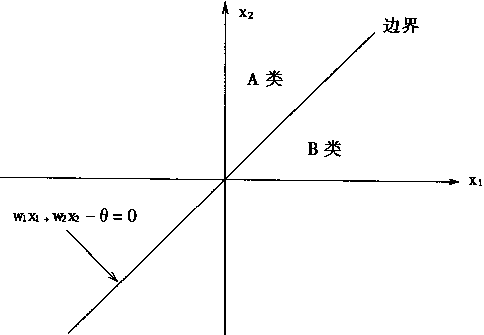
在輸入樣本只有兩個分量X1,X2時,則有分類邊界條件:
|
|||||||
|
即 W1 X1 +W2 X2 -θ=0 (1-17) 也可寫成
|
|||||||
|
這時的分類情況如圖1—10所示。 感知器的學習演算法目的在於找尋恰當的權係數w=(w1.w2,…,Wn),使系統對一個特 定的樣本x=(xt,x2,…,xn)能產生期望值d。當x分類為A類時,期望值d=1;X為B類 時,d=-1。為了方便說明感知器學習演算法,把閥值θ併入權係數w中,同時,樣本x也相應增加一 個分量xn+1 。故令: Wn+1 =-θ,Xn+1 =1 (1-19) 則感知器的輸出可表示為:
|
|||||||
|
感知器學習演算法步驟如下:
|
|||||||
|
圖1-10 感知器的分類例子 |
|||||||
|
2.輸入一樣本X=(X1 ,X2 ,…,Xn+1 )以及它的期望輸出d。 期望輸出值d在樣本的類屬不同時取值不同。如果x是A類,則取d=1,如果x是B類,則取-1。期望輸出d也即是教師訊號。 3.計算實際輸出值Y
4.根據實際輸出求誤差e e=d—Y(t) (1-21) 5.用誤差e去修改權係數
i=1,2,…,n,n+1 (1-22) 其中,η稱為權重變化率,0<η≤1 在式(1—22)中,η的取值不能太大.如果1取值太大則會影響wi (t)的穩定;的取值也不能太小,太小則會使Wi (t)的求取過程收斂速度太慢。 當實際輸出和期望值d相同時有: Wi (t+1)=Wi (t) 6.轉到第2點,一直執行到一切樣本均穩定為止。 從上面式(1—14)可知,感知器實質是一個分類器,它的這種分類是和二值邏輯相應的。因此,感知器可以用於實現邏輯函式。下面對感知器實現邏輯函式的情況作一些介紹。 例:用感知器實現邏輯函式X1 VX2 的真值:
|
|||||||
|
以X1VX2=1為A類,以X1VX2=0為B類,則有方程組
|
|||||||
即有:
|
|||||||
|
從式(1—24)有: W1 ≥θ,W2 ≥θ 令 W1 =1,W2 =2 則有: θ ≤1 取 θ=0.5 則有:X1+X2-0.5=0,分類情況如圖1—11所示。
|
|||||||
|
圖1-11 邏輯函式X1 VX2 的分類 1.2.2 神經網路學習的梯度演算法 從感如器的學習演算法可知,學習的目的是在於修改網路中的權係數,使到網路對於所輸入的模式樣本能正確分類。當學習結束時,也即神經網路能正確分類時,顯然 權係數就反映了同類輸人模式樣本的共同特徵。換句話講,權係數就是儲存了的輸入模式。由於權係數是分散存在的,故神經網路自然而然就有分佈儲存的特點。 前面的感知器的傳遞函式是階躍函式,所以,它可以用作分類器。前面一節所講的感知器學習演算法因其傳遞函式的簡單而存在侷限性。 感知器學習演算法相當簡單,並且當函式線性可分時保證收斂。但它也存在問題:即函式不是線性可分時,則求不出結果;另外,不能推廣到一般前饋網路中。 為了克服存在的問題,所以人們提出另一種演算法——梯度演算法(也即是LMS(最小均方誤差)法)。 為了能實現梯度演算法,故把神經元的激發函式改為可微分函式,例如Sigmoid函式,非對稱Sigmoid函式為f(X)=1/(1+e-x ),導數f(x)*(1-f(x))對稱Sigmoid函式f(X)=(1-e-x )/(1+e-x );而不採用式(1—13)的階躍函式。 對於給定的樣本集Xi (i=1,2,,n),梯度法的目的是尋找權係數W* ,使得f[W*. Xi ]與期望輸出Yi儘可能接近。 設誤差e採用下式表示:
|
|||||||
|
其中,Yi ^=f〔W* ·Xi ]是對應第i個樣本Xi 的實時輸出 Yi 是對應第i個樣本Xi 的期望輸出。 要使誤差e最小,可先求取e的梯度:
|
|||||||
|
|||||||
|
令 Uk =W. Xk ,則有:
|
|||||||
|
即有:
|
|||||||
|
最後有按負梯度方向修改權係數W的修改規則:
|
|||||||
|
也可寫成:
|
|||||||
|
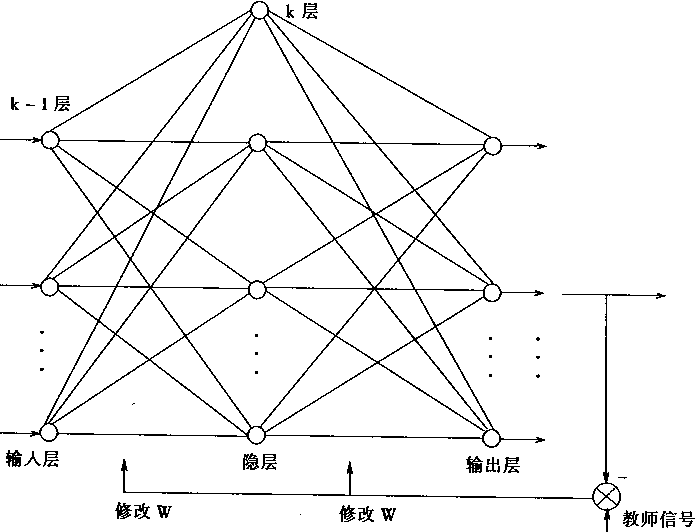
在上式(1—30),式(1—31)中,μ 是權重變化率,它視情況不同而取值不同,一般取0-1之間的小數。 1.神經元的傳遞函式採用連續的s型函式,容易求導,而不是階躍函式; 2.對權係數的修改採用誤差的梯度去控制,而不是採用誤差去控制。故而有更好的動態特能,即加強了收斂程序。 但是梯度法對於實際學習來說,仍然是感覺太慢;所以,這種演算法仍然是不理想的。 1.2.3 反向傳播學習的BP演算法 反向傳播演算法也稱BP演算法。由於這種演算法在本質上是一種神經網路學習的數學模型,所以,有時也稱為BP模型。 BP演算法是為了解決多層前向神經網路的權係數優化而提出來的;所以,BP演算法也通常暗示著神經網路的拓撲結構是一種無反饋的多層前向網路。故而.有時也稱無反饋多層前向網路為BP模型。 在這裡,並不要求過於嚴格去爭論和區分演算法和模型兩者的有關異同。感知機學習演算法是一種單層網路的學習演算法。在多層網路中.它只能改變最後權係數。因此, 感知機學習演算法不能用於多層神經網路的學習。1986年,Rumelhart提出了反向傳播學習演算法,即BP(backpropagation)演算法。這 種演算法可以對網路中各層的權係數進行修正,故適用於多層網路的學習。BP演算法是目前最廣泛用的神經網路學習演算法之一,在自動控制中是最有用的學習演算法。 一、BP演算法的原理 BP演算法是用於前饋多層網路的學習演算法,前饋多層網路的結構一般如圖1—12所示
|
|||||||
|
圖1-12 網路學習結構 它含有輸人層、輸出層以及處於輸入輸出層之間的中間層。中間層有單層或多層,由於它們和外界沒有直接的聯絡,故也稱為隱層。在隱層中的神經元也稱隱單元。 隱層雖然和外界不連線.但是,它們的狀態則影響輸入輸出之間的關係。這也是說,改變隱層的權係數,可以改變整個多層神經網路的效能。 |
|||||||
|
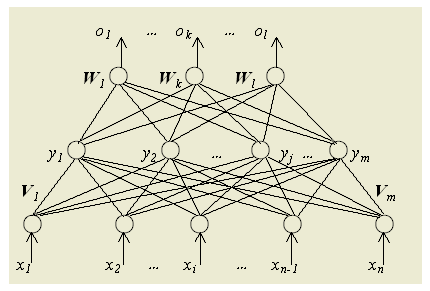
1.正向傳播 輸入的樣本從輸入層經過隱單元一層一層進行處理,通過所有的隱層之後,則傳向輸出層;在逐層處理的過程中,每一層神經元的狀態只對下一層神經元的狀態產生影響。在輸出層把現行輸出和期望輸出進行比較,如果現行輸出不等於期望輸出,則進入反向傳播過程。 2.反向傳播 反向傳播時,把誤差訊號按原來正向傳播的通路反向傳回,並對每個隱層的各個神經元的權係數進行修改,以望誤差訊號趨向最小。 二、BP演算法的數學表達 一. 網路結構經典的BP網路,其具體結構如下:
請特別注意上面這個圖的一些符號說明如下:
二. 學習演算法1. 訊號的前向傳遞過程 請特別注意上述公式中的下標,這裡,權值矩陣包含了神經元節點本身的偏置,所以權值矩陣多了一列。
2. 誤差反向傳導過程
請特別注意上述公式中的下標,這裡,權值矩陣包含了神經元節點本身的偏置,所以權值矩陣多了一列。
2. 誤差反向傳導過程


     三. 小結訊號的前向傳遞和誤差反向傳遞過程都可以用遞迴公式描述。其實,就幾個公式而已,把相關的幾個重要公式再次總結如下: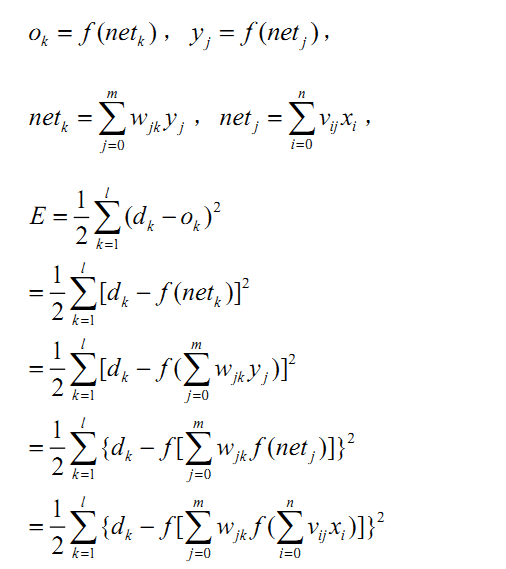
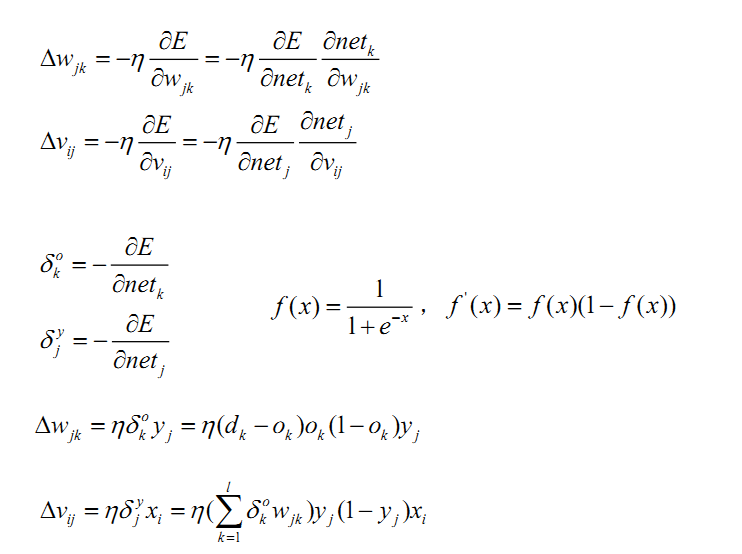 |