
BP演算法推導
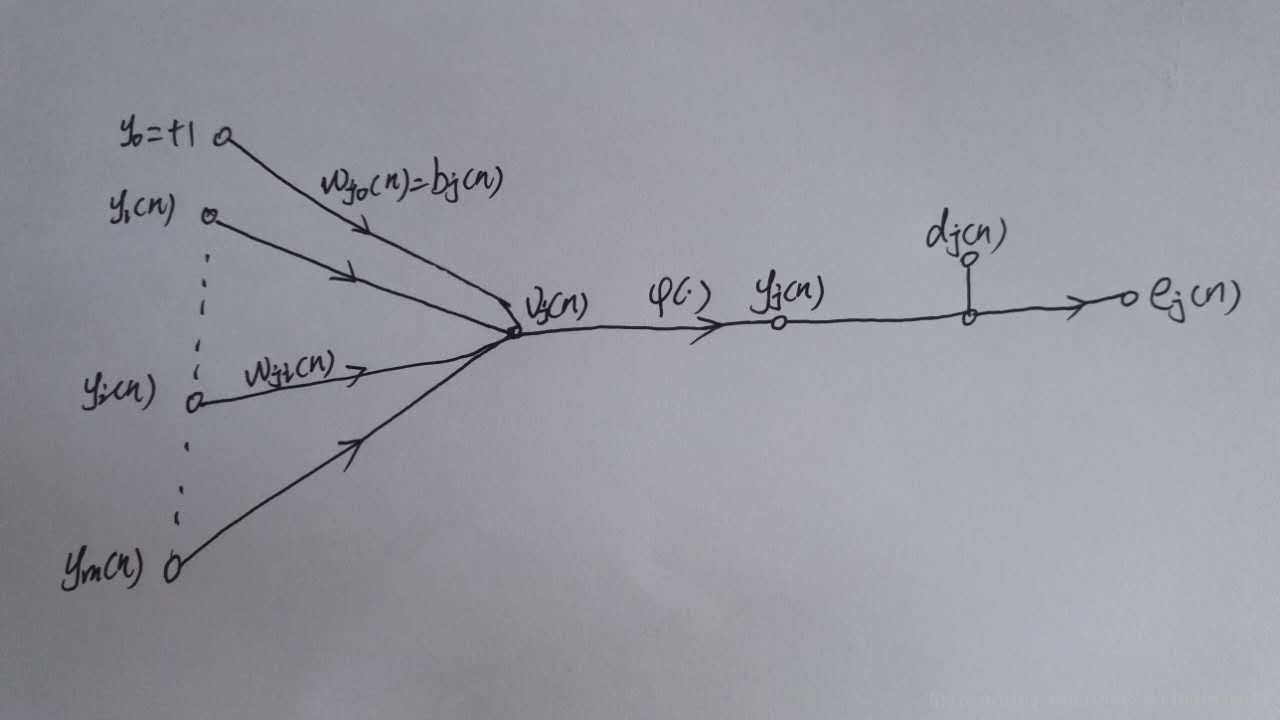
輸出層梯度求解過程
如上圖所示,為一個輸出層神經元,在計算輸出層梯度的時候,我們不用去考慮前一層是如何輸入的。所以我們用y來表示,圖中的y(n)表示第n個樣本在前一層的輸出值,這一層的輸入值。我們將當前節點定義為j。那麼當前節點j的輸入值之和為 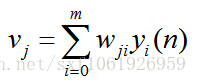
這裡的m是節點j前一層的輸入節點的個數,其中包括一個偏置項b。這裡的公式都很像,看公式注意下標。然後節點j的輸出要經過啟用函式,如圖所示我們定義啟用函式為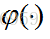
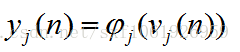
圖中還有一個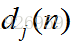
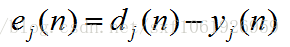
然後為計算梯度,我們需要有一個損失函式,因為反傳其實就是在求損失函式對權值的梯度。
我們這裡使用平方誤差作為損失函式,所以損失函式為
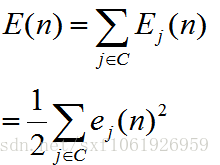
這裡的C為全部的輸出層神經節點
好了,把前提說清楚了,就可以開始求梯度了
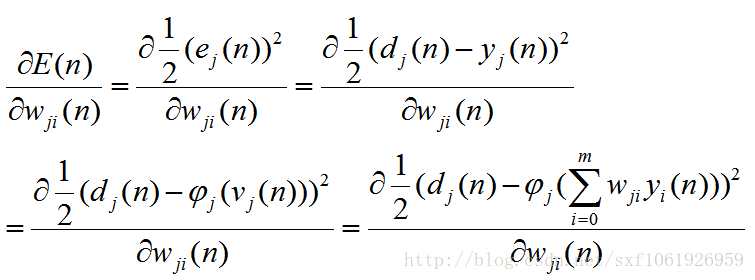
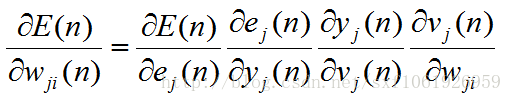 這樣拆分開計算的原理是:鏈式法則。然後我們按照上面的一個個把梯度求出來,在最後去把他們乘起來。
這樣拆分開計算的原理是:鏈式法則。然後我們按照上面的一個個把梯度求出來,在最後去把他們乘起來。 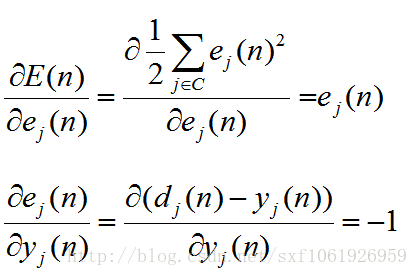
繼續
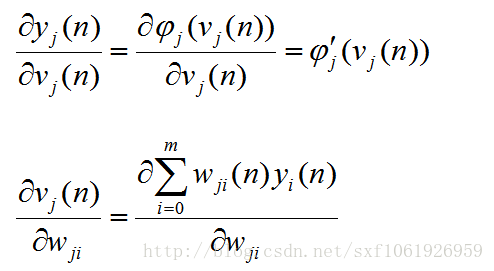
這裡注意下,分子上的求和符號展開後,除了含有
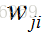 的哪項外,其他所求的導數都為0,,因為對當前權值來說,他們都是常數,常數的導數為0.所以我們能得到 (這裡隱含層和輸出層是有點不一樣的...)
的哪項外,其他所求的導數都為0,,因為對當前權值來說,他們都是常數,常數的導數為0.所以我們能得到 (這裡隱含層和輸出層是有點不一樣的...)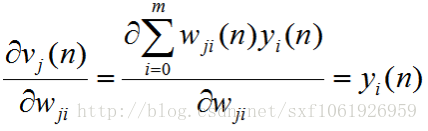
現在把這些都放回原來的公式去
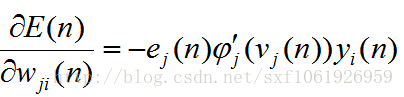
可以看出來,當前求的梯度和前一層的輸入直接相關。一旦有了梯度,我們要做的就是用這個梯度去更新權值,當然不能直接減,太大了,所以加入一個步長
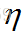 ,得到
,得到 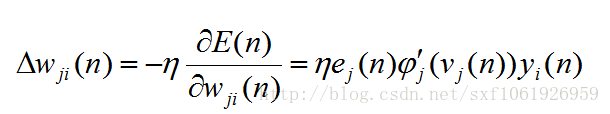
最後更新權值
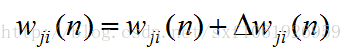
這裡要注意,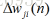
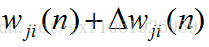
隱藏層梯度計算
前面計算了輸出層的梯度更新,這裡我們要計算隱藏層。
之所以輸出層和隱藏層要分開計算,那是因為隱藏層更加複雜,可以想象一下,隱藏層的節點,會連線下一層的所有節點,那麼在梯度反傳的時候也要從這些連線的節點去獲取梯度。所以隱藏層就不能只求一個節點的梯度了,但是原理還是一樣的,也是求損失函式對當前權值的梯度,只是計算過程變得比前面一個複雜了一點點。
這裡我重新畫了兩個節點,左邊這個表示隱藏層節點j,右邊那個表示輸出層節點k,我們剛才計算的就是右邊那個,現在我們來計算前面這個。
別看我這裡只畫了一個輸出層節點k,但是真實情況不一定只有一個,如果有多個,那麼當前的節點j一定會和其有連結,那麼和其連線的節點就會有梯度反傳。
所以需要重新計算梯度,和輸出層不同的是,輸出層只需要去考慮一個輸出神經元的損失,而隱藏層需要去考慮全部全部輸出層節點的損失,如下
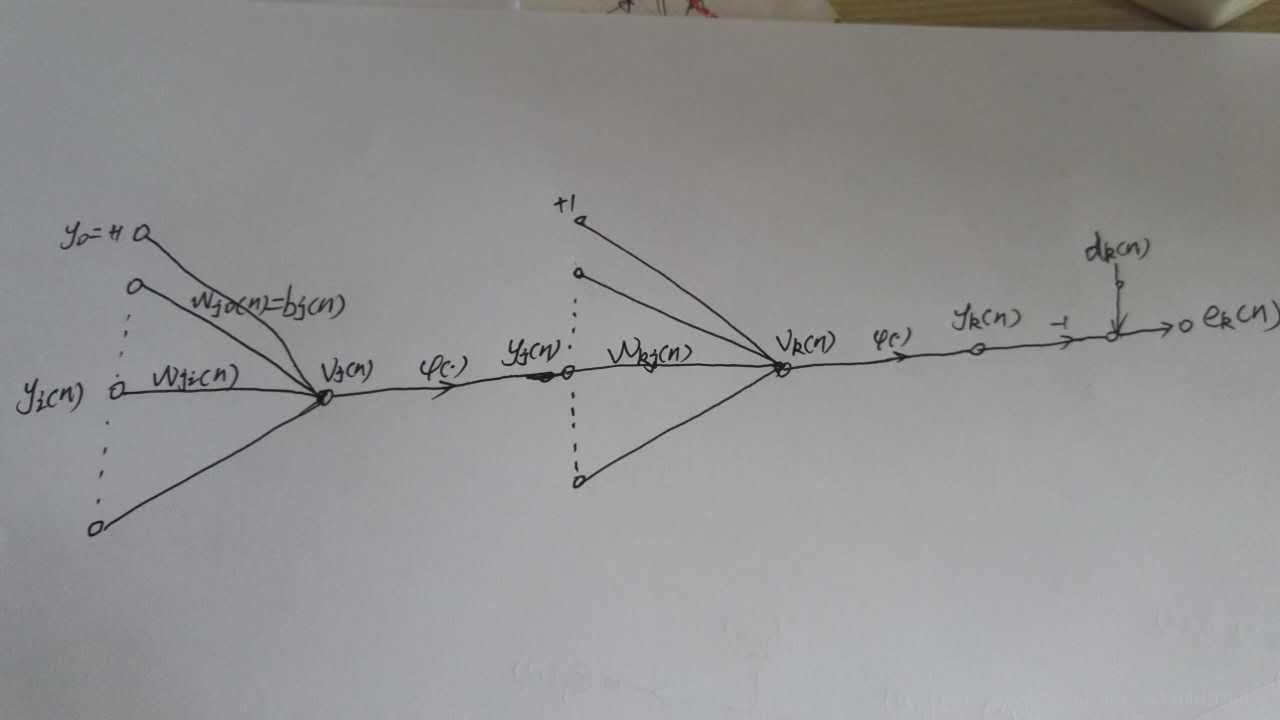
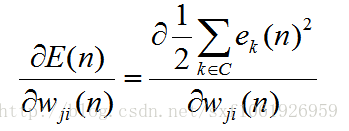
在求輸出層的時候,因為權值只和其中的一個e有關,所以上面的累加展開後,只有一項為非零,其他全是0。但是在這裡,隱藏層和上面的每個節點都要連線,所以我們這裡要對全部的e求導。
得到
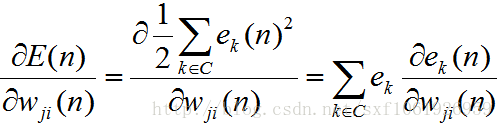
然後後面的就是差不多的了,一直求梯度求下去、
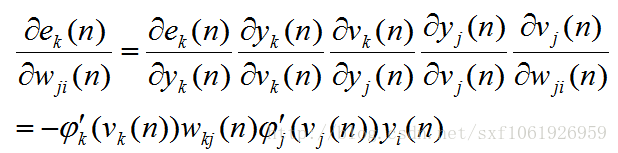
這裡我直接寫出來了,步驟和前面的差不多,自己試著推導下就知道了
我們直接得到最終的梯度更新
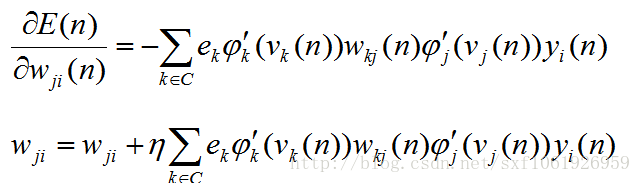
到這裡,梯度更新的推導算是結束了,根據以上公式可以推匯出任何一個權值的梯度
然後我們可以看看這些梯度之間有那些共同點,我把前面推導好的輸出層和隱藏層梯度拿下來,如下
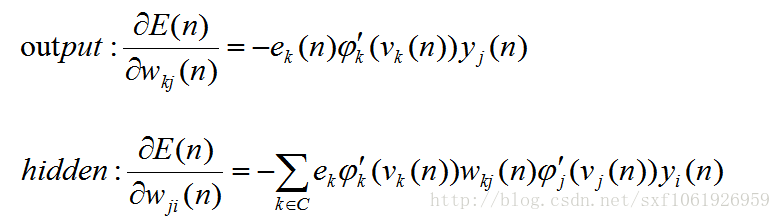
可以發現,每個公式中,最後一項都是所求權值的輸入值,導數第二項都是啟用函式的導數值,剩下的為傳下來的損失。所以在演算法實現的時候,往往把前面的損失值和啟用函式導數的乘積當作一項整體,這樣就可以實現鏈式計算,方便程式碼實現。我們把他叫做區域性梯度
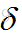 ,如上面兩個公式可以改成如下式子(下標kj的是輸出層的,下標ji的是隱藏層的):
,如上面兩個公式可以改成如下式子(下標kj的是輸出層的,下標ji的是隱藏層的): 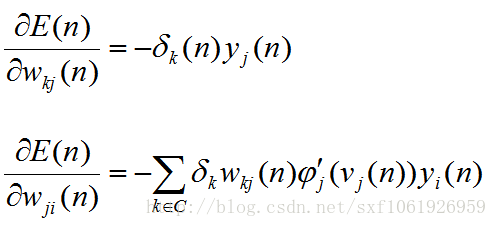
然後隱藏層的前半部分式子可以繼續合併
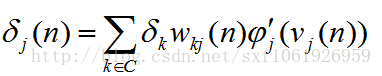
最終得到
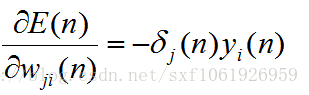
所以不管是求哪個權值的梯度,我們都可以化簡為如下形式
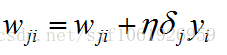
這樣演算法實現起來就方便多了
python實現
主程式 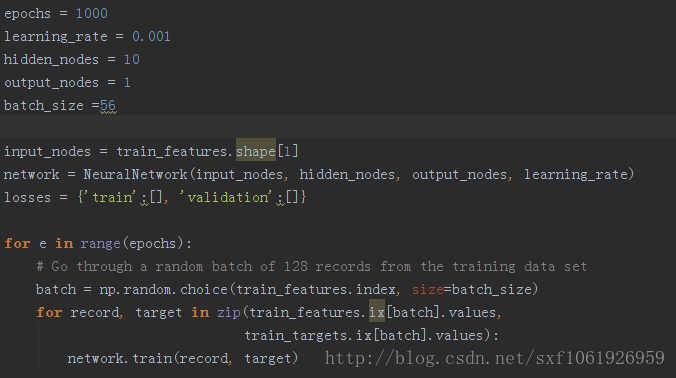
定義好輸入節點、輸出節點、隱藏節點大小、以及學習率等
前向傳播 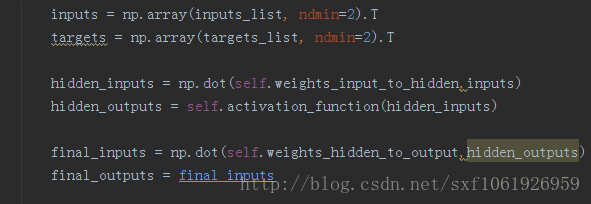
反向更新

程式碼github:bp.py
相關推薦
神經網路和BP演算法推導
我的原文:www.hijerry.cn/p/53364.htm… 感知機 感知機(perceptron)於1957年由Rosenblatt提出,是一種二分類線性模型。感知機以樣本特徵向量作為輸入,輸出為預測類別,取正、負兩類。感知機最終學習到的是將輸入空間(特徵空間)劃分為正、負兩類的分離超平面,屬於判別
深度學習-神經網路 BP 演算法推導過程
BP 演算法推導過程 一.FP過程(前向-計算預測值) 定義sigmoid啟用函式 import numpy as np def sigmoid(z): return 1.0 / (1 + np.exp(-z)) 輸入層值和 標籤結果 l = [5.0, 10.0] y = [0.01,
BP演算法推導
輸出層梯度求解過程如上圖所示,為一個輸出層神經元,在計算輸出層梯度的時候,我們不用去考慮前一層是如何輸入的。所以我們用y來表示,圖中的y(n)表示第n個樣本在前一層的輸出值,這一層的輸入值。我們將當前節點定義為j。那麼當前節點j的輸入值之和為 這裡的m是節點j前一層的輸入節點的個數,其中包括一個偏置項b。這
神經網路與BP演算法推導
導言 神經網路是深度學習基礎,BP演算法是神經網路訓練中最基礎的演算法。因此,對神經網路結構和BP演算法進行梳理是理解深度學習的有效方法。參考資料UFLDL,BP推導,神經網路教材。 神經網路結構 典型網路為淺層網路,一般2~4層。其結構如下圖所示:
機器學習之神經網路bp演算法推導
這是一篇學習UFLDL反向傳導演算法的筆記,按自己的思路捋了一遍,有不對的地方請大家指點。 首先說明一下神經網路的符號: 1. nl 表示神經網路的層數。 2. sl 表示第 l 層神經元個數,不包含偏置單元。 3. z(l)i 表示第 l 層第 i 個
【機器學習演算法推導】BP神經網路
非線性問題 對於一張汽車圖片,如何將其識別為汽車呢?我們人可能看一眼就能識別出來,但是如何讓計算機也擁有同樣的技能呢?我們知道,一張圖片在計算機中都是以畫素矩陣的形式儲存的,無論是一輛汽車,還是一輛飛機,在計算機中都是一個個矩陣,並無法直觀地感受到這個矩陣代表是汽車還是飛機。用邏輯迴
BP演算法與公式推導
BP(backpropgationalgorithm ):後向傳導演算法,顧名思義就是從神經網路的輸出(頂層)到輸入(底層)進行求解。那麼求解什麼呢,求解的就是神經網路中的引數的導數,即引數梯度方向,從而就可以使用梯度下降等求解無約束問題(cost fun
BP演算法公式推導
首先來了解基本的定義, 如, 其中,N表示訓練樣本的數量,向量x(n)表示第n個樣本在輸入層輸入資料,向量d(n)表示在輸出層對應的期望的輸出。 設神經元j位於網路的輸出層,那麼由該神經元輸出產
深度學習基礎:反向傳播即BP演算法的推導過程
BP演算法簡單的來說就是根據神經網路實際的輸出和目標輸出(也就是輸入樣本對應的標記)之間的誤差計算神經網路各個權值的過程。 下面的推導過程參考了《神經網路設計》 Martin T. Hagan等著 戴葵等譯。 採用BP演算法從輸出層、經過隱層再到輸入層進行層層計算的原因是如
BP(反向傳播)演算法和CNN反向傳播演算法推導(轉載)
轉載來源: http://blog.csdn.net/walegahaha/article/details/51867904 http://blog.csdn.net/walegahaha/article/details/51945421 關於CNN推導可以參考文獻:
卷積神經網路反向BP演算法公式推導
博文轉載至:http://blog.csdn.net/celerychen2009/article/details/8964753 此篇博文只涉及到公式推導,如果想了解卷積神經網路的具體工作過程,可檢視轉載博文博主其它文件或者百度自己去看。轉載的文章涉及到的角下標大家注意下
BP演算法的推導(注意殘差的定義)
反向傳播BP模型 學習是神經網路一種最重要也最令人注目的特點。在神經網路的發展程序中,學習演算法的研究有著十分重要的地位。目前,人們所提出的神經網路模型都是和學習演算法相應的。所以,有時人們並不去祈求對模型和演算法進行嚴格的定義或區分。有的模型可以有多種演算法.而有的演算法可能可用於多種模型。不過,有
神經網路中的BP演算法(原理和推導)
BP演算法介紹 BP演算法(Background Propagation Alogorithm), 即誤差逆傳播演算法,是訓練多層前饋神經網路的一種最經典的演算法,通過BP演算法可以學得網路的權重和閾值,且具有可靠的收斂性。 網路結構 首先對所用的符號和變
BP 演算法手動實現
github部落格傳送門 csdn部落格傳送門 本章所需知識: numpy matplotlib 資料下載連結: 深度學習基礎網路模型(mnist手寫體識別資料集) 梯度下降 BP 演算法手動實現 import numpy as np import matplotlib.pyplot
深度學習BP演算法 BackPropagation以及詳細例子解析
反向傳播演算法是多層神經網路的訓練中舉足輕重的演算法,本文著重講解方向傳播演算法的原理和推導過程。因此對於一些基本的神經網路的知識,本文不做介紹。在理解反向傳播演算法前,先要理解神經網路中的前饋神經網路演算法。 前饋神經網路 如下圖,是一個多層神
反向傳導(BP)演算法
假設我們有一個固定樣本集 ,它包含 個樣例。我們可以用批量梯度下降法來求解神經網路。具體來講,對於單個樣例 ,其代價函式為: 這是一個(二分之一的)方差代價函式。給定一個包含 個樣例的資料集,我們可以定義整體代價函式為: 以上關於定
深度學習 --- BP演算法詳解(誤差反向傳播演算法)
本節開始深度學習的第一個演算法BP演算法,本打算第一個演算法為單層感知器,但是感覺太簡單了,不懂得找本書看看就會了,這裡簡要的介紹一下單層感知器: 圖中可以看到,單層感知器很簡單,其實本質上他就是線性分類器,和機器學習中的多元線性迴歸的表示式差不多,因此它具有多元線性迴歸的優點和缺點。
深度學習 --- BP演算法詳解(BP演算法的優化)
上一節我們詳細分析了BP網路的權值調整空間的特點,深入分析了權值空間存在的兩個問題即平坦區和區域性最優值,也詳細探討了出現的原因,本節將根據上一節分析的原因進行改進BP演算法,本節先對BP存在的缺點進行全面的總結,然後給出解決方法和思路,好,下面正式開始本節的內容: BP演算法可以完成非線性
深度學習 --- BP演算法詳解(流程圖、BP主要功能、BP演算法的侷限性)
上一節我們詳細推倒了BP演算法的來龍去脈,請把原理一定要搞懂,不懂的請好好理解BP演算法詳解,我們下面就直接把上一節推匯出的權值調整公式拿過來,然後給出程式流程圖,該流程圖是嚴格按照上一節的權值更新過程寫出的,因此稱為標準的BP演算法,標準的BP演算法中,每輸入一個樣本,都要回傳誤差並調整權值,
反向傳播演算法(BP演算法)
BP演算法(即反向傳播演算法),適合於多層神經元網路的一種學習演算法,它建立在梯度下降法的基礎上。BP網路的輸入輸出關係實質上是一種對映關係:一個n輸入m輸出的BP神經網路所完成的功能是從n維歐氏空間向m維歐氏空間中一有限域的連續對映,這一對映具有高度非線性。它的資訊處理能力來源於簡單非線性函式的多