
深入理解Spark 2.1 Core (六):Standalone模式執行的原理與原始碼分析
啟動AppClient
呼叫棧如下:
- StandaloneSchedulerBackend.start
- StandaloneAppClient.start
- StandaloneAppClient.ClientEndpoint.onStart
- StandaloneAppClient.registerWithMaster
- StandaloneAppClient.tryRegisterAllMasters
- StandaloneAppClient.registerWithMaster
- StandaloneAppClient.ClientEndpoint.onStart
- StandaloneAppClient.start
- Master.receive
- Master.createApplication
- Master.registerApplication
- StandaloneAppClient.ClientEndpoint.receive
StandaloneSchedulerBackend.start
在Standalone模式下,SparkContext中的backend是StandaloneSchedulerBackend。在StandaloneSchedulerBackend.start中可以看到:
***
val appUIAddress = sc.ui.map(_.appUIAddress).getOrElse("")
val coresPerExecutor = conf.getOption("spark.executor.cores").map(_.toInt)
val initialExecutorLimit =
if - 1
- 8
StandaloneAppClient.start
def start() {
//生成了ClientEndpoint,於是呼叫其onStart
endpoint.set(rpcEnv.setupEndpoint("AppClient", new ClientEndpoint(rpcEnv)))
}- 1
StandaloneAppClient.ClientEndpoint.onStart
呼叫registerWithMaster
override def onStart(): Unit = {
try {
registerWithMaster(1)
} catch {
case e: Exception =>
logWarning("Failed to connect to master", e)
markDisconnected()
stop()
}
}StandaloneAppClient.registerWithMaster
private def registerWithMaster(nthRetry: Int) {
//向所有的Master註冊當前App
//一旦成功連線的一個master,其他將被取消
registerMasterFutures.set(tryRegisterAllMasters())
registrationRetryTimer.set(registrationRetryThread.schedule(new Runnable {
override def run(): Unit = {
if (registered.get) {
registerMasterFutures.get.foreach(_.cancel(true))
registerMasterThreadPool.shutdownNow()
}
//若達到最大嘗試次數,則標誌死亡,預設為3
else if (nthRetry >= REGISTRATION_RETRIES) {
markDead("All masters are unresponsive! Giving up.")
} else {
registerMasterFutures.get.foreach(_.cancel(true))
registerWithMaster(nthRetry + 1)
}
}
}, REGISTRATION_TIMEOUT_SECONDS, TimeUnit.SECONDS))
}
- 1
StandaloneAppClient.tryRegisterAllMasters
給Master傳送RegisterApplication訊號:
private def tryRegisterAllMasters(): Array[JFuture[_]] = {
for (masterAddress <- masterRpcAddresses) yield {
registerMasterThreadPool.submit(new Runnable {
override def run(): Unit = try {
if (registered.get) {
return
}
logInfo("Connecting to master " + masterAddress.toSparkURL + "...")
val masterRef = rpcEnv.setupEndpointRef(masterAddress, Master.ENDPOINT_NAME)
masterRef.send(RegisterApplication(appDescription, self))
} catch {
case ie: InterruptedException => // Cancelled
case NonFatal(e) => logWarning(s"Failed to connect to master $masterAddress", e)
}
})
}
}- 1
- 17
Master.receive
Master.receive接收並處理RegisterApplication訊號
case RegisterApplication(description, driver) =>
// 若之前註冊過
if (state == RecoveryState.STANDBY) {
// 忽略
} else {
logInfo("Registering app " + description.name)
//建立app
val app = createApplication(description, driver)
//註冊app
registerApplication(app)
logInfo("Registered app " + description.name + " with ID " + app.id)
//持久化
persistenceEngine.addApplication(app)
//回覆RegisteredApplication訊號
driver.send(RegisteredApplication(app.id, self))
//資源排程
schedule()
}- 1
- 13
讓我們深入來看下Master是如何註冊app的。
Master.createApplication
先建立app:
private def createApplication(desc: ApplicationDescription, driver: RpcEndpointRef):
ApplicationInfo = {
val now = System.currentTimeMillis()
val date = new Date(now)
//根據日期生成appId
val appId = newApplicationId(date)
//傳入 時間,appId, 描述資訊, 日期, driver, 預設核數,
//生成app資訊
new ApplicationInfo(now, appId, desc, date, driver, defaultCores)
}- 1
Master.registerApplication
再註冊app:
private def registerApplication(app: ApplicationInfo): Unit = {
//若已有這個app地址,
//則返回
val appAddress = app.driver.address
if (addressToApp.contains(appAddress)) {
logInfo("Attempted to re-register application at same address: " + appAddress)
return
}
//向 applicationMetricsSystem 註冊appSource
applicationMetricsSystem.registerSource(app.appSource)
//將app加入到 集合
//HashSet[ApplicationInfo]
apps += app
//更新 id到App
//HashMap[String, ApplicationInfo]
idToApp(app.id) = app
//更新 endpoint到App
// HashMap[RpcEndpointRef, ApplicationInfo]
endpointToApp(app.driver) = app
//更新 address到App
// HashMap[RpcAddress, ApplicationInfo]
addressToApp(appAddress) = app
// 加入到等待陣列中
//ArrayBuffer[ApplicationInfo]
waitingApps += app
if (reverseProxy) {
webUi.addProxyTargets(app.id, app.desc.appUiUrl)
}
}- 1
StandaloneAppClient.ClientEndpoint.receive
case RegisteredApplication(appId_, masterRef) =>
//這裡的程式碼有兩個缺陷:
//1. 一個Master可能接收到多個註冊請求,
// 並且回覆多個RegisteredApplication訊號,
//這會導致網路不穩定。
//2.若master正在變化,
//則會接收到多個RegisteredApplication訊號
//設定appId
appId.set(appId_)
//編輯已經註冊
registered.set(true)
//建立master資訊
master = Some(masterRef)
//繫結監聽
listener.connected(appId.get)- 11
邏輯資源排程
我們可以看到在上一章,Master.receive接收並處理RegisterApplication訊號時的最後一行程式碼:
//資源排程
schedule()- 1
下面,我們就來講講資源排程。
呼叫棧如下:
- Master.schedule
- Master.startExecutorsOnWorkers
- Master.scheduleExecutorsOnWorkers
- Master.allocateWorkerResourceToExecutors
- Master.startExecutorsOnWorkers
Master.schedule
該方法主要來在等待的app之間排程資源。每次有新的app加入或者可用資源改變的時候,這個方法都會被呼叫:
private def schedule(): Unit = {
if (state != RecoveryState.ALIVE) {
return
}
// 得到活的Worker,
// 並打亂它們
val shuffledAliveWorkers = Random.shuffle(workers.toSeq.filter(_.state == WorkerState.ALIVE))
// worker數量
val numWorkersAlive = shuffledAliveWorkers.size
var curPos = 0
//為driver分配資源,
//該排程策略為FIFO的策略,
//先來的driver會先滿足其資源所需的條件
for (driver <- waitingDrivers.toList) {
var launched = false
var numWorkersVisited = 0
while (numWorkersVisited < numWorkersAlive && !launched) {
val worker = shuffledAliveWorkers(curPos)
numWorkersVisited += 1
if (worker.memoryFree >= driver.desc.mem && worker.coresFree >= driver.desc.cores) {
launchDriver(worker, driver)
waitingDrivers -= driver
launched = true
}
curPos = (curPos + 1) % numWorkersAlive
}
}
//啟動worker上的executor
startExecutorsOnWorkers()
}- 1
- 2
- 2
Master.startExecutorsOnWorkers
接下來我們來看下executor的啟動:
private def startExecutorsOnWorkers(): Unit = {
// 這裡還是使用的FIFO的排程方式
for (app <- waitingApps if app.coresLeft > 0) {
val coresPerExecutor: Option[Int] = app.desc.coresPerExecutor
// 過濾掉資源不夠啟動executor的worker
// 並按資源逆序排序
val usableWorkers = workers.toArray.filter(_.state == WorkerState.ALIVE)
.filter(worker => worker.memoryFree >= app.desc.memoryPerExecutorMB &&
worker.coresFree >= coresPerExecutor.getOrElse(1))
.sortBy(_.coresFree).reverse
//排程worker上的executor,
//確定在每個worker上給這個app分配多少核
val assignedCores = scheduleExecutorsOnWorkers(app, usableWorkers, spreadOutApps)
//分配
for (pos <- 0 until usableWorkers.length if assignedCores(pos) > 0) {
allocateWorkerResourceToExecutors(
app, assignedCores(pos), coresPerExecutor, usableWorkers(pos))
}
}
}Master.scheduleExecutorsOnWorkers
接下來我們就來講講核心的worker上的executor資源排程。在將現在的Spark程式碼之前,我們看看在Spark1.4之前,這部分邏輯是如何實現的:
***
val numUsable = usableWorkers.length
// 用來記錄每個worker已經分配的核數
val assigned = new Array[Int](numUsable)
var toAssign = math.min(app.coresLeft, usableWorkers.map(_.coresFree).sum)
var pos = 0
while (toAssign > 0) {
//遍歷worker,
//若當前worker還存在資源,
//則分配掉1個核。
//直到workers的資源全都被分配掉,
//或者是app所需要的資源被滿足。
if (usableWorkers(pos).coresFree - assigned(pos) > 0) {
toAssign -= 1
assigned(pos) += 1
}
pos = (pos + 1) % numUsable
}
***- 1
在Spark1.4的時候,這段程式碼被修改了。我們來想一下,以上程式碼有什麼問題?
問題就在於,core是一個一個的被分配的。設想,一個叢集中有4 worker,每個worker有16個core。使用者想啟動3個executor,且每個executor擁有16個core。於是,他會這樣配置引數:
spark.cores.max = 48
spark.executor.cores = 16顯然,我們叢集的資源是能滿足使用者的需求的。但如果一次只能分配一個core,那最終的結果是每個worker上都分配了12個core。由於12 < 16, 所有沒有一個executor能夠啟動。
下面,我們回過頭來看現在的原始碼中是如何實現這部分邏輯的:
private def scheduleExecutorsOnWorkers(
app: ApplicationInfo,
usableWorkers: Array[WorkerInfo],
spreadOutApps: Boolean): Array[Int] = {
val coresPerExecutor = app.desc.coresPerExecutor
val minCoresPerExecutor = coresPerExecutor.getOrElse(1)
val oneExecutorPerWorker = coresPerExecutor.isEmpty
val memoryPerExecutor = app.desc.memoryPerExecutorMB
val numUsable = usableWorkers.length
// 用來記錄每個worker已經分配的核數
val assignedCores = new Array[Int](numUsable)
// 用來記錄每個worker已經分配的executor數
val assignedExecutors = new Array[Int](numUsable)
// 剩餘總共資源
var coresToAssign = math.min(app.coresLeft, usableWorkers.map(_.coresFree).sum)
//判斷是否能啟動Executor
def canLaunchExecutor(pos: Int): Boolean = {
//先省略
}
//過濾去能啟動executor的Worker
var freeWorkers = (0 until numUsable).filter(canLaunchExecutor)
//排程資源,
//直到worker上的executor被分配完
while (freeWorkers.nonEmpty) {
freeWorkers.foreach { pos =>
var keepScheduling = true
while (keepScheduling && canLaunchExecutor(pos)) {
// minCoresPerExecutor 是使用者設定的 spark.executor.cores
coresToAssign -= minCoresPerExecutor
assignedCores(pos) += minCoresPerExecutor
// 若使用者沒有設定 spark.executor.cores
// 則oneExecutorPerWorker就為True
// 也就是說,assignedCores中的core都被一個executor使用
// 若使用者設定了spark.executor.cores,
// 則該Worker的assignedExecutors會加1
if (oneExecutorPerWorker) {
assignedExecutors(pos) = 1
} else {
assignedExecutors(pos) += 1
}
//資源分配演算法有兩種:
// 1. 儘量打散,將一個app儘可能的分配到不同的節點上,
// 這有利於充分利用叢集的資源,
// 在這種情況下,spreadOutApps設為True,
// 於是,該worker分配好了一個executor之後就退出迴圈
// 輪詢到下一個worker
// 2. 儘量集中,將一個app儘可能的分配到同一個的節點上,
// 這適合cpu密集型而記憶體佔用比較少的app
// 在這種情況下,spreadOutApps設為False,
// 於是,繼續下一輪的迴圈
// 在該Worker上分配executor
if (spreadOutApps) {
keepScheduling = false
}
}
}
freeWorkers = freeWorkers.filter(canLaunchExecutor)
}
assignedCores
}- 1
- 4
接下來看下該函式的內部函式canLaunchExecutor:
def canLaunchExecutor(pos: Int): Boolean = {
// 條件1 :若叢集剩餘core >= spark.executor.cores
val keepScheduling = coresToAssign >= minCoresPerExecutor
// 條件2: 若該Worker上的剩餘core >= spark.executor.cores
val enoughCores = usableWorkers(pos).coresFree - assignedCores(pos) >= minCoresPerExecutor
// 條件3: 若設定了spark.executor.cores
// 或者 該Worker還未分配executor
val launchingNewExecutor = !oneExecutorPerWorker || assignedExecutors(pos) == 0
if (launchingNewExecutor) {
val assignedMemory = assignedExecutors(pos) * memoryPerExecutor
// 條件4:若該Worker上的剩餘記憶體 >= spark.executor.memory
val enoughMemory = usableWorkers(pos).memoryFree - assignedMemory >= memoryPerExecutor
// 條件5: 若分配了該executor後,
// 總共分配的core數量 <= spark.cores.max
val underLimit = assignedExecutors.sum + app.executors.size < app.executorLimit
//若滿足 條件3,
//且滿足 條件1,條件2,條件4,條件5
//則返回True
keepScheduling && enoughCores && enoughMemory && underLimit
} else {
//若不滿足 條件3,
//即一個worker只有一個executor
//且滿足 條件1,條件2
//也返回True。
// 返回後,不會增加 assignedExecutors
keepScheduling && enoughCores
}
}- 1
- 2
通過以上原始碼,我們可以清楚看到,Spark1.4以後新的邏輯實現其實就是將分配單位從原來的一個core,變為了一個executor(即spark.executor.cores)。而若一個worker上只有一個executor(即沒有設定spark.executor.cores),那麼就按照原來的邏輯實現。
值得我注意的是:
//直到worker上的executor被分配完
while (freeWorkers.nonEmpty) 一個app會盡可能的使用掉叢集的所有資源,所以設定spark.cores.max引數是非常有必要的!
Master.allocateWorkerResourceToExecutors
現在我們回到上述提到的Master.startExecutorsOnWorkers中,深入allocateWorkerResourceToExecutors:
private def allocateWorkerResourceToExecutors(
app: ApplicationInfo,
assignedCores: Int,
coresPerExecutor: Option[Int],
worker: WorkerInfo): Unit = {
// 該work上的executor數量
// 若沒設定 spark.executor.cores
// 則為1
val numExecutors = coresPerExecutor.map { assignedCores / _ }.getOrElse(1)
// 分配給一個executor的core數量
// 若沒設定 spark.executor.cores
// 則為該worker上所分配的所有core是數量
val coresToAssign = coresPerExecutor.getOrElse(assignedCores)
for (i <- 1 to numExecutors) {
//建立該executor資訊
//並把它加入到app資訊中
//並返回executor資訊
val exec = app.addExecutor(worker, coresToAssign)
//啟動
launchExecutor(worker, exec)
app.state = ApplicationState.RUNNING
}
}- 1
- 9
- 10
要注意的是
app.state = ApplicationState.RUNNING這句程式碼並不是將該app從waitingApp佇列中去除。若在該次資源排程中該app並沒有啟動足夠的executor,等到叢集資源變化時,會再次資源排程,在waitingApp中遍歷到該app,其coresLeft > 0。
for (app <- waitingApps if app.coresLeft > 0)我們這裡做一個實驗:
- 我們的實驗叢集是4*8核的叢集:
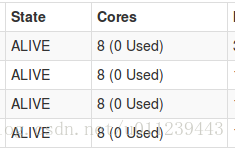
- 第1個app,我們申請4個executor,該executor為4個core:
spark-shell --master spark://cdh03:7077 --total-executor-cores 4 --executor-cores 4可以看到叢集資源:
app1的executor:
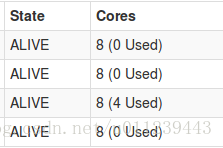
- 第2個app,我們申請4個executor,該executor為6個core:
spark-shell --master spark://cdh03:7077 --total-executor-cores 24 --executor-cores 6可以看到叢集資源:
app2的executor:
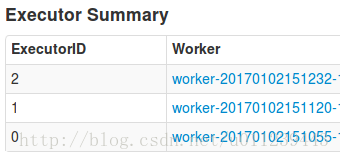
我們可以看到,Spark只為app2分配了3個executor。
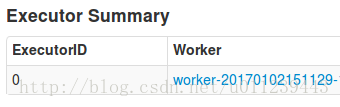
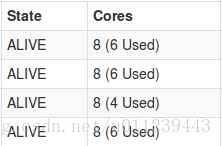
- 當我們把app1退出
會發現叢集資源狀態:
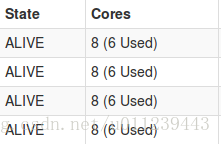
app2的executor:
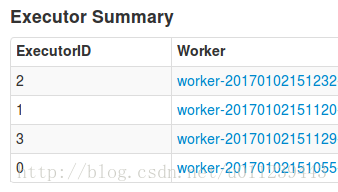
會發現新增加了一個“ worker-20170102151129”的executor。
其實,只要叢集中的app沒結束,它們都會在waitingApps中,當該app結束時,才會將這個app從waitingApps中移除
def removeApplication(app: ApplicationInfo, state: ApplicationState.Value) {
***
waitingApps -= app
***
}物理資源排程與啟動Executor
接下來,我們就來講邏輯上資源排程完後,該如何物理上資源排程,即啟動Executor。
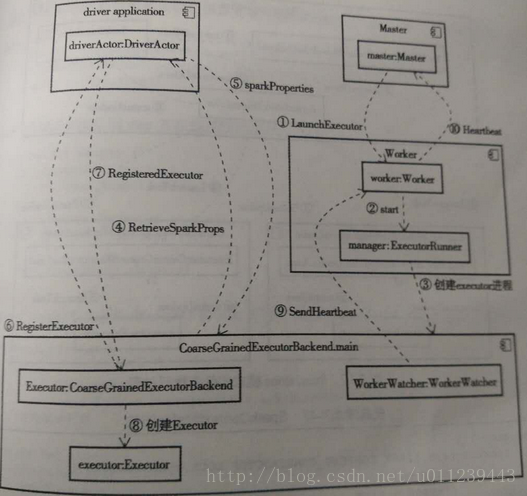
呼叫棧如下:
- Master.launchExecutor
- Worker.receive
- ExecutorRunner.start
- ExecutorRunner.fetchAndRunExecutor
- ExecutorRunner.start
- CoarseGrainedExecutorBackend.main
- CoarseGrainedExecutorBackend.run
- CoarseGrainedExecutorBackend.onStart
- CoarseGrainedExecutorBackend.run
- CoarseGrainedSchedulerBackend.DriverEndpoint.receiveAndReply
- CoarseGrainedExecutorBackend.receive
Master.launchExecutor
private def launchExecutor(worker: WorkerInfo, exec: ExecutorDesc): Unit = {
logInfo("Launching executor " + exec.fullId + " on worker " + worker.id)
//在worker資訊中加入executor資訊
worker.addExecutor(exec)
//給worker傳送LaunchExecutor訊號
worker.endpoint.send(LaunchExecutor(masterUrl,
exec.application.id, exec.id, exec.application.desc, exec.cores, exec.memory))
//給driver傳送ExecutorAdded訊號
exec.application.driver.send(
ExecutorAdded(exec.id, worker.id, worker.hostPort, exec.cores, exec.memory))
}Worker.receive
worker接收到LaunchExecutor訊號後處理:
case LaunchExecutor(masterUrl, appId, execId, appDesc, cores_, memory_) =>
if (masterUrl != activeMasterUrl) {
logWarning("Invalid Master (" + masterUrl + ") attempted to launch executor.")
} else {
try {
logInfo("Asked to launch executor %s/%d for %s".format(appId, execId, appDesc.name))
// 建立executor的工作目錄
// shuffle持久化結果會存在這個目錄下
// 節點應每塊磁碟大小盡可能相同
// 並在配置中在每塊磁碟上都設定SPARK_WORKER_DIR,
// 以增加IO效能
val executorDir = new File(workDir, appId + "/" + execId)
if (!executorDir.mkdirs()) {
throw new IOException("Failed to create directory " + executorDir)
}
// 為app建立本地dir
// app完成後,此目錄會被刪除
val appLocalDirs = appDirectories.getOrElse(appId,
Utils.getOrCreateLocalRootDirs(conf).map { dir =>
val appDir = Utils.createDirectory(dir, namePrefix = "executor")
Utils.chmod700(appDir)
appDir.getAbsolutePath()
}.toSeq)
appDirectories(appId) = appLocalDirs
//建立ExecutorRunner
val manager = new ExecutorRunner(
appId,
execId,
appDesc.copy(command = Worker.maybeUpdateSSLSettings(appDesc.command, conf)),
cores_,
memory_,
self,
workerId,
host,
webUi.boundPort,
publicAddress,
sparkHome,
executorDir,
workerUri,
conf,
appLocalDirs, ExecutorState.RUNNING)
executors(appId + "/" + execId) = manager
//啟動ExecutorRunner
manager.start()
coresUsed += cores_
memoryUsed += memory_
// 向Master傳送ExecutorStateChanged訊號
sendToMaster(ExecutorStateChanged(appId, execId, manager.state, None, None))
} catch {
case e: Exception =>
logError(s"Failed to launch executor $appId/$execId for ${appDesc.name}.", e)
if (executors.contains(appId + "/" + execId)) {
executors(appId + "/" + execId).kill()
executors -= appId + "/" + execId
}
sendToMaster(ExecutorStateChanged(appId, execId, ExecutorState.FAILED,
Some(e.toString), None))
}
}- 1
- 5
ExecutorRunner.start
接下來我們深入看下ExecutorRunner
private[worker] def start() {
//建立worker執行緒
workerThread = new Thread("ExecutorRunner for " + fullId) {
override def run() { fetchAndRunExecutor() }
}
//啟動worker執行緒
workerThread.start()
// 建立Shutdownhook執行緒
// 用於worker關閉時,殺掉executor
shutdownHook = ShutdownHookManager.addShutdownHook { () =>
if (state == ExecutorState.RUNNING) {
state = ExecutorState.FAILED
}
killProcess(Some("Worker shutting down")) }
}ExecutorRunner.fetchAndRunExecutor
workerThread執行主要是呼叫fetchAndRunExecutor,下面我們來看下這個方法:
private def fetchAndRunExecutor() {
try {
// 建立程序builder
val builder = CommandUtils.buildProcessBuilder(appDesc.command, new SecurityManager(conf),
memory, sparkHome.getAbsolutePath, substituteVariables)
val command = builder.command()
val formattedCommand = command.asScala.mkString("\"", "\" \"", "\"")
logInfo(s"Launch command: $formattedCommand")
//建立程序builder執行目錄
builder.directory(executorDir)
//為程序builder設定環境變數
builder.environment.put("SPARK_EXECUTOR_DIRS", appLocalDirs.mkString(File.pathSeparator))
builder.environment.put("SPARK_LAUNCH_WITH_SCALA", "0")
val baseUrl =
if (conf.getBoolean("spark.ui.reverseProxy", false)) {
s"/proxy/$workerId/logPage/?appId=$appId&executorId=$execId&logType="
} else {
s"http://$publicAddress:$webUiPort/logPage/?appId=$appId&executorId=$execId&logType="
}
builder.environment.put("SPARK_LOG_URL_STDERR", s"${baseUrl}stderr")
builder.environment.put("SPARK_LOG_URL_STDOUT", s"${baseUrl}stdout")
//啟動程序builder,建立程序
process = builder.start()
val header = "Spark Executor Command: %s\n%s\n\n".format(
formattedCommand, "=" * 40)
// 重定向它的stdout和stderr到檔案中
val stdout = new File(executorDir, "stdout")
stdoutAppender = FileAppender(process.getInputStream, stdout, conf)
val stderr = new File(executorDir, "stderr")
Files.write(header, stderr, StandardCharsets.UTF_8)
stderrAppender = FileAppender(process.getErrorStream, stderr, conf)
// 等待程序退出。
// 當driver通知該程序退出
// executor會退出並返回0或者非0的exitCode
val exitCode = process.waitFor()
state = ExecutorState.EXITED
val message = "Command exited with code " + exitCode
// 給Worker傳送ExecutorStateChanged訊號
worker.send(ExecutorStateChanged(appId, execId, state, Some(message), Some(exitCode)))
} catch {
case interrupted: InterruptedException =>
logInfo("Runner thread for executor " + fullId + " interrupted")
state = ExecutorState.KILLED
killProcess(None)
case e: Exception =>
logError("Error running executor", e)
state = ExecutorState.FAILED
killProcess(Some(e.toString))
}
}
}- 1
- 1
CoarseGrainedExecutorBackend.main
builder start的是CoarseGrainedExecutorBackend例項程序,我們看下它的主函式:
def main(args: Array[String]) {
var driverUrl: String = null
var executorId: String = null
var hostname: String = null
var cores: Int = 0
var appId: String = null
var workerUrl: Option[String] = None
val userClassPath = new mutable.ListBuffer[URL]()
// 設定引數
var argv = args.toList
while (!argv.isEmpty) {
argv match {
case ("--driver-url") :: value :: tail =>
driverUrl = value
argv = tail
case ("--executor-id") :: value :: tail =>
executorId = value
argv = tail
case ("--hostname") :: value :: tail =>
hostname = value
argv = tail
case ("--cores") :: value :: tail =>
cores = value.toInt
argv = tail
case ("--app-id") :: value :: tail =>
appId = value
argv = tail
case ("--worker-url") :: value :: tail =>
workerUrl = Some(value)
argv = tail
case ("--user-class-path") :: value :: tail =>
userClassPath += new URL(value)
argv = tail
case Nil =>
case tail =>
System.err.println(s"Unrecognized options: ${tail.mkString(" ")}")
printUsageAndExit()
}
}
if (driverUrl == null || executorId == null || hostname == null || cores <= 0 ||
appId == null) {
printUsageAndExit()
}
//呼叫run方法
run(driverUrl, executorId, hostname, cores, appId, workerUrl, userClassPath)
System.exit(0)
}- 1
- 29
CoarseGrainedExecutorBackend.run
private def run(
driverUrl: String,
executorId: String,
hostname: String,
cores: Int,
appId: String,
workerUrl: Option[String],
userClassPath: Seq[URL]) {
Utils.initDaemon(log)
SparkHadoopUtil.get.runAsSparkUser { () =>
Utils.checkHost(hostname)
val executorConf = new SparkConf
val port = executorConf.getInt("spark.executor.port", 0)
val fetcher = RpcEnv.create(
"driverPropsFetcher",
hostname,
port,
executorConf,
new SecurityManager(executorConf),
clientMode = true)
val driver = fetcher.setupEndpointRefByURI(driverUrl)
// 給driver傳送RetrieveSparkAppConfig訊號,
// 並根據返回的資訊建立屬性
val cfg = driver.askWithRetry[SparkAppConfig](RetrieveSparkAppConfig)
val props = cfg.sparkProperties ++ Seq[(String, String)](("spark.app.id", appId))
fetcher.shutdown()
// 根據這些屬性來建立SparkEnv
val driverConf = new SparkConf()
for ((key, value) <- props) {
if (SparkConf.isExecutorStartupConf(key)) {
driverConf.setIfMissing(key, value)
} else {
driverConf.set(key, value)
}
}
if (driverConf.contains("spark.yarn.credentials.file")) {
logInfo("Will periodically update credentials from: " +
driverConf.get("spark.yarn.credentials.file"))
SparkHadoopUtil.get.startCredentialUpdater(driverConf)
}
val env = SparkEnv.createExecutorEnv(
driverConf, executorId, hostname, port, cores, cfg.ioEncryptionKey, isLocal = false)
// 建立CoarseGrainedExecutorBackend Endpoint
env.rpcEnv.setupEndpoint("Executor", new CoarseGrainedExecutorBackend(
env.rpcEnv, driverUrl, executorId, hostname, cores, userClassPath, env))
// 建立WorkerWatcher Endpoint
// 用來給worker傳送心跳,
// 告訴worker 這個程序還活著
workerUrl.foreach { url =>
env.rpcEnv.setupEndpoint("WorkerWatcher", new WorkerWatcher(env.rpcEnv, url))
}
env.rpcEnv.awaitTermination()
SparkHadoopUtil.get.stopCredentialUpdater()
}
}- 46
CoarseGrainedExecutorBackend.onStart
new CoarseGrainedExecutorBackend 會呼叫CoarseGrainedExecutorBackend.onStart:
override def onStart() {
logInfo("Connecting to driver: " + driverUrl)
rpcEnv.asyncSetupEndpointRefByURI(driverUrl).flatMap { ref =>
//向driver端傳送RegisterExecutor訊號
driver = Some(ref)
ref.ask[Boolean](RegisterExecutor(executorId, self, hostname, cores, extractLogUrls))
}(ThreadUtils.sameThread).onComplete {
case Success(msg) =>
case Failure(e) =>
exitExecutor(1, s"Cannot register with driver: $driverUrl", e, notifyDriver = false)
}(ThreadUtils.sameThread)
}- 1
CoarseGrainedSchedulerBackend.DriverEndpoint.receiveAndReply
case RegisterExecutor(executorId, executorRef, hostname, cores, logUrls) =>
if (executorDataMap.contains(executorId)) {
executorRef.send(RegisterExecutorFailed("Duplicate executor ID: " + executorId))
context.reply(true)
} else {
// 設定executor資訊
val executorAddress = if (executorRef.address != null) {
executorRef.address
} else {
context.senderAddress
}
logInfo(s"Registered executor $executorRef ($executorAddress) with ID $executorId")
addressToExecutorId(executorAddress) = executorId
totalCoreCount.addAndGet(cores)
totalRegisteredExecutors.addAndGet(1)
val data = new ExecutorData(executorRef, executorRef.address, hostname,
cores, cores, logUrls)
CoarseGrainedSchedulerBackend.this.synchronized {
executorDataMap.put(executorId, data)
if (currentExecutorIdCounter < executorId.toInt) {
currentExecutorIdCounter = executorId.toInt
}
if (numPendingExecutors > 0) {
numPendingExecutors -= 1
logDebug(s"Decremented number of pending executors ($numPendingExecutors left)")
}
}
//向executor端傳送RegisteredExecutor訊號
executorRef.send(RegisteredExecutor)
context.reply(true)
listenerBus.post(
SparkListenerExecutorAdded(System.currentTimeMillis(), executorId, data))
makeOffers()
}- 1
CoarseGrainedExecutorBackend.receive
CoarseGrainedExecutorBackend接收到來自driver的RegisteredExecutor訊號後:
case RegisteredExecutor =>
logInfo("Successfully registered with driver")
try {
//建立executor
executor = new Executor(executorId, hostname, env, userClassPath, isLocal = false)
} catch {
case NonFatal(e) =>
exitExecutor(1, "Unable to create executor due to " + e.getMessage, e)
}至此,Executor就成功的啟動了!