
『轉_計算機視覺』深度學習中的數據增強
鏈接:https://zhuanlan.zhihu.com/p/61759947
最近被人問到SSD中的數據增強手段,由於我是由《tensorflow實戰google深度學習框架》這本書入門的,其在介紹圖像數據增強的章節中使用的流程和SSD的預處理過程及其相似,這導致我在學習SSD的時候覺得SSD的預處理很常規,完全沒有出乎我預料的地方(哭死),所以特地找一些數據增強的科普性文章轉載學習一下,系統的了解不同的深度學習任務中常用的增強手段有哪些。
1 什麽是數據增強?
數據增強也叫數據擴增,意思是在不實質性的增加數據的情況下,讓有限的數據產生等價於更多數據的價值。

比如上圖,第1列是原圖,後面3列是對第1列作一些隨機的裁剪、旋轉操作得來。
每張圖對於網絡來說都是不同的輸入,加上原圖就將數據擴充到原來的10倍。假如我們輸入網絡的圖片的分辨率大小是256×256,若采用隨機裁剪成224×224的方式,那麽一張圖最多可以產生32×32張不同的圖,數據量擴充將近1000倍。雖然許多的圖相似度太高,實際的效果並不等價,但僅僅是這樣簡單的一個操作,效果已經非凡了。
如果再輔助其他的數據增強方法,將獲得更好的多樣性,這就是數據增強的本質。
數據增強可以分為,有監督的數據增強和無監督的數據增強方法。其中有監督的數據增強又可以分為單樣本數據增強和多樣本數據增強方法,無監督的數據增強分為生成新的數據和學習增強策略兩個方向。
2 有監督的數據增強
有監督數據增強,即采用預設的數據變換規則,在已有數據的基礎上進行數據的擴增,包含單樣本數據增強和多樣本數據增強,其中單樣本又包括幾何操作類,顏色變換類。
2.1. 單樣本數據增強
所謂單樣本數據增強,即增強一個樣本的時候,全部圍繞著該樣本本身進行操作,包括幾何變換類,顏色變換類等。
(1) 幾何變換類
幾何變換類即對圖像進行幾何變換,包括翻轉,旋轉,裁剪,變形,縮放等各類操作,下面展示其中的若幹個操作。

水平翻轉和垂直翻轉

隨機旋轉

隨機裁剪

變形縮放
翻轉操作和旋轉操作,對於那些對方向不敏感的任務,比如圖像分類,都是很常見的操作,在caffe等框架中翻轉對應的就是mirror操作。
翻轉和旋轉不改變圖像的大小,而裁剪會改變圖像的大小。通常在訓練的時候會采用隨機裁剪的方法,在測試的時候選擇裁剪中間部分或者不裁剪。值得註意的是,在一些競賽中進行模型測試時,一般都是裁剪輸入的多個版本然後將結果進行融合,對預測的改進效果非常明顯。
以上操作都不會產生失真,而縮放變形則是失真的。
很多的時候,網絡的訓練輸入大小是固定的,但是數據集中的圖像卻大小不一,此時就可以選擇上面的裁剪成固定大小輸入或者縮放到網絡的輸入大小的方案,後者就會產生失真,通常效果比前者差。
(2) 顏色變換類
上面的幾何變換類操作,沒有改變圖像本身的內容,它可能是選擇了圖像的一部分或者對像素進行了重分布。如果要改變圖像本身的內容,就屬於顏色變換類的數據增強了,常見的包括噪聲、模糊、顏色變換、擦除、填充等等。
基於噪聲的數據增強就是在原來的圖片的基礎上,隨機疊加一些噪聲,最常見的做法就是高斯噪聲。更復雜一點的就是在面積大小可選定、位置隨機的矩形區域上丟棄像素產生黑色矩形塊,從而產生一些彩色噪聲,以Coarse Dropout方法為代表,甚至還可以對圖片上隨機選取一塊區域並擦除圖像信息。

添加Coarse Dropout噪聲
顏色變換的另一個重要變換是顏色擾動,就是在某一個顏色空間通過增加或減少某些顏色分量,或者更改顏色通道的順序。

顏色擾動
還有一些顏色變換,本文就不再詳述。
幾何變換類,顏色變換類的數據增強方法細致數來還有非常多,推薦給大家一個git項目:
https://github.com/aleju/imgaug預覽一下它能完成的數據增強操作吧。

2.2. 多樣本數據增強
不同於單樣本數據增強,多樣本數據增強方法利用多個樣本來產生新的樣本,下面介紹幾種方法。
(1) SMOTE[1]
SMOTE即Synthetic Minority Over-sampling Technique方法,它是通過人工合成新樣本來處理樣本不平衡問題,從而提升分類器性能。
類不平衡現象是很常見的,它指的是數據集中各類別數量不近似相等。如果樣本類別之間相差很大,會影響分類器的分類效果。假設小樣本數據數量極少,如僅占總體的1%,則即使小樣本被錯誤地全部識別為大樣本,在經驗風險最小化策略下的分類器識別準確率仍能達到99%,但由於沒有學習到小樣本的特征,實際分類效果就會很差。
SMOTE方法是基於插值的方法,它可以為小樣本類合成新的樣本,主要流程為:
第一步,定義好特征空間,將每個樣本對應到特征空間中的某一點,根據樣本不平衡比例確定好一個采樣倍率N;
第二步,對每一個小樣本類樣本(x,y),按歐氏距離找出K個最近鄰樣本,從中隨機選取一個樣本點,假設選擇的近鄰點為(xn,yn)。在特征空間中樣本點與最近鄰樣本點的連線段上隨機選取一點作為新樣本點,滿足以下公式:
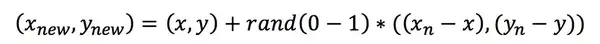
第三步,重復以上的步驟,直到大、小樣本數量平衡。
該方法的示意圖如下。

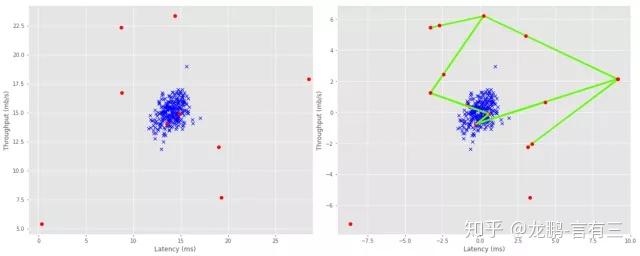
在python中,SMOTE算法已經封裝到了imbalanced-learn庫中,如下圖為算法實現的數據增強的實例,左圖為原始數據特征空間圖,右圖為SMOTE算法處理後的特征空間圖。
(2) SamplePairing[2]
SamplePairing方法的原理非常簡單,從訓練集中隨機抽取兩張圖片分別經過基礎數據增強操作(如隨機翻轉等)處理後經像素以取平均值的形式疊加合成一個新的樣本,標簽為原樣本標簽中的一種。這兩張圖片甚至不限制為同一類別,這種方法對於醫學圖像比較有效。

經SamplePairing處理後可使訓練集的規模從N擴增到N×N。實驗結果表明,因SamplePairing數據增強操作可能引入不同標簽的訓練樣本,導致在各數據集上使用SamplePairing訓練的誤差明顯增加,而在驗證集上誤差則有較大幅度降低。
盡管SamplePairing思路簡單,性能上提升效果可觀,符合奧卡姆剃刀原理,但遺憾的是可解釋性不強。
(3) mixup[3]
mixup是Facebook人工智能研究院和MIT在“Beyond Empirical Risk Minimization”中提出的基於鄰域風險最小化原則的數據增強方法,它使用線性插值得到新樣本數據。
令(xn,yn)是插值生成的新數據,(xi,yi)和(xj,yj)是訓練集隨機選取的兩個數據,則數據生成方式如下
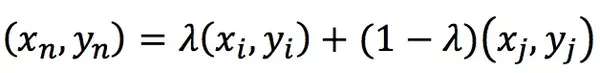
λ的取指範圍介於0到1。提出mixup方法的作者們做了豐富的實驗,實驗結果表明可以改進深度學習模型在ImageNet數據集、CIFAR數據集、語音數據集和表格數據集中的泛化誤差,降低模型對已損壞標簽的記憶,增強模型對對抗樣本的魯棒性和訓練生成對抗網絡的穩定性。
SMOTE,SamplePairing,mixup三者思路上有相同之處,都是試圖將離散樣本點連續化來擬合真實樣本分布,不過所增加的樣本點在特征空間中仍位於已知小樣本點所圍成的區域內。如果能夠在給定範圍之外適當插值,也許能實現更好的數據增強效果。
3 無監督的數據增強
無監督的數據增強方法包括兩類:
(1) 通過模型學習數據的分布,隨機生成與訓練數據集分布一致的圖片,代表方法GAN[4]。
(2) 通過模型,學習出適合當前任務的數據增強方法,代表方法AutoAugment[5]。
3.1 GAN
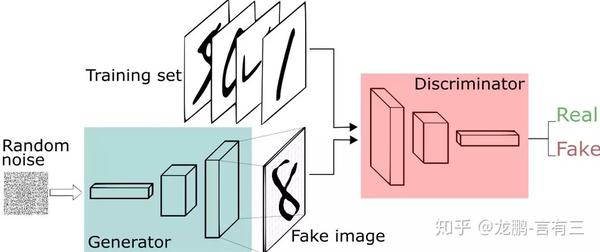
關於GAN(generative adversarial networks),我們已經說的太多了。它包含兩個網絡,一個是生成網絡,一個是對抗網絡,基本原理如下:
(1) G是一個生成圖片的網絡,它接收隨機的噪聲z,通過噪聲生成圖片,記做G(z) 。
(2) D是一個判別網絡,判別一張圖片是不是“真實的”,即是真實的圖片,還是由G生成的圖片。
GAN的以假亂真能力就不多說了。
3.2 Autoaugmentation[5]
AutoAugment是Google提出的自動選擇最優數據增強方案的研究,這是無監督數據增強的重要研究方向。它的基本思路是使用增強學習從數據本身尋找最佳圖像變換策略,對於不同的任務學習不同的增強方法,流程如下:
(1) 準備16個常用的數據增強操作。
(2) 從16個中選擇5個操作,隨機產生使用該操作的概率和相應的幅度,將其稱為一個sub-policy,一共產生5個sub-polices。
(3) 對訓練過程中每一個batch的圖片,隨機采用5個sub-polices操作中的一種。
(4) 通過模型在驗證集上的泛化能力來反饋,使用的優化方法是增強學習方法。
(5) 經過80~100個epoch後網絡開始學習到有效的sub-policies。
(6) 之後串接這5個sub-policies,然後再進行最後的訓練。
總的來說,就是學習已有數據增強的組合策略,對於門牌數字識別等任務,研究表明剪切和平移等幾何變換能夠獲得最佳效果。

而對於ImageNet中的圖像分類任務,AutoAugment學習到了不使用剪切,也不完全反轉顏色,因為這些變換會導致圖像失真。AutoAugment學習到的是側重於微調顏色和色相分布。

除此之外還有一些數據增強方法,篇幅有限不做過多解讀,請持續關註。
4 思考
數據增強的本質是為了增強模型的泛化能力,那它與其他的一些方法比如dropout,權重衰減有什麽區別?
(1) 權重衰減,dropout,stochastic depth等方法,是專門設計來限制模型的有效容量的,用於減少過擬合,這一類是顯式的正則化方法。研究表明這一類方法可以提高泛化能力,但並非必要,且能力有限,而且參數高度依賴於網絡結構等因素。
(2) 數據增強則沒有降低網絡的容量,也不增加計算復雜度和調參工程量,是隱式的規整化方法。實際應用中更有意義,所以我們常說,數據至上。
我們總是在使用有限的數據來進行模型的訓練,因此數據增強操作是不可缺少的一環。從研究人員手工定義數據增強操作,到基於無監督的方法生成數據和學習增強操作的組合,這仍然是一個開放的研究領域,感興趣的同學可以自行了解更多。
『轉_計算機視覺』深度學習中的數據增強