
.NET粉也可以玩卷積神經網路啦
在本文中,我們將實現一個簡單的卷積神經網路模型。 我們將實現此模型以對MNIST資料集進行分類。我們要構建的神經網路的結構如下。 MNIST資料的手寫數字影象有10個類(從0到9)。 網路有2個卷積層,最後是2個全連線層。
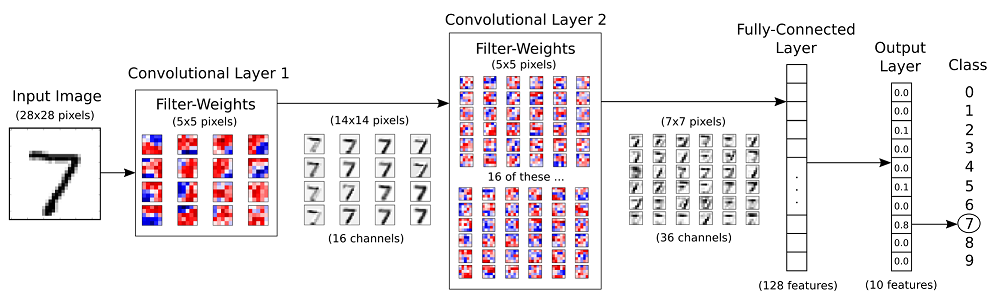
開始程式碼實現:
- 準備資料
MNIST是手寫數字的資料集,包含55,000個用於訓練的示例,5,000個用於驗證的示例和10,000個用於測試的示例。 這些數字已經過尺寸標準化,並且以固定尺寸的影象(28 x 28畫素)為中心,其值為0和1.每個影象已被展平並轉換為784個特徵的1-D陣列。 它也是深度學習的基準資料集。

先匯入必要的機器學習庫TensorFlow.NET和NumSharp.
using System;
using NumSharp;
using Tensorflow;
using TensorFlowNET.Examples.Utility;
using static Tensorflow.Python;
const int img_h = 28;
const int img_w = 28;
int n_classes = 10; // Number of classes, one class per digit
int n_channels = 1;
我們將編寫一個自動載入MNIST資料的函式,並以我們想要的形狀和格式返回它。 有一個MNIST資料助手可以讓這個任務變得列簡單一些。
Datasets mnist;
public void PrepareData()
{
mnist = MnistDataSet.read_data_sets("mnist", one_hot: true);
}
除了載入影象和相應標籤的功能外,我們還需要三個功能:
重新格式化:將資料重新格式化為卷積層可接受的格式。
private (NDArray, NDArray) Reformat(NDArray x, NDArray y) { var (img_size, num_ch, num_class) = (np.sqrt(x.shape[1]), 1, len(np.unique<int>(np.argmax(y, 1)))); var dataset = x.reshape(x.shape[0], img_size, img_size, num_ch).astype(np.float32); //y[0] = np.arange(num_class) == y[0]; //var labels = (np.arange(num_class) == y.reshape(y.shape[0], 1, y.shape[1])).astype(np.float32); return (dataset, y); }
隨機抽樣:隨機化影象及其標籤的順序。 在每個時期的開始,我們將重新隨機化資料樣本的順序,以確保訓練的模型對資料的順序不敏感。
private (NDArray, NDArray) randomize(NDArray x, NDArray y)
{
var perm = np.random.permutation(y.shape[0]);
np.random.shuffle(perm);
return (mnist.train.images[perm], mnist.train.labels[perm]);
}
獲取一批樣本:僅選擇由batch_size變數確定的少量影象(根據Stochastic Gradient Descent方法)。
private (NDArray, NDArray) get_next_batch(NDArray x, NDArray y, int start, int end)
{
var x_batch = x[$"{start}:{end}"];
var y_batch = y[$"{start}:{end}"];
return (x_batch, y_batch);
}
- 設定超引數
在訓練集中有大約55,000個影象,使用所有影象計算模型的梯度需要很長時間。 因此,我們通過隨機梯度下降在優化器的每次迭代中使用一小批影象。
epoch:所有訓練樣例的一個前向傳球和一個後傳傳球。
batch:一次前進/後退傳遞中的訓練樣例數。 批量大小越大,您需要的記憶體空間就越大。
iteration:一批前向傳遞和一組後向傳遞一組影象的訓練樣例。
int epochs = 10;
int batch_size = 100;
float learning_rate = 0.001f;
int display_freq = 200; // Frequency of displaying the training results
- 網路配置
第一卷積層:
int filter_size1 = 5; // Convolution filters are 5 x 5 pixels.
int num_filters1 = 16; // There are 16 of these filters.
int stride1 = 1; // The stride of the sliding window
第二卷積層:
int filter_size2 = 5; // Convolution filters are 5 x 5 pixels.
int num_filters2 = 32;// There are 32 of these filters.
int stride2 = 1; // The stride of the sliding window
完全連線層:
h1 = 128 # Number of neurons in fully-connected layer.
- 構建神經網路
讓我們做一些函式來幫助構建計算圖。
變數:我們需要定義兩個變數W和b來構造我們的線性模型。 我們使用適當大小和初始化的Tensorflow變數來定義它們。
// Create a weight variable with appropriate initialization
private RefVariable weight_variable(string name, int[] shape)
{
var initer = tf.truncated_normal_initializer(stddev: 0.01f);
return tf.get_variable(name,
dtype: tf.float32,
shape: shape,
initializer: initer);
}
// Create a bias variable with appropriate initialization
private RefVariable bias_variable(string name, int[] shape)
{
var initial = tf.constant(0f, shape: shape, dtype: tf.float32);
return tf.get_variable(name,
dtype: tf.float32,
initializer: initial);
}
2D卷積層:此層建立卷積核心,該卷積核心與層輸入卷積以產生輸出張量。
private Tensor conv_layer(Tensor x, int filter_size, int num_filters, int stride, string name)
{
return with(tf.variable_scope(name), delegate {
var num_in_channel = x.shape[x.NDims - 1];
var shape = new[] { filter_size, filter_size, num_in_channel, num_filters };
var W = weight_variable("W", shape);
// var tf.summary.histogram("weight", W);
var b = bias_variable("b", new[] { num_filters });
// tf.summary.histogram("bias", b);
var layer = tf.nn.conv2d(x, W,
strides: new[] { 1, stride, stride, 1 },
padding: "SAME");
layer += b;
return tf.nn.relu(layer);
});
}
max-pooling layer:池化層。
private Tensor max_pool(Tensor x, int ksize, int stride, string name)
{
return tf.nn.max_pool(x,
ksize: new[] { 1, ksize, ksize, 1 },
strides: new[] { 1, stride, stride, 1 },
padding: "SAME",
name: name);
}
flatten_layer:展開卷積層的輸出以往前饋入完全連線的層。
private Tensor flatten_layer(Tensor layer)
{
return with(tf.variable_scope("Flatten_layer"), delegate
{
var layer_shape = layer.TensorShape;
var num_features = layer_shape[new Slice(1, 4)].Size;
var layer_flat = tf.reshape(layer, new[] { -1, num_features });
return layer_flat;
});
}
完全連線層:神經網路由完全連線(密集)層的堆疊組成。 具有權重(W)和偏差(b)變數,完全連線的層被定義為啟用(W x X + b)。 完整的fc_layer函式如下:
private Tensor fc_layer(Tensor x, int num_units, string name, bool use_relu = true)
{
return with(tf.variable_scope(name), delegate
{
var in_dim = x.shape[1];
var W = weight_variable("W_" + name, shape: new[] { in_dim, num_units });
var b = bias_variable("b_" + name, new[] { num_units });
var layer = tf.matmul(x, W) + b;
if (use_relu)
layer = tf.nn.relu(layer);
return layer;
});
}
輸入層:現在我們需要定義適當的張量來輸入我們的模型。 佔位符變數是輸入影象和相應標籤的合適選擇。 這允許我們將輸入(影象和標籤)更改為TensorFlow圖。
with(tf.name_scope("Input"), delegate
{
// Placeholders for inputs (x) and outputs(y)
x = tf.placeholder(tf.float32, shape: (-1, img_h, img_w, n_channels), name: "X");
y = tf.placeholder(tf.float32, shape: (-1, n_classes), name: "Y");
});
佔位符y是與佔位符變數x中輸入的影象關聯的真實標籤的變數。 它包含任意數量的標籤,每個標籤是長度為num_classes的向量,為10。
網路層:在建立適當的輸入後,我們必須將它傳遞給我們的模型。 由於我們有神經網路,我們可以使用fc_layer方法堆疊多個完全連線的層。
var conv1 = conv_layer(x, filter_size1, num_filters1, stride1, name: "conv1");
var pool1 = max_pool(conv1, ksize: 2, stride: 2, name: "pool1");
var conv2 = conv_layer(pool1, filter_size2, num_filters2, stride2, name: "conv2");
var pool2 = max_pool(conv2, ksize: 2, stride: 2, name: "pool2");
var layer_flat = flatten_layer(pool2);
var fc1 = fc_layer(layer_flat, h1, "FC1", use_relu: true);
var output_logits = fc_layer(fc1, n_classes, "OUT", use_relu: false);
損失函式,優化器,精度,預測:建立網路後,我們必須計算損失並對其進行優化,我們必須計算預測和準確性。
with(tf.variable_scope("Train"), delegate
{
with(tf.variable_scope("Optimizer"), delegate
{
optimizer = tf.train.AdamOptimizer(learning_rate: learning_rate, name: "Adam-op").minimize(loss);
});
with(tf.variable_scope("Accuracy"), delegate
{
var correct_prediction = tf.equal(tf.argmax(output_logits, 1), tf.argmax(y, 1), name: "correct_pred");
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32), name: "accuracy");
});
with(tf.variable_scope("Prediction"), delegate
{
cls_prediction = tf.argmax(output_logits, axis: 1, name: "predictions");
});
});
初始化變數:我們必須呼叫變數初始化程式操作來初始化所有變數。
var init = tf.global_variables_initializer();
- 訓練
建立計算圖後,我們可以訓練我們的模型。 為了訓練模型,我們必須建立一個會話並在會話中執行圖。
// Number of training iterations in each epoch
var num_tr_iter = y_train.len / batch_size;
var init = tf.global_variables_initializer();
sess.run(init);
float loss_val = 100.0f;
float accuracy_val = 0f;
foreach (var epoch in range(epochs))
{
print($"Training epoch: {epoch + 1}");
// Randomly shuffle the training data at the beginning of each epoch
(x_train, y_train) = mnist.Randomize(x_train, y_train);
foreach (var iteration in range(num_tr_iter))
{
var start = iteration * batch_size;
var end = (iteration + 1) * batch_size;
var (x_batch, y_batch) = mnist.GetNextBatch(x_train, y_train, start, end);
// Run optimization op (backprop)
sess.run(optimizer, new FeedItem(x, x_batch), new FeedItem(y, y_batch));
if (iteration % display_freq == 0)
{
// Calculate and display the batch loss and accuracy
var result = sess.run(new[] { loss, accuracy }, new FeedItem(x, x_batch), new FeedItem(y, y_batch));
loss_val = result[0];
accuracy_val = result[1];
print($"iter {iteration.ToString("000")}: Loss={loss_val.ToString("0.0000")}, Training Accuracy={accuracy_val.ToString("P")}");
}
}
// Run validation after every epoch
var results1 = sess.run(new[] { loss, accuracy }, new FeedItem(x, x_valid), new FeedItem(y, y_valid));
loss_val = results1[0];
accuracy_val = results1[1];
print("---------------------------------------------------------");
print($"Epoch: {epoch + 1}, validation loss: {loss_val.ToString("0.0000")}, validation accuracy: {accuracy_val.ToString("P")}");
print("---------------------------------------------------------");
}
- 測試
訓練完成後,我們必須測試我們的模型,看看它在新資料集上的表現如何。
public void Test(Session sess)
{
var result = sess.run(new[] { loss, accuracy }, new FeedItem(x, x_test), new FeedItem(y, y_test));
loss_test = result[0];
accuracy_test = result[1];
print("---------------------------------------------------------");
print($"Test loss: {loss_test.ToString("0.0000")}, test accuracy: {accuracy_test.ToString("P")}");
print("---------------------------------------------------------");
}
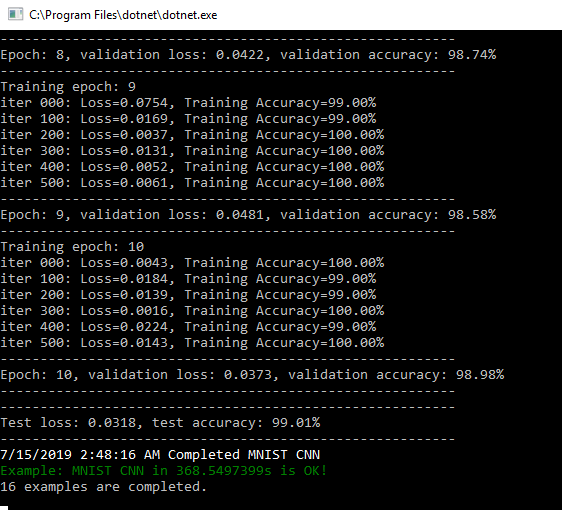
結果非常好,比上一篇完全連線神經網路效果高1個百分點。
如果你想要重複這個過程,請到Github參