
python聚類演算法解決方案(rest介面/mpp資料庫/json資料/下載圖片及資料)
阿新 • • 發佈:2019-08-28
1. 場景描述
一直做java,因專案原因,需要封裝一些經典的演算法到平臺上去,就一邊學習python,一邊網上尋找經典演算法程式碼,今天介紹下經典的K-means聚類演算法,演算法原理就不介紹了,只從程式碼層面進行介紹,包含:rest介面、連線mpp資料庫、回傳json資料、下載圖片及資料。
2. 解決方案
2.1 專案套路
(1)python經典演算法是單獨的伺服器部署,提供rest接口出來,供java平臺呼叫,互動的方式是http+json;
(2)資料從mpp資料庫-Greenplum中獲取;
(3)返回的資料包括三個:1是生成聚類圖片的地址;2是聚類專案完整資料地址;3是返回給前端的200條json預覽資料。
2.2 restapi類
分兩個類,第一個是restapi類,封裝rest介面類,其他的經典演算法在這裡都有對應的方法,是個公共類。
完整程式碼:
# -*- coding: utf-8 -*- from flask import Flask, request, send_from_directory from k_means import exec import logging app = Flask(__name__) #1.伺服器上更改為伺服器地址,用於存放資料 dirpath = 'E:\\ruanjianlaowang' #2. 測試連通性,軟體老王 @app.route('/') def index(): return "Hello, World!" #3. k-means演算法 軟體老王 @app.route('/getKmeansInfoByLaowang', methods=['POST']) def getKmeansInfoByLaowang(): try: result = exec(request.get_json(), dirpath) except IndexError as e: logging.error(str(e)) return 'exception:' + str(e) except KeyError as e: logging.error(str(e)) return 'exception:' + str(e) except ValueError as e: logging.error(str(e)) return 'exception:' + str(e) except Exception as e: logging.error(str(e)) return 'exception:' + str(e) else: return result #4.檔案下載(圖片及csv) @app.route("/<path:filename>") def getImages(filename): return send_from_directory(dirpath, filename, as_attachment=True) #5.啟動 if __name__ == '__main__': app.run(host="0.0.0.0", port=5000, debug=True)
程式碼說明:
使用的是第三方的flask提供的rest服務
(1)伺服器上更改為伺服器地址,用於存放資料
(2)測試連通性,軟體老王
(3)k-means演算法 軟體老王
(4)檔案下載(圖片及csv)
(5)啟動
2.3 k-means演算法類
完整程式碼:
import pandas as pd import dbgp as dbgp from pandas.io import json from numpy import * import matplotlib.pyplot as plt import numpy as np plt.switch_backend('agg') import logging # 執行 軟體老王 def exec(params, dirpath): #1.獲取引數,軟體老王 sql = params.get("sql") xlines = params.get("xlines") ylines = params.get("ylines") xlinesname = params.get("xlinesname") ylinesname = params.get("ylinesname") grouplinesname = params.get("grouplinesname") times = int(params.get("times")) groupnum = int(params.get("groupnum")) url = params.get("url") name = params.get("name") #2. 校驗是否為空,軟體老王 flag = checkparam(sql, xlines, ylines, times, groupnum) if not flag is None and len(flag) != 0: return flag #3. 從資料庫獲取資料,軟體老王 try: data = dbgp.queryGp(sql) except IndexError: return sql except KeyError: return sql except ValueError: return sql except Exception: return sql if data.empty: return "exception:此資料集無資料,請確認後重試" #4 呼叫第三方sklearn的KMeans聚類演算法,軟體老王 # data_zs = 1.0 * (data - data.mean()) / data.std() 資料標準化,不需要標準話 from sklearn.cluster import KMeans model = KMeans(n_clusters=groupnum, n_jobs=4, max_iter=times) model.fit(data) # 開始聚類 return export(model, data, data, url, dirpath, name,grouplinesname,xlines, ylines,xlinesname,ylinesname) # 5.生成匯出excel 軟體老王 def export(model, data, data_zs, url, dirpath, name,grouplinesname,xlines, ylines,xlinesname,ylinesname): # #詳細輸出原始資料及其類別 detail_data = pd.DataFrame().append(data) if not grouplinesname is None and len(grouplinesname) != 0: detail_data.columns = grouplinesname.split(',') r_detail_new = pd.concat([detail_data, pd.Series(model.labels_, index=detail_data.index)], axis=1) # 詳細輸出每個樣本對應的類別 r_detail_new.columns = list(detail_data.columns) + [u'聚類類別'] # 重命名錶頭 outputfile = dirpath + name + '.csv' r_detail_new.to_csv(outputfile, encoding='utf_8_sig') # 儲存結果 #重命名錶頭 r1 = pd.Series(model.labels_).value_counts() # 統計各個類別的數目 r2 = pd.DataFrame(model.cluster_centers_) # 找出聚類中心 r = pd.concat([r2, r1], axis=1) # 橫向連線(0是縱向),得到聚類中心對應的類別下的數目 r.columns = list(data.columns) + [u'類別數目'] # 重命名錶頭 return generateimage(r, data_zs, url, dirpath, name,model,xlines, ylines,xlinesname,ylinesname) #6.生成圖片及返回json,軟體老王 def generateimage(r, data_zs, url, dirpath, name,model,xlines, ylines,xlinesname,ylinesname): image = dirpath + name + '.jpg' #6.1 中文處理,軟體老王 plt.rcParams['font.sans-serif'] = ['simhei'] plt.rcParams['font.family'] = 'sans-serif' plt.rcParams['axes.unicode_minus'] = False # 6.2 畫圖,生成圖片,軟體老王 labels = model.labels_ centers = model.cluster_centers_ data_zs['label'] = labels data_zs['label'] = data_zs['label'].astype(np.int) # 圖示集合 markers = ['o', 's', '+', 'x', '^', 'v', '<', '>'] colors = ['b', 'c', 'g', 'k', 'm', 'r', 'y'] symbols = [] for m in markers: for c in colors: symbols.append((m, c)) # 畫每個類別的散點及質心 for i in range(0, len(centers)): df_i = data_zs.loc[data_zs['label'] == i] symbol = symbols[i] center = centers[i] x = df_i[xlines].values.tolist() y = df_i[ylines].values.tolist() plt.scatter(x, y, marker=symbol[0], color=symbol[1], s=10) plt.scatter(center[0], center[1], marker='*', color=symbol[1], s=50) plt.title(name) plt.xlabel(xlinesname) plt.ylabel(ylinesname) plt.savefig(image, dpi=150) plt.clf() plt.close(0) # 6.3 返回json資料給前端展示,軟體老王 result = {} result['image_url'] = url + '/' + name + '.jpg' result['details_url'] = url + '/' + name + '.csv' result['data'] = r[:200] #顯示200,多的話,相當於預覽 result = json.dumps(result, ensure_ascii=False) result = result.replace('\\', '') return result def checkparam(sql, xlines, ylines, times, groupnum): if sql is None or sql.strip() == '' or len(sql.strip()) == 0: return "資料集或聚類資料列,不能為空" if xlines is None or xlines.strip() == '' or len(xlines.strip()) == 0: return "X軸,不能為空" if ylines is None or ylines.strip() == '' or len(ylines.strip()) == 0: return "Y軸,不能為空" if times is None or times <= 0: return "聚類個數,不能為空或小於等於0" if groupnum is None or groupnum <= 0: return "迭代次數,不能為空或小於等於0"
程式碼說明:
(1)獲取引數,軟體老王;
(2)校驗是否為空,軟體老王;
(3)從資料庫獲取資料,軟體老王;
(4)第三方sklearn的KMeans聚類演算法,軟體老王;
(5)生成匯出excel 軟體老王
(6)生成圖片及返回json,軟體老王
(6.1) 中文處理,軟體老王
(6.2) 畫圖,生成圖片,軟體老王
(6.3) 返回json資料給前端展示,軟體老王
2.4 執行效果
2.4.1 json返回
{"image_url":"http://10.192.168.1:5000/ruanjianlaowang_65652.jpg","details_url":"http://10.192.168.1:5000/ruanjianlaowang_65652.csv","data":{"empno":{"0":7747.2,"1":7699.625,"2":7839.0},"mgr":{"0":7729.8,"1":7745.25,"2":7566.0},"sal":{"0":2855.0,"1":1218.75,"2":5000.0},"comm":{"0":29.5110766,"1":117.383964625,"2":31.281453},"deptno":{"0":20.0,"1":25.0,"2":10.0},"類別數目":{"0":5,"1":8,"2":1}}}2.4.2 返回圖片
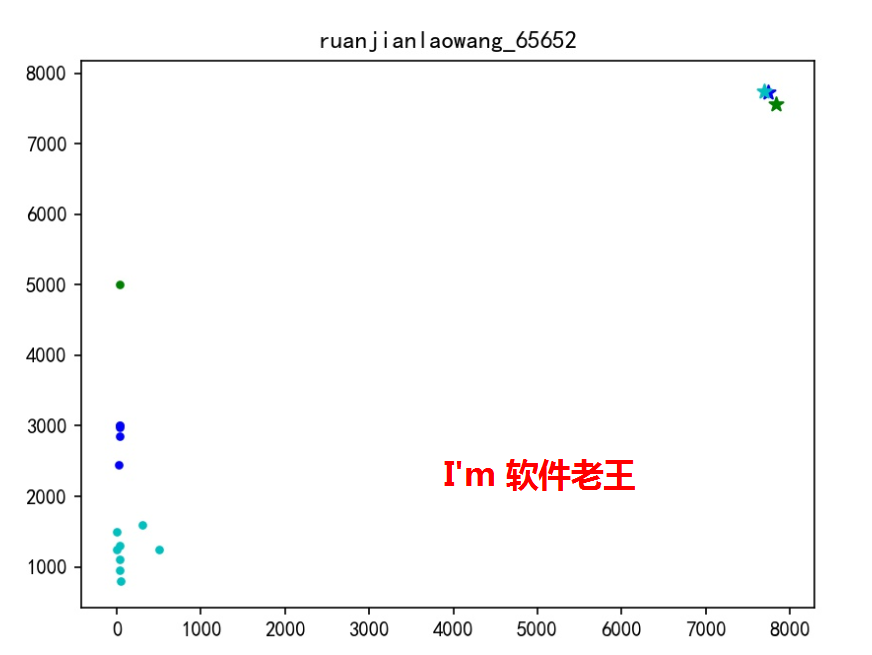
2.4.3 返回的資料

另外說明: 目前專案環境上用的是8核16G的虛擬機器,執行資料量是30萬,執行狀況良好。
I’m 「軟體老王」,如果覺得還可以的話,關注下唄,後續更新秒知!歡迎討論區、同名公眾號留言交流