
(R/Python)t-SNE聚類演算法實踐指南
首發連結 :
https://yq.aliyun.com/articles/70733
作者介紹:Saurabh.jaju2
Saurabh是一名資料科學家和軟體工程師,熟練分析各種資料集和開發智慧應用程式。他目前正在加州大學伯克利分校攻讀資訊和資料科學碩士學位,熱衷於開發基於資料科學的智慧資源管理系統。
介紹
許多資料科學家經常面對的問題之一:假設有一個包含數百個特徵(變數)的資料集,且對資料所屬的域沒有任何瞭解,需要對該資料集識別其隱藏狀態、探索並分析。本文將介紹一種非常強大的方法來解決該問題。
關於PCA
現實中大多數人會使用PCA進行降維和視覺化,但為什麼不選擇比PCA更先進的東西呢?關於
本文內容
1 什麼是t-SNE?
2 什麼是降維?
3 t-SNE如何在維數降低演算法空間中擬合
4 t-SNE演算法的細節
5 t-SNE實際上是做什麼?
6 用例
7 t-SNE與其他降維演算法相比
8 示例實現
R語言
Python語言
9 應用方面
資料科學家
機器學習駭客
資料科學愛好者
10 常見錯誤
1 什麼是t-SNE
(t-SNE)t分佈隨機鄰域嵌入是一種用於探索高維資料的非線性降維演算法。它將多維資料對映到適合於人類觀察的兩個或多個維度。

2 什麼是降維?
簡而言之,降維就是用2維或3維表示多維資料(彼此具有相關性的多個特徵資料)的技術,利用降維演算法,可以顯式地表現資料。
3 t-SNE如何在降維演算法空間中擬合
常用的降維演算法有:
1 PCA(線性)
2 t-SNE(非引數/非線性)
3 Sammon對映(非線性)
4 Isomap(非線性)
5 LLE(非線性)
6 CCA(非線性)
7 SNE(非線性)
8 MVU(非線性)
9 拉普拉斯特徵圖(非線性)
只需要研究上述演算法中的兩種——PCA和t-SNE。
PCA的侷限性
PCA是一種線性演算法,它不能解釋特徵之間的複雜多項式關係。而
線性降維演算法的一個主要問題是不相似的資料點放置在較低維度表示為相距甚遠。但為了在低維度用非線性流形表示高維資料,相似資料點必須表示為非常靠近,這不是線性降維演算法所能做的。
4 t-SNE演算法的細節
4.1 演算法
步驟1:
隨機鄰接嵌入(SNE)通過將資料點之間的高維歐幾里得距離轉換為表示相似性的條件概率而開始,資料點xi、xj之間的條件概率pj|i由下式給出:
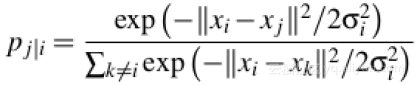
其中σi是以資料點xi為中心的高斯方差。
步驟2:
對於高維資料點xi和xj的低維對應點yi和yj而言,可以計算類似的條件概率qj|i
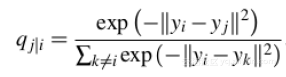
SNE試圖最小化條件概率的差異。
步驟3:
為了測量條件概率差的和最小值,SNE使用梯度下降法最小化KL距離。而SNE的代價函式關注於對映中資料的區域性結構,優化該函式是非常困難的,而t-SNE採用重尾分佈,以減輕擁擠問題和SNE的優化問題。
步驟4:
定義困惑度:
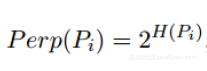
其中H(Pi)是夏農熵
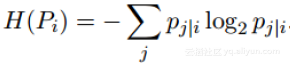
4.2 時間和空間複雜性
演算法計算對應的是條件概率,並試圖最小化較高和較低維度的概率差之和,這涉及大量的計算,對系統資源要求高。t-SNE的複雜度隨著資料點數量有著時間和空間二次方。
5 t-SNE實際上是做什麼?
t-SNE非線性降維演算法通過基於具有多個特徵的資料點的相似性識別觀察到的簇來在資料中找到模式。本質上是一種降維和視覺化技術。另外t-SNE的輸出可以作為其他分類演算法的輸入特徵。
6用例
t-SNE可用於幾乎所有高維資料集,廣泛應用於影象處理,自然語言處理,基因組資料和語音處理。例項有:面部表情識別[2]、識別腫瘤亞群[3]、使用wordvec進行文字比較[4]等。
7 t-SNE與其他降維演算法相比
基於所實現的精度,將t-SNE與PCA和其他線性降維模型相比,結果表明t-SNE能夠提供更好的結果。這是因為演算法定義了資料的區域性和全域性結構之間的軟邊界。
8示例實現
在MNIST手寫數字資料庫上實現t-SNE演算法。
“Rtsne”包在R中具有t-SNE的實現。“Rtsne”包可以使用在R控制檯中鍵入的以下命令安裝在R中:
超引數調整

程式碼
MNIST資料可從MNIST網站下載,並可轉換為具有少量程式碼的csv檔案。
## calling the installed package
train<‐ read.csv(file.choose()) ## Choose the train.csv file downloaded from the link above
library(Rtsne)
## Curating the database for analysis with both t‐SNE and PCA
Labels<‐train$label
train$label<‐as.factor(train$label)
## for plotting
colors = rainbow(length(unique(train$label)))
names(colors) = unique(train$label)
## Executing the algorithm on curated data
tsne <‐ Rtsne(train[,‐1], dims = 2, perplexity=30, verbose=TRUE, max_iter = 500)
exeTimeTsne<‐ system.time(Rtsne(train[,‐1], dims = 2, perplexity=30, verbose=TRUE, max_iter = 50
0))
## Plotting
plot(tsne$Y, t='n', main="tsne")
text(tsne$Y, labels=train$label, col=colors[train$label])實現時間
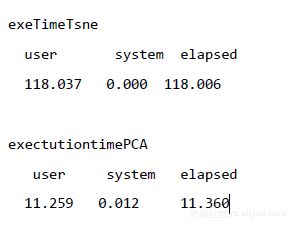
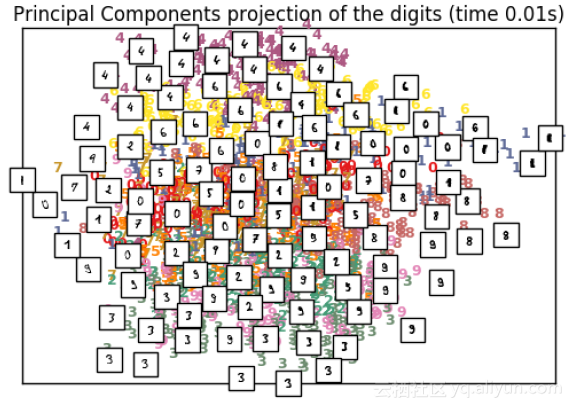
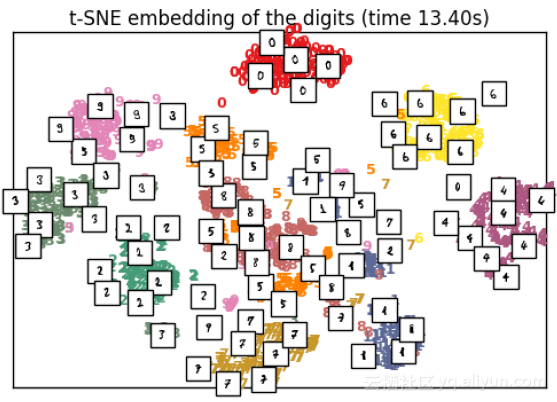
可以看出,與PCA相比,t-SNE在相同樣本大小的資料上執行需要相當長的時間。
解釋結果
以下圖用於探索性分析。輸出x和y座標以及成本可以用作分類演算法中的特徵。
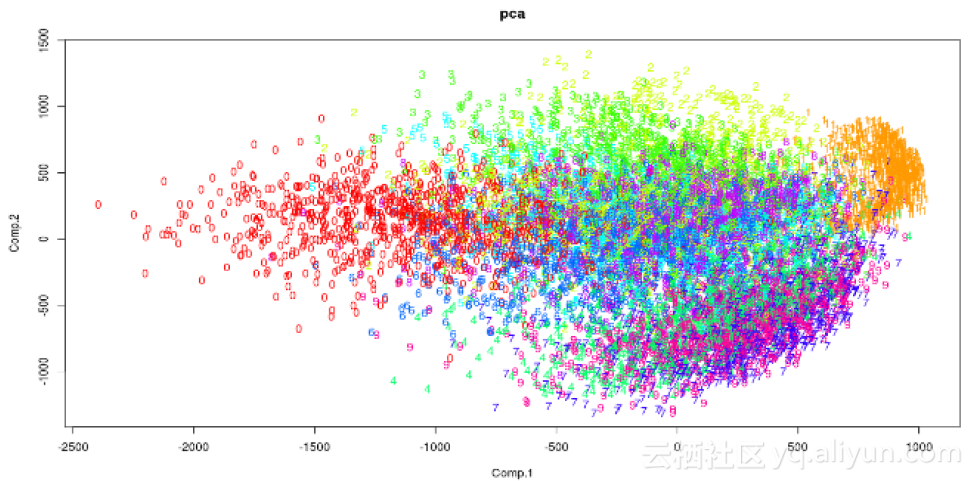
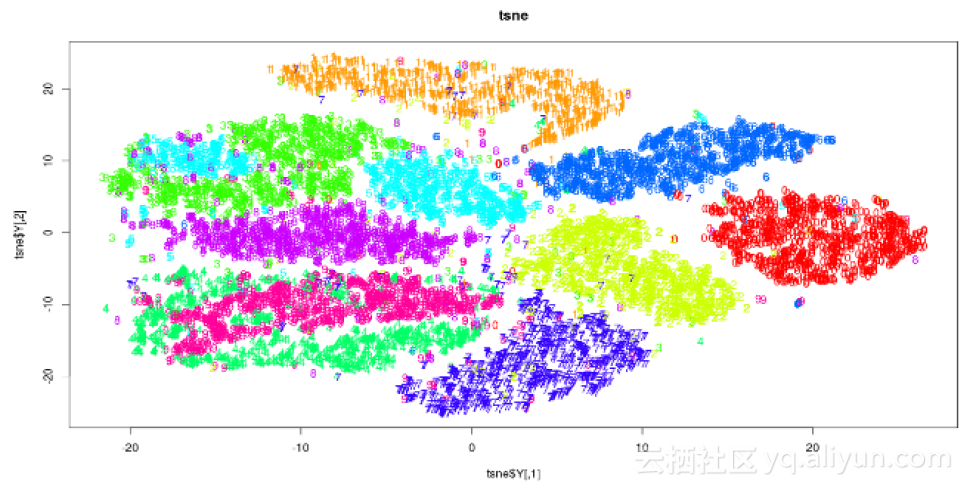
2 Python語言
t-SNE演算法可以從sklearn包中訪問。
超引數調整
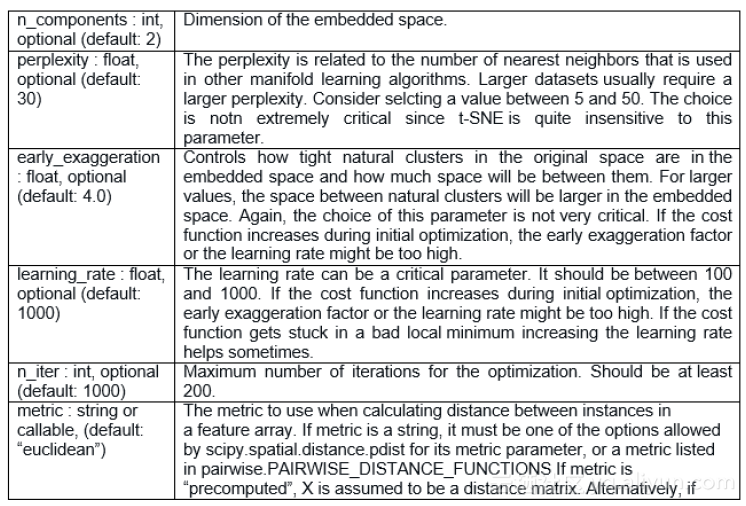
程式碼
以下程式碼來自sklearn網站上的sklearn示例。
程式碼1
實現時間
## importing the required packages
from time import time
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import offsetbox
from sklearn import (manifold, datasets, decomposition, ensemble,
discriminant_analysis, random_projection)
## Loading and curating the data
digits = datasets.load_digits(n_class=10)
X = digits.data
y = digits.target
n_samples, n_features = X.shape
n_neighbors = 30
## Function to Scale and visualize the embedding vectors
def plot_embedding(X, title=None):
x_min, x_max = np.min(X, 0), np.max(X, 0)
X = (X ‐ x_min) / (x_max ‐ x_min)
plt.figure()
ax = plt.subplot(111)
for i in range(X.shape[0]):
plt.text(X[i, 0], X[i, 1], str(digits.target[i]),
color=plt.cm.Set1(y[i] / 10.),
fontdict={'weight': 'bold', 'size': 9})
if hasattr(offsetbox, 'AnnotationBbox'):
## only print thumbnails with matplotlib > 1.0
shown_images = np.array([[1., 1.]]) # just something big
for i in range(digits.data.shape[0]):
dist = np.sum((X[i] ‐ shown_images) ** 2, 1)
if np.min(dist) < 4e‐3:
## don't show points that are too close
continue
shown_images = np.r_[shown_images, [X[i]]]
imagebox = offsetbox.AnnotationBbox(
offsetbox.OffsetImage(digits.images[i], cmap=plt.cm.gray_r),
X[i])
ax.add_artist(imagebox)
plt.xticks([]), plt.yticks([])
if title is not None:
plt.title(title)
#‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐
## Plot images of the digits
n_img_per_row = 20
img = np.zeros((10 * n_img_per_row, 10 * n_img_per_row))
for i in range(n_img_per_row):
ix = 10 * i + 1
for j in range(n_img_per_row):
iy = 10 * j + 1
img[ix:ix + 8, iy:iy + 8] = X[i * n_img_per_row + j].reshape((8, 8))
plt.imshow(img, cmap=plt.cm.binary)
plt.xticks([])
plt.yticks([])
plt.title('A selection from the 64‐dimensional digits dataset')
## Computing PCA
print("Computing PCA projection")
t0 = time()
X_pca = decomposition.TruncatedSVD(n_components=2).fit_transform(X)
plot_embedding(X_pca,
"Principal Components projection of the digits (time %.2fs)" %
(time() ‐ t0))
## Computing t‐SNE
print("Computing t‐SNE embedding")
tsne = manifold.TSNE(n_components=2, init='pca', random_state=0)
t0 = time()
X_tsne = tsne.fit_transform(X)
plot_embedding(X_tsne,
"t‐SNE embedding of the digits (time %.2fs)" %
(time() ‐ t0))
plt.show()
9 應用方面
9.1資料科學家
對於資料科學家來說,使用t-SNE的主要問題是演算法的黑盒型別性質。使用該演算法的最佳方法是將其用於探索資料分析。
9.2機器學習駭客
將資料集縮減為2或3維,並使用非線性堆疊器將其堆疊。可以使用XGboost提高t-SNE向量以獲得更好的結果。
9.3資料科學愛好者
對於開始使用資料科學的資料科學愛好者來說,這種演算法在研究和效能增強方面提供了最好的機會。針對各種NLP問題和影象處理應用方面實施t-SNE的研究是一個尚未開發的領域。
10常見錯誤
以下是在解釋t-SNE的結果時要避免的幾個常見錯誤:
1 為了使演算法正確執行,困惑度應小於點的數量。一般設定為5-50。
2 具有相同超引數的不同執行可能產生不同的結果。
3 任何t-SNE圖中的簇大小不得用於標準偏差,色散或任何其他類似的評估。
4 簇之間的距離可以改變。一個茫然性不能優化所有簇的距離。
5 可以在隨機噪聲中找到模式。
6 不同的困惑水平可以觀察到不同的簇形狀。
7 不能基於單個t-SNE圖進行分析拓撲,在進行任何評估之前必須觀察多個圖。