
通過機器學習的線性迴歸演算法預測股票走勢(用Python實現)
在本人的新書裡,將通過股票案例講述Python知識點,讓大家在學習Python的同時還能掌握相關的股票知識,所謂一舉兩得。這裡給出以線性迴歸演算法預測股票的案例,以此講述通過Python的sklearn庫實現線性迴歸預測的技巧。
本文先講以波士頓房價資料為例,講述線性迴歸預測模型的搭建方式,隨後將再這個基礎上,講述以線性預測模型預測股票的實現程式碼。本博文是從本人的新書裡摘取的,新書預計今年年底前出版,敬請大家關注。
正文開始(長文預警)
------------------------------------------------------------------------------------------------------------------------------------------------------
1 波士頓房價資料分析
安裝好Python的Sklearn庫後,在安裝包下的路徑中就能看到描述波士頓房價的csv檔案,具體路徑是“python安裝路徑\Lib\site-packages\sklearn\datasets\data”,在這個目錄中還包含了Sklearn庫會用到的其他資料檔案,本節用到的是包含在boston_house_prices.csv檔案中的波士頓房價資訊。開啟這個檔案,可以看到如圖所示的資料。

第1行的506表示該檔案中包含506條樣本資料,即有506條房價資料,而13表示有13個影響房價的特徵值,即從A列到M列這13列的特徵值資料會影響第N列MEDV(即房價值),在表13.1中列出了部分列的英文標題及其含義。
波士頓房價檔案部分中英文標題一覽表
|
標題名 |
中文含義 |
標題名 |
中文含義 |
|
CRIM |
城鎮人均犯罪率 |
DIS |
到波士頓五個中心區域的加權距離 |
|
ZN |
住宅用地超過某數值的比例 |
RAD |
輻射性公路的接近指數 |
|
INDUS |
城鎮非零售商用土地的比例 |
TAX |
每 10000 美元的全值財產稅率 |
|
CHAS |
查理斯河相關變數,如邊界是河流則為1,否則為0 |
PTRATIO |
城鎮師生比例 |
|
NOX |
一氧化氮濃度 |
MEDV |
是自住房的平均房價 |
|
RM |
住宅平均房間數 |
|
|
|
AGE |
1940年之前建成的自用房屋比例 |
|
|
從表中可以看到,波士頓房價的數值(即MEDV)和諸如“住宅用地超過某數值的比例”等13個特徵值有關。而線性迴歸要解決的問題是,量化地找出這些特徵值和目標值(即房價)的線性關係,即找出如下的k1到k13係數的數值和b這個常量值。
MEDV = k1*CRIM + k2*ZN + … + k13*LITAT + b
上述引數有13個,為了簡化問題,先計算1個特徵值(DIS)與房價(MEDV)的關係,然後在此基礎上講述13個特徵值與房價關係的計算方式。
如果只有1個特徵值DIS,它與房價的線性關係表示式如下所示。在計算出k1和b的值以後,如果再輸入對應DIS值,即可據此計算MEDV的值,以此實現線性迴歸的預測效果。
MEDV = k1*DIS + b
2 以波士頓房價資料為案例,搭建含一個特徵值的線性預測模型
在下面的OneParamLR.py範例程式中,通過呼叫Sklearn庫中的方法,以訓練加預測的方式,推算出一個特徵值(DIS)與目標值(MEDV,即房價)的線性關係。
1 # !/usr/bin/env python 2 # coding=utf-8 3 import numpy as np 4 import pandas as pd 5 import matplotlib.pyplot as plt 6 from sklearn import datasets 7 from sklearn.linear_model import LinearRegression
在上述程式碼中匯入了必要的庫,其中第6行和第7行用於匯入sklearn相關庫。
8 # 從檔案中讀資料,並轉換成DataFrame格式 9 dataset=datasets.load_boston() 10 data=pd.DataFrame(dataset.data) 11 data.columns=dataset.feature_names # 特徵值 12 data['HousePrice']=dataset.target # 房價,即目標值 13 # 這裡單純計算離中心區域的距離和房價的關係 14 dis=data.loc[0:data['DIS'].size-1,'DIS'].as_matrix() 15 housePrice=data.loc[0:data['HousePrice'].size-1,'HousePrice'].as_matrix()
在第9行中,載入了Sklearn庫下的波士頓房價資料檔案,並賦值給dataset物件。在第10行通過dataset.data讀取了檔案中的資料。在第11行通過dataset.feature_name讀取了特徵值,如前文所述,data.columns物件中包含了13個特徵值。在第12行通過dataset.target讀取目標值,即MEDV列的房價,並把目標值設定到data的HousePrice列中。
在第14行讀取了DIS列的資料,並呼叫as_matrix方法把讀到的資料轉換成矩陣中一列的格式,在第15行中,是用同樣的方法把房價數值轉換成矩陣中列的格式。
16 # 轉置一下,否則資料是豎排的 17 dis=np.array([dis]).T 18 housePrice=np.array([housePrice]).T 19 # 訓練線性模型 20 lrTool=LinearRegression() 21 lrTool.fit(dis,housePrice) 22 # 輸出係數和截距 23 print(lrTool.coef_) 24 print(lrTool.intercept_)
由於當前在dis和housePrice變數中儲存是的“列”形式的資料,因此在第16行和第17行中,需要把它們轉換成行格式的資料。
在第20行中,通過呼叫LinearRegression方法建立了一個用於線性迴歸分析的lrTool物件,在第21行中,通過呼叫fit方法進行基於線性迴歸的訓練。這裡訓練的目的是,根據傳入的一組特徵值dis和目標值MEDV,推算出MEDV = k1*DIS + b公式中的k1和b的值。
呼叫fit方法進行訓練後,ltTool物件就內含了係數和截距等線性迴歸相關的引數,通過第23行的列印語句輸出了係數,即引數k1的值,而第24行的列印語句輸出了截距,即引數b的值。
25 # 畫圖顯示
26 plt.scatter(dis,housePrice,label='Real Data')
27 plt.plot(dis,lrTool.predict(dis),c='R',linewidth='2',label='Predict')
28 # 驗證資料
29 print(dis[0])
30 print(lrTool.predict(dis)[0])
31 print(dis[2])
32 print(lrTool.predict(dis)[2])
33
34 plt.legend(loc='best') # 繪製圖例
35 plt.rcParams['font.sans-serif']=['SimHei']
36 plt.title("DIS與房價的線性關係")
37 plt.xlabel("DIS")
38 plt.ylabel("HousePrice")
39 plt.show()
在第26行中,通過呼叫scatter方法繪製出x值是DIS,y值是房價的諸多散點,第27行則是呼叫plot方法繪製出DIS和預測結果的關係,即一條直線。
之後就是用Matplotlib庫中的方法繪製出x軸y軸文字和圖形標題等資訊。執行上述程式碼,即可看到如圖所示的結果。

圖中各個點表示真實資料,每個點的x座標是DIS值,y座標是房價。而紅線則表示根據當前DIS值,通過線性迴歸預測出的房價結果。
下面通過輸出的資料,進一步說明圖中以紅線形式顯示的預測資料的含義。通過程式碼的第23行和24行輸出了係數和截距,結果如下。
[[1.09161302]]
[18.39008833]
即房價和DIS滿足如下的一次函式關係:MEDV = 1.09161302*DIS + 18.39008833。
從第29行到第32行輸出了兩組DIS和預測房價資料,每兩行是一組,結果如下。
[4.09]
[22.85478557]
[4.9671]
[23.81223934]
在已經得到的公式中,MEDV = 1.09161302*DIS + 18.39008833,把第1行的4.09代入DIS,把第2行的22.85478557代入MEDV,發現結果吻合。同理,把第3行的DIS和第4行MEDV值代入上述公式,結果也吻合。
也就是說,通過基於線性迴歸的fit方法,訓練了lrTool物件,使之包含了相關引數,這樣如果輸入其他的DIS值,那麼ltTool物件根據相關引數也能算出對應的房價值。從視覺化的效果來看,用DIS預測MEDV房價的效果並不好,原因是畢竟只用了其中一個特徵值。不過,通過這個範例程式,還是可以看出基於線性迴歸實現預測的一般步驟:根據一組(506條)資料的特徵值(本範例中是DIS)和目標值(房價),呼叫fit方法訓練ltTool等線性迴歸中的物件,讓它包含相關係數,隨後再呼叫predict方法,根據由相關係數組成的公式,通過計算預測目標結果。
3 以波士頓房價資料為案例,實現基於多個特徵值的線性迴歸
如果要用到波士頓房價範例中13個特徵值來進行預測,那麼對應的公式如下,這裡要做的工作是,通過fit方法,計算如下的k1到k13係數以及b截距值。
MEDV = k1*CRIM + k2*ZN + … + k13*LITAT + b
在下面的MoreParamLR.py範例程式中,實現用13個特徵值預測房價的功能。
1 # !/usr/bin/env python 2 # coding=utf-8 3 from sklearn import datasets 4 from sklearn.linear_model import LinearRegression 5 import matplotlib.pyplot as plt 6 # 載入資料 7 dataset = datasets.load_boston() 8 # 特徵值集合,不包括目標值房價 9 featureData = dataset.data 10 housePrice = dataset.target
在第7行中載入了波士頓房價的資料,在第9行和第10行分別把13個特徵值和房價目標值放入featureData和housePrice這兩個變數中。
11 lrTool = LinearRegression() 12 lrTool.fit(featureData, housePrice) 13 # 輸出係數和截距 14 print(lrTool.coef_) 15 print(lrTool.intercept_)
上述程式碼和前文推算一個特徵值和目標值關係的程式碼很相似,只不過在第12行的fit方法中,傳入的特徵值是13個,而不是1個。在第14行和第15行的程式語句同樣輸出了各項係數和截距數值。
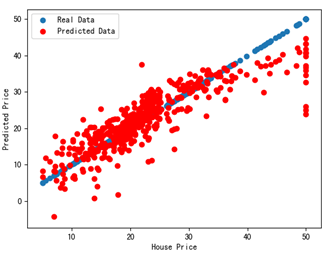
16 # 畫圖顯示
17 plt.scatter(housePrice,housePrice,label='Real Data')
18 plt.scatter(housePrice,lrTool.predict(featureData),c='R',label='Predicted Data')
19 plt.legend(loc='best') # 繪製圖例
20 plt.rcParams['font.sans-serif']=['SimHei']
21 plt.xlabel("House Price")
22 plt.ylabel("Predicted Price")
23 plt.show()
在第17行繪製了x座標和y座標都是房價值的雜湊點,這些點表示原始資料,在第19行繪製雜湊點時,x座標是原始房價,y座標是根據線性迴歸推算出的房價。
執行上述程式碼,即可看到如圖所示的結果。其中藍色雜湊點表示真實資料,紅色雜湊點表示預測出的資料,和圖13-4相比,預測出的房價結果資料更靠近真實房價資料,這是因為這次用了13個特徵值來預測,而之前只用了其中一個特徵資料來預測。
另外,從控制檯中可以看到由第14行和15行的程式語句打印出的各項係數和截距。
1 [-1.08011358e-01 4.64204584e-02 2.05586264e-02 2.68673382e+00 -1.77666112e+01 3.80986521e+00 6.92224640e-04 -1.47556685e+00 3.06049479e-01 -1.23345939e-02 -9.52747232e-01 9.31168327e-03 -5.24758378e-01]
2 36.459488385089855
其中,第1行表示13個特徵值的係數,而第2行表示截距。代入上述係數,即可看到如下的13個特徵值與目標房價的對應關係——預測公式。得出如下的公式後,再輸入其他的13個特徵值,即可預測出對應的房價。
MEDV = -1.08011358e-01*CRIM + 4.64204584e-02*ZN + … + -5.24758378e-01*LITAT + 36.459488385089855
4 激動人心的時刻,預測股票價格
在這裡,將在下面的predictStockByLR.py範例程式中,根據股票歷史的開盤價、收盤價和成交量等特徵值,從數學角度來預測股票未來的收盤價。
1 # !/usr/bin/env python
2 # coding=utf-8
3 import pandas as pd
4 import numpy as np
5 import math
6 import matplotlib.pyplot as plt
7 from sklearn.linear_model import LinearRegression
8 from sklearn.model_selection import train_test_split
9 # 從檔案中獲取資料
10 origDf = pd.read_csv('D:/stockData/ch13/6035052018-09-012019-05-31.csv',encoding='gbk')
11 df = origDf[['Close', 'High', 'Low','Open' ,'Volume']]
12 featureData = df[['Open', 'High', 'Volume','Low']]
13 # 劃分特徵值和目標值
14 feature = featureData.values
15 target = np.array(df['Close'])
第10行的程式語句從包含股票資訊的csv檔案中讀取資料,在第14行設定了特徵值是開盤價、最高價、最低價和成交量,同時在第15行設定了要預測的目標列是收盤價。在後續的程式碼中,需要將計算出開盤價、最高價、最低價和成交量這四個特徵值和收盤價的線性關係,並在此基礎上預測收盤價。
16 # 劃分訓練集,測試集 17 feature_train, feature_test, target_train ,target_test = train_test_split(feature,target,test_size=0.05) 18 pridectedDays = int(math.ceil(0.05 * len(origDf))) # 預測天數 19 lrTool = LinearRegression() 20 lrTool.fit(feature_train,target_train) # 訓練 21 # 用測試集預測結果 22 predictByTest = lrTool.predict(feature_test)
第17行的程式語句通過呼叫train_test_split方法把包含在csv檔案中的股票資料分成訓練集和測試集,這個方法前兩個引數分別是特徵列和目標列,而第三個引數0.05則表示測試集的大小是總量的0.05。該方法返回的四個引數分別是特徵值的訓練集、特徵值的測試集、要預測目標列的訓練集和目標列的測試集。
第18行的程式語句計算了要預測的交易日數,在第19行中構建了一個線性迴歸預測的物件,在第20行是呼叫fit方法訓練特徵值和目標值的線性關係,請注意這裡的訓練是針對訓練集的,在第22行中,則是用特徵值的測試集來預測目標值(即收盤價)。也就是說,是用多個交易日的股價來訓練lrTool物件,並在此基礎上預測後續交易日的收盤價。至此,上面的程式程式碼完成了相關的計算工作。
23 # 組裝資料 24 index=0 25 # 在前95%的交易日中,設定預測結果和收盤價一致 26 while index < len(origDf) - pridectedDays: 27 df.ix[index,'predictedVal']=origDf.ix[index,'Close'] 28 df.ix[index,'Date']=origDf.ix[index,'Date'] 29 index = index+1 30 predictedCnt=0 31 # 在後5%的交易日中,用測試集推算預測股價 32 while predictedCnt<pridectedDays: 33 df.ix[index,'predictedVal']=predictByTest[predictedCnt] 34 df.ix[index,'Date']=origDf.ix[index,'Date'] 35 predictedCnt=predictedCnt+1 36 index=index+1
在第26行到第29行的while迴圈中,在第27行把訓練集部分的預測股價設定成收盤價,並在第28行設定了訓練集部分的日期。
在第32行到第36行的while迴圈中,遍歷了測試集,在第33行的程式語句把df中表示測試結果的predictedVal列設定成相應的預測結果,同時也在第34行的程式語句逐行設定了每條記錄中的日期。
37 plt.figure() 38 df['predictedVal'].plot(color="red",label='predicted Data') 39 df['Close'].plot(color="blue",label='Real Data') 40 plt.legend(loc='best') # 繪製圖例 41 # 設定x座標的標籤 42 major_index=df.index[df.index%10==0] 43 major_xtics=df['Date'][df.index%10==0] 44 plt.xticks(major_index,major_xtics) 45 plt.setp(plt.gca().get_xticklabels(), rotation=30) 46 # 帶網格線,且設定了網格樣式 47 plt.grid(linestyle='-.') 48 plt.show()
在完成資料計算和資料組裝的工作後,從第37行到第48行程式程式碼的最後,實現了視覺化。
第38行和第39行的程式程式碼分別繪製了預測股價和真實收盤價,在繪製的時候設定了不同的顏色,也設定了不同的label標籤值,在第40行通過呼叫legend方法,根據收盤價和預測股價的標籤值,繪製了相應的圖例。
從第42行到第45行設定了x軸顯示的標籤文字是日期,為了不讓標籤文字顯示過密,設定了“每10個日期裡只顯示1個”的顯示方式,並且在第47行設定了網格線的效果,最後在第48行通過呼叫show方法繪製出整個圖形。執行本範例程式,即可看到如圖所示的結果。

從圖中可以看出,藍線表示真實的收盤價(圖中完整的線),紅線表示預測股價(圖中靠右邊的線。因為本書黑白印刷的原因,在書中讀者看不到藍色和紅色,請讀者在自己的計算機上執行這個範例程式即可看到紅藍兩色的線)。雖然預測股價和真實價之間有差距,但漲跌的趨勢大致相同。而且在預測時沒有考慮到漲跌停的因素,所以預測結果的漲跌幅度比真實資料要大。
5 系列文總結和版權說明
本文是給程式設計師加財商系列,之前的系列文如下:
在我的新書裡,嘗試著用股票案例講述Python爬蟲大資料視覺化等知識 以股票RSI指標為例,學習Python傳送郵件功能(含RSI指標確定賣點策略) 以預測股票漲跌案例入門基於SVM的機器學習 用python的matplotlib和numpy庫繪製股票K線均線和成交量的整合效果(含量化驗證交易策略程式碼) 用python的matplotlib和numpy庫繪製股票K線均線的整合效果(含從網路介面爬取資料和驗證交易策略程式碼) 本文力爭做到詳細,比如程式碼按行編號,並針對行號詳細解釋,且圖文並茂,所以如果大家感覺可以,請儘量幫忙推薦一下。本文的內容即將出書,在出版的書裡,是用股票案例和大家講述Python入門時的知識點,敬請期待。有不少網友轉載和想要轉載我的博文,本人感到十分榮幸,這也是本人不斷寫博文的動力。關於本文的版權有如下統一的說明,抱歉就不逐一回復了。
1 本文可轉載,無需告知,轉載時請用連結的方式,給出原文出處,別簡單地通過文字方式給出,同時寫明原作者是hsm_computer。
2 在轉載時,請原文轉載 ,謝絕洗稿。否則本人保留追究法律責任的權利。
&n