
機器學習--線性迴歸演算法預測房價
阿新 • • 發佈:2018-12-11
裡面非常詳細地介紹了微積分基本運演算法則、線性迴歸演算法、梯度下降演算法及改進。
a. 用線性迴歸方法擬合正弦函式
%matplotlib inline import matplotlib.pyplot as plt import numpy as np # 生成200個[-2pi,2pi]區間內的正弦函式上的點 n_dots =200 X = np.linspace(-2*np.pi,2*np.pi,n_dots) Y = np.sin(X)+0.2*np.random.rand(n_dots)-0.1 X = X.reshape(-1,1) Y = Y.reshape(-1,1) from sklearn.linear_model import LinearRegression from sklearn.preprocessing import PolynomialFeatures from sklearn.pipeline import Pipeline def polynomial_model(degree=1): # degree表示多項式的階數 polynomial_features = PolynomialFeatures(degree=degree,include_bias=False) # normalize=True將特徵歸一化至[0,1] linear_regression = LinearRegression(normalize=True) pipeline = Pipeline([("polynomial_features",polynomial_features),("linear_regression",linear_regression)]) return pipeline # 分別用2、3、5、10階多項式來擬合數據集 # 用mean_squared_error計算均方根誤差,均方根誤差越小,說明模型擬合效果越好 from sklearn.metrics import mean_squared_error degrees = [2,3,5,10] results=[] for d in degrees: model = polynomial_model(degree=d) model.fit(X,Y) train_score = model.score(X,Y) mse = mean_squared_error(Y,model.predict(X)) results.append({"model":model,"degree":d,"score":train_score,"mse":mse}) for r in results: print("degree: {}; train_score: {}; mean squared error: {};".format(r["degree"],r["score"],r["mse"]))
degree: 2; train_score: 0.150098385123013; mean squared error: 0.4252061468860883; degree: 3; train_score: 0.27885313996963546; mean squared error: 0.3607900871407268; degree: 5; train_score: 0.8966304597537259; mean squared error: 0.05171582586046318; degree: 10; train_score: 0.9931397128987751; mean squared error: 0.0034322046149616835;
可以看出,多項式階數越高,擬合評分越高,均方誤差越小,擬合效果越好。
把不同擬合結果在二維座標上畫出:
from matplotlib.figure import SubplotParams plt.figure(figsize=(6,3),dpi=200,subplotpars=SubplotParams(hspace=0.5)) for i,r in enumerate(results): fig=plt.subplot(2,2,i+1) plt.xlim(-8,8) plt.title("LinearRegression degree={}".format(r["degree"]),fontsize=6) plt.xticks(np.linspace(-8,8,9),fontsize=5) plt.yticks(fontsize=5) plt.scatter(X,Y,s=1.5,c='b',alpha=0.5) plt.plot(X,r["model"].predict(X),'r-',linewidth=1)
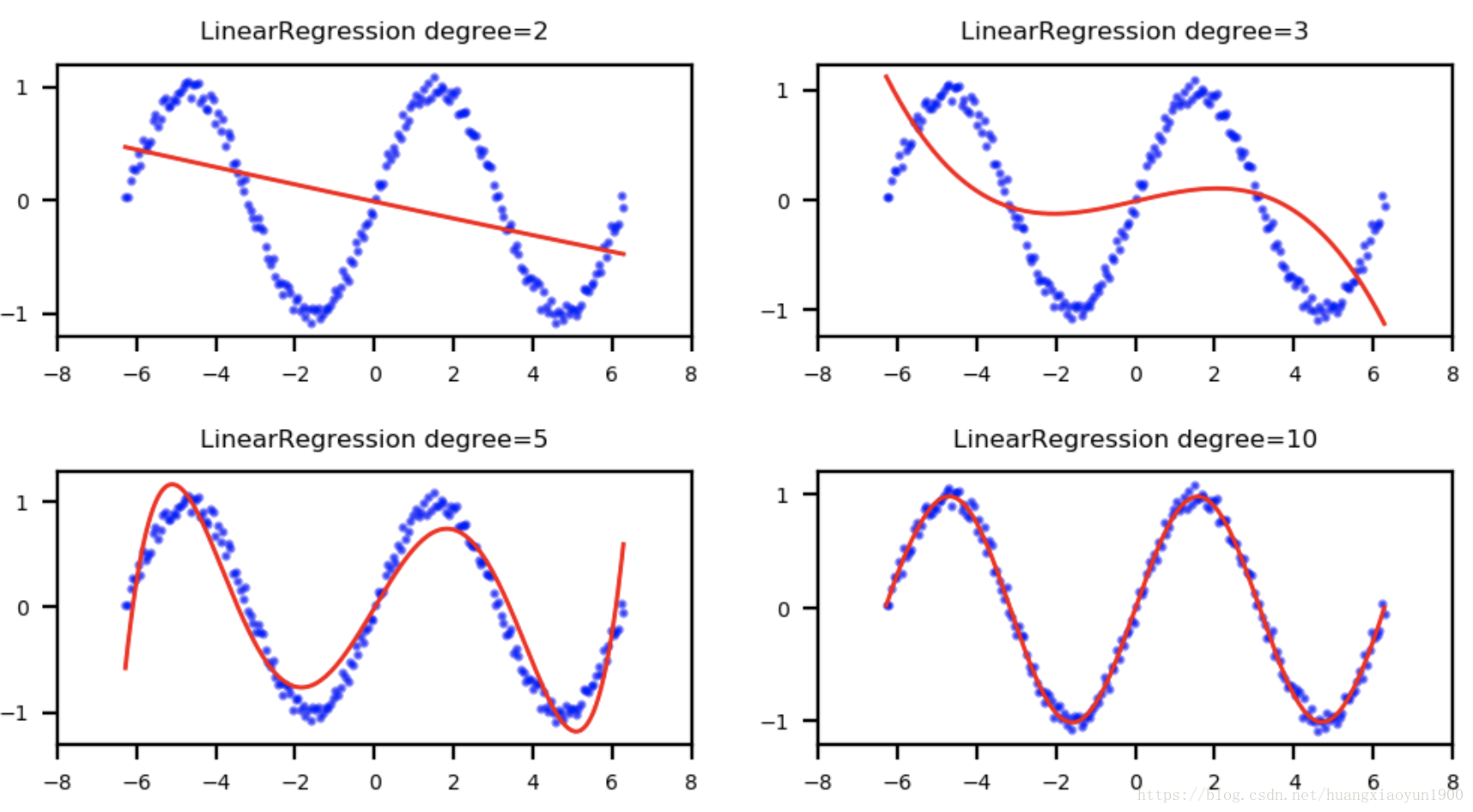
b. 預測房價
用sklearn.datasets自帶資料集預測波士頓房價:
from sklearn.datasets import load_boston
boston=load_boston()
X=boston.data
y=boston.target
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=3)
import time
from sklearn.linear_model import LinearRegression
model = LinearRegression()
# time.clock()統計某程式執行速度,兩次呼叫時間差為程式執行的CPU時間
start = time.clock()
model.fit(X_train,y_train)
train_score=model.score(X_train,y_train)
test_score=model.score(X_test,y_test)
print('elaspe: {0:.6f}; train score:{1:.6f}; test score:{2:.6f}'.format(time.clock()-start,train_score,test_score))elaspe: 0.009990; train score:0.723941; test score:0.794958
可以看出,模型擬合效果一般,需要進行模型優化。
模型優化:
首先觀察資料:
X[0]array([6.320e-03, 1.800e+01, 2.310e+00, 0.000e+00, 5.380e-01, 6.575e+00,
6.520e+01, 4.090e+00, 1.000e+00, 2.960e+02, 1.530e+01, 3.969e+02,
4.980e+00])
特徵資料的範圍相差較大,最小的級別,最大的
級別,需要對資料進行歸一化處理:
model = LinearRegression(normalize=True)但是歸一化處理只會加快演算法收斂速度,優化演算法訓練效率,並不能提升演算法準確度。
由於模型欠擬合,可以通過挖掘更多特徵或增加多項式特徵的方法優化,因此,使用多項式特徵:
二階多項式模型:
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
def polynomial_model(degree=1):
polynomial_features = PolynomialFeatures(degree=degree,include_bias=False)
linear_regression = LinearRegression(normalize=True)
pipeline=Pipeline([('polynomial_features',polynomial_features),('linear_regression',linear_regression)])
return pipeline
# 二階多項式
model = polynomial_model(degree=2)
start = time.clock()
model.fit(X_train,y_train)
train_score = model.score(X_train,y_train)
test_score = model.score(X_test,y_test)
print('elaspe:{0: .6f}; train score:{1:.6f}; test score:{2: .6f}'.format(time.clock()-start,train_score,test_score))elaspe: 0.036802; train score:0.930547; test score: 0.860465
可以看出訓練分數和測試分數都有提高,說明模型得到很好的優化。
三階多項式模型:
# 三階多項式
model = polynomial_model(degree=3)
start = time.clock()
model.fit(X_train,y_train)
train_score = model.score(X_train,y_train)
test_score = model.score(X_test,y_test)
print('elaspe:{0: .6f}; train score:{1:.6f}; test score:{2: .6f}'.format(time.clock()-start,train_score,test_score))elaspe: 0.090905; train score:1.000000; test score:-105.517016
可以看出訓練分數為100%,而測試分數為負值,說明模型過擬合。
學習曲線:
cv = ShuffleSplit(n_splits=10,test_size=0.2,random_state=0)
title="Learning curve (degree={0})"
degrees=[1,2,3]
start=time.clock()
plt.figure(figsize=(18,4),dpi=200)
for i in range(len(degrees)):
plt.subplot(1,3,i+1)
plot_learning_curve(polynomial_model(degrees[i]),title.format(degrees[i]),X,y,ylim=(0.01,1.01),cv=cv)
print('elaspe:{0:.6f}'.format(time.clock()-start))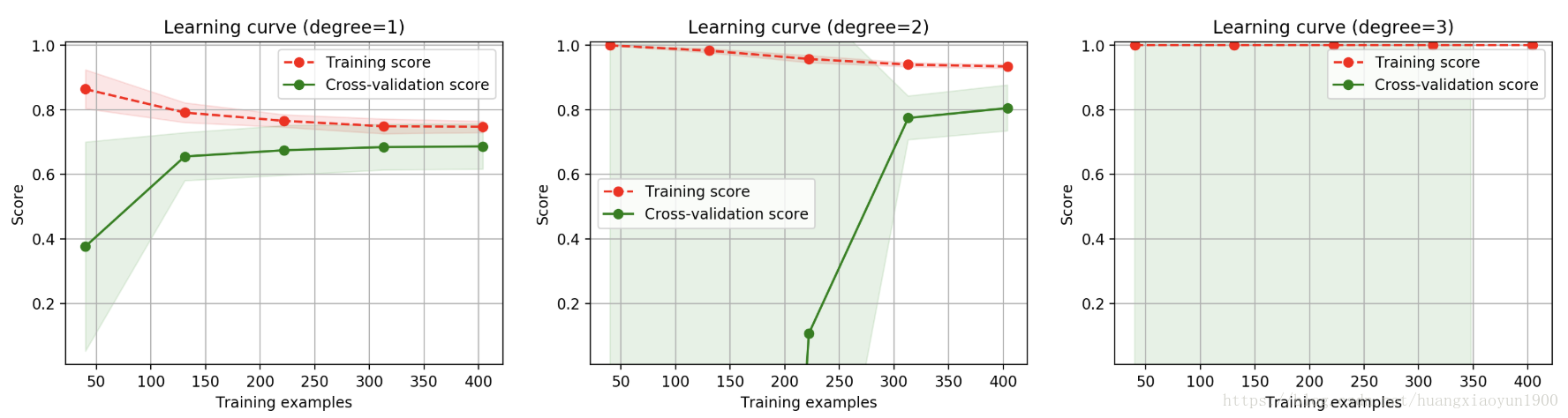
一階多項式欠擬合,因為訓練分數較低;三階多項式過擬合,因為訓練分數為1而測試分數無法看到;
二階多項式擬合效果較好,但訓練分數和測試分數間隙較大,說明訓練樣本數量不夠。
參考:
黃永昌《scikit-learn機器學習》