
聚類——密度聚類DBSCAN
Clustering 聚類
密度聚類——DBSCAN
前面我們已經介紹了兩種聚類演算法:k-means和譜聚類。今天,我們來介紹一種基於密度的聚類演算法——DBSCAN,它是最經典的密度聚類演算法,是很多演算法的基礎,擁有很多聚類演算法不具有的優勢。今天,小編就帶你理解密度聚類演算法DBSCAN的實質。
DBSCAN
基礎概念
作為最經典的密度聚類演算法,DBSCAN使用一組關於“鄰域”概念的引數來描述樣本分佈的緊密程度,將具有足夠密度的區域劃分成簇,且能在有噪聲的條件下發現任意形狀的簇。在學習具體演算法前,我們先定義幾個相關的概念:
-
鄰域:對於任意給定樣本x和距離ε,x的ε鄰域是指到x距離不超過ε的樣本的集合;
-
核心物件:若樣本x的ε鄰域內至少包含minPts個樣本,則x是一個核心物件;
-
密度直達:若樣本b在a的ε鄰域內,且a是核心物件,則稱樣本b由樣本x密度直達;
-
密度可達:對於樣本a,b,如果存在樣例p1,p2,...,pn,其中,p1=a,pn=b,且序列中每一個樣本都與它的前一個樣本密度直達,則稱樣本a與b密度可達;
-
密度相連:對於樣本a和b,若存在樣本k使得a與k密度可達,且k與b密度可達,則a與b密度相連。
光看文字是不是繞暈了?下面我們用一個圖來簡單表示上面的密度關係: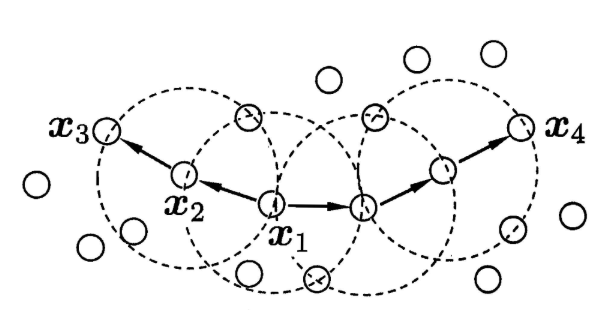
當minPts=3時,虛線圈表示ε鄰域,則從圖中我們可以觀察到:
-
x1是核心物件;
-
x2由x1密度直達;
-
x3由x1密度可達;
-
x3與x4密度相連。
為什麼要定義這些看上去差不多又容易把人繞暈的概念呢?其實ε鄰域使用(ε,minpts)這兩個關鍵的引數來描述鄰域樣本分佈的緊密程度,規定了在一定鄰域閾值內樣本的個數(這不就是密度嘛)。那有了這些概念,如何根據密度進行聚類呢?
DBSCAN聚類思想
DBSCAN聚類的原理很簡單:由密度可達關係匯出最大密度相連的樣本集合(聚類)。這樣的一個集合中有一個或多個核心物件,如果只有一個核心物件,則簇中其他非核心物件都在這個核心物件的ε鄰域內;如果是多個核心物件,那麼任意一個核心物件的ε鄰域內一定包含另一個核心物件(否則無法密度可達)。這些核心物件以及包含在它ε鄰域內的所有樣本構成一個類。
那麼,如何找到這樣一個樣本集合呢?一開始任意選擇一個沒有被標記的核心物件,找到它的所有密度可達物件,即一個簇,這些核心物件以及它們ε鄰域內的點被標記為同一個類;然後再找一個未標記過的核心物件,重複上邊的步驟,直到所有核心物件都被標記為止。
演算法的思想很簡單,但是我們必須考慮一些細節問題才能產出一個好的聚類結果:
- 首先對於一些不存在任何核心物件鄰域內的點,再DBSCAN中我們將其標記為離群點(異常);
- 第二個是距離度量,如歐式距離,在我們要確定ε鄰域內的點時,必須要計算樣本點到所有點之間的距離,對於樣本數較少的場景,還可以應付,如果資料量特別大,一般採用KD樹或者球樹來快速搜尋最近鄰,不熟悉這兩種方法的同學可以找相關文獻看看,這裡不再贅述;
- 第三個問題是如果存在樣本到兩個核心物件的距離都小於ε,但這兩個核心物件不屬於同一個類,那麼該樣本屬於哪一個類呢?一般DBSCAN採用先來後到的方法,樣本將被標記成先聚成的類。
DBSCAN演算法流程

DBSCAN演算法小結
之前我們學過了kmeans演算法,使用者需要給出聚類的個數k,然而我們往往對k的大小無法確定。DBSCAN演算法最大的優勢就是無需給定聚類個數k,且能夠發現任意形狀的聚類,且在聚類過程中能自動識別出離群點。那麼,我們在什麼時候使用DBSCAN演算法來聚類呢?一般來說,如果資料集比較稠密且形狀非凸,用密度聚類的方法效果要好一些。
DBSCAN演算法優點:
-
不需要事先指定聚類個數,且可以發現任意形狀的聚類;
-
對異常點不敏感,在聚類過程中能自動識別出異常點;
-
聚類結果不依賴於節點的遍歷順序;
DBSCAN缺點:
-
對於密度不均勻,聚類間分佈差異大的資料集,聚類質量變差;
-
樣本集較大時,演算法收斂時間較長;
-
調參較複雜,要同時考慮兩個引數;
小結:
基於密度的聚類演算法是廣為使用的演算法,特別是對於任意形狀聚類以及存在異常點的場景。上面我們也提到了DBSCAN演算法的缺點,但是其實很多研究者已經在DBSCAN的基礎上做出了改進,實現了多密度的聚類,針對海量資料的場景,提出了micro-cluster的結構來表徵距離近的一小部分點,減少儲存壓力和計算壓力...還有很多先進的密度聚類演算法及其應用,相信看完這篇文章再去讀相關的論文會比較輕鬆。

掃碼關注
獲取有趣的演算法知識


&n