
常見排序演算法總結分析之選擇排序與歸併排序-C#實現
阿新 • • 發佈:2020-04-01
本篇文章對選擇排序中的簡單選擇排序與堆排序,以及常用的歸併排序做一個總結分析。
[常見排序演算法總結分析之交換排序與插入排序-C#實現](https://www.cnblogs.com/iwiniwin/p/12589405.html)是排序演算法總結系列的首篇文章,包含了一些概念的介紹以及交換排序(冒泡與快速排序)和插入排序(直接插入與希爾排序)的總結,感興趣的同學可以先去看一下。
# 選擇排序
選擇排序主要包括兩種排序演算法,分別是簡單選擇排序和堆排序
## 簡單選擇排序
### 基本思想
每一趟在待排序列中選出最小(或最大)的元素,依次放在已排好序的元素序列後面(或前面),直至全部的元素排完為止。
簡單選擇排序也被稱為直接選擇排序。首先在待排序列中選出最小的元素,將它與第一個位置上的元素交換。然後選出次小的元素,將它與第二個位置上的元素交換。以此類推,直至所有元素排成遞增序列為止。
選擇排序是對整體的選擇。只有在確定了最小數(或最大數)的前提下才進行交換, 大大減少了交換的次數。
### 複雜度與穩定性與優缺點
* 空間複雜度:O(1)
* 時間複雜度:O(n2)
* 最好情況:O(n2),此時不發生交換,但仍需進行比較
* 最壞情況:O(n2)
* 穩定性:不穩定,因為在將最小或最大元素替換到前面時,可能將排在前面的相等元素交換到後面去
* 優點:交換資料的次數已知(n - 1)次
* 缺點:不穩定,比較的次數多
### 演算法實現
```c#
public void SimpleSelectionSort(int[] array){
for(int i = 0; i < array.Length - 1; i ++){
int index = i;
for(int j = index + 1; j < array.Length; j ++){
if(array[j] < array[index]){
index = j;
}
}
if(index != i)
Swap(array, i, index);
}
}
public void Swap(int[] array, int i, int j){
int temp = array[i];
array[i] = array[j];
array[j] = temp;
}
```
**【演算法解讀】**
初始時無序區為整個待排序列。演算法內層迴圈遍歷整個無序區的所有元素,找到其中最小的元素,用`index`記錄其下標位置。然後將找到的最小元素與無序區的首元素進行交換,這樣就完成了一趟選擇排序,此時序列的首元素處於有序區中,剩下的元素處於無序區中。重複上面的操作,繼續查詢無序區中的最小元素,並將找到的最小元素和無序區首元素進行交換。直至完成所有排序。
**【舉個栗子】**
對於待排序列3,1,4,2
首先將序列首元素3的索引0儲存在`index`中,從元素1開始與`index`位置上的元素(此時是3)進行比較,1<3,則`index`儲存元素1的索引。繼續將`index`位置上的元素(此時是1)與元素4比較,4>1,繼續與2比較,1<2,不需要改變。沒有需要再比較的元素了,此時將`index`記錄的索引位置上的元素3和無序區首元素進行交換。則完成一趟選擇排序.,序列為1,3,4,2。有序區為1,無序區為3,4,2。繼續下一趟排序,將找到的無序區最小元素,和無序區首元素進行交換。這一趟選擇排序結束後,序列為1,2,4,3。有序區為1,2,無序區為4,3。重複上述操作直到完成排序。
## 堆排序
堆排序是藉助堆來實現的選擇排序。
什麼是堆呢?堆是滿足下列性質的數列{ R1, R2, R3, R4, ..., Rn }:
Ri<=R2i且Ri<=R2i + 1或者是Ri>=R2i且Ri>=R2i + 1,前者稱為小頂堆,後者稱為大頂堆。
例如小頂堆:{10,34,24,85,47,33,53},位置i(i從1開始)上的元素小於2i位置上的元素,且小於2i+1位置上的元素。繪製成堆的形狀,如下圖所示,可以發現每個堆的堆頂元素(每個二叉樹的根節點)均小於其左子節點(2i)與右子節點(2i + 1)元素。
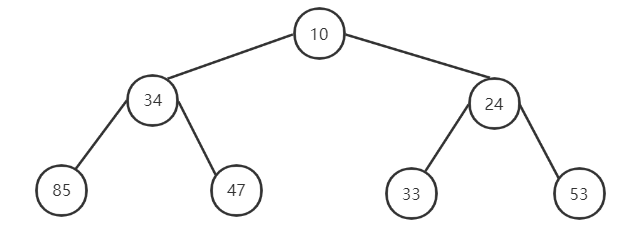
對於小頂堆而言,整個堆的堆頂元素便是整個序列的最小值,大頂堆同理。
### 基本思想
對待排序列的所有元素,首先將它們排成滿足大頂堆或小頂堆的定義的序列,常稱為建堆。建堆完成後堆頂元素便是最大或最小元素。然後將堆頂元素移出(比如移動到序列尾部),再對剩餘的元素進行再建堆,常稱為重新調整成堆,即可通過堆頂元素得到次大(次小)元素,如此反覆進行,直到完成排序為止。
實現堆排序有兩個關鍵步驟,建堆和調整堆
如何建堆:首先將待排序列畫成一顆完全二叉樹,然後再把得到的完全二叉樹轉換成堆。
從最後一個有孩子節點的節點(這樣可以構成一顆有孩子的樹,根節點才能夠向下滲透)開始(對於陣列而言就是下標為`n / 2 - 1`的節點)),依次將所有以該節點為根的二叉樹調整成堆,即先調整子樹,再調整父樹,當這個過程持續到整顆二叉樹樹的根節點時,待排序列就被調整成了堆,即建堆完成。
如何調整堆:假設被調整的節點為A,它的左孩子為B,右孩子為C。那麼當A開始進行堆調整時,根據上面建堆的方式,以B和以C為根的二叉樹都已經為堆。如果節點A的值大於B和C的值(以大頂堆為例),那麼以A為根的二叉樹已經是堆。如果A節點的值小於B節點或C節點的值,那麼節點A與值最大的那個孩子節點變換位置。此時需要繼續將A與和它交換的那個孩子的兩個孩子節點進行比較,以此類推,直到節點A向下滲透到適當的位置為止。
如果要從小到大排序,則使用大頂堆,如果要從大到小排序,則使用小頂堆。原因是堆頂元素需要交換到序列尾部
### 複雜度與穩定性與優缺點
* 空間複雜度:O(1)
* 時間複雜度:O(nlog2