
【圖機器學習】cs224w Lecture 8 & 9 - 圖神經網路 及 深度生成模型
阿新 • • 發佈:2020-05-16
[toc]
轉自本人:[https://blog.csdn.net/New2World/article/details/106160122](https://blog.csdn.net/New2World/article/details/106160122)
## Graph Neural Network
這一課主要講了如何用深度學習的方法來做 embedding,也就是最近很火的 Graph Neural Network 圖神經網路。之所以想到要用 GNN 是因為之前提到的 embedding encoder 其實是一種 shallow encoder,即類似與所有節點的 embedding 是一個矩陣,每個節點對應一列。在使用的時候就是一個簡單的 look up 的過程,而這樣做的缺陷在於
1. 沒有共享引數,總引數量為 $O(|V|)$
2. 不能泛化到沒見過的節點上
3. 只考慮了網路結構資訊而沒有綜合節點特徵
### Graph Convolutional Network
現在比較成熟的卷積神經網路其實可以看作一種特殊的圖網路,因為圖片類似於 $4$-regular 的圖,而圖片中的畫素就像一個個節點。圖片上的卷積操作其實就是位於卷積核中心的畫素(節點)從相鄰畫素(節點)獲取資訊的過程。
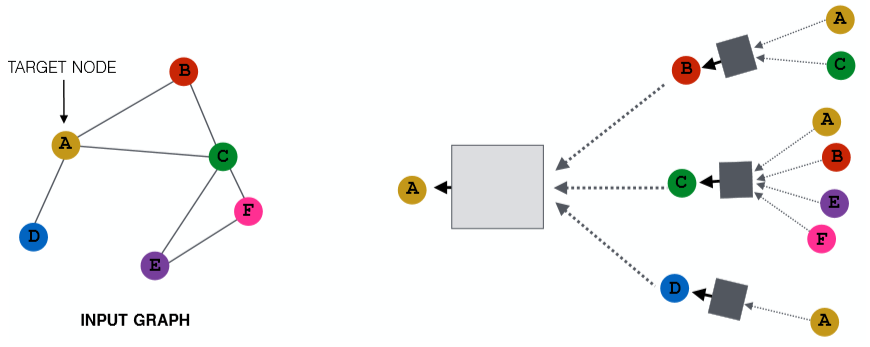
那麼把卷積神經網路的思想遷移過來,對於每個圖中的節點,我們聚合它周圍的節點資訊就能實現類似卷積的操作。如上圖,對於節點 A 我們將它的鄰接點聚合起來。而對於 A 的鄰接點也採取同樣的操作,那麼我們就能得到一棵樹。可以將這棵樹看作節點 A 獨一無二的一張計算圖,從中我們可以得到包含了 local network neighborhoods 資訊的 embedding。這裡這個聚合的範圍,可以看作 A 捕獲了多大區域內的 local 資訊,或者說我們延伸了多少個 hops。從 Lecture 2 中的隨機圖可知,路徑平均長度為 $6$,因此這裡我們只需要延伸 $5$ hops 就夠了。當然針對不同的圖,可以延伸更廣。用更數學的方式來描述的話就是
$$\begin{aligned}
h_v^{(k)}&=\sigma(W^{(k)}\sum_{u\in N(v)}\frac{h_u^{(k-1)}}{|N(v)|}+B^{(k)}h_v^{(k-1)}) \\
H^{(l+1)}&=\sigma(H^{(l)}W_0^{(l)}+\tilde{A}H^{(l)}W_1^{(l)})
\end{aligned}$$
其中 $\tilde{A}=D^{-\frac12}AD^{-\frac12}$;$W, B$ 就是我們需要訓練的引數,可以將其理解為 neighbor 資訊和 self 資訊的一個 trade-off。在有了這個模型的情況下我們可以採用 supervised 以及 unsupervised。
**unsupervised**
不管是有監督還是無監督都需要損失函式,那這個損失函式從哪兒來?因為我們得到的是 embedding,因此可以使用一下幾種方法
- random walks
- graph factorization
- node proximity in the graph
**supervised**
對於監督學習我們首先得提供訓練資料,這個資料可以是整張圖,也可以是一張很大的圖的一部分匯出子圖。在訓練資料上訓練好模型後,就可以將這個模型應用到其他具有相似分佈的圖或者整張圖的其他部分上去了。
### GraphSAGE
現在還有一個遺留問題,即上面那張圖中的方框代表什麼?這其實是我們聚合鄰接點資訊的函式,這個函式可以是 sum,mean,pooling 等。也就是說我們可以將從鄰接點得到的資訊進行累加,平均,池化甚至可以在這裡再巢狀一個神經網路,比如 LSTM。這一切都取決於你的應用以及效果。
GraphSAGE 其實就是一種圖卷積網路,只不過它相比於 GCN 泛化了聚合操作。GraphSAGE 直接將鄰接點資訊和節點的自身資訊進行拼接,並對節點的 embedding 加上了 l2-norm
$$h_v^{(k)}=\sigma([A^{(k)}\cdot AGG(\{h_u^{(k-1)},\forall u\in N(v)\}), B^{(k)}h_v^{(k-1)}])$$
> 這裡加入 LSTM 會違背 permutation invariant 的性質,但如果我們在給訓練集的時候對每個節點的鄰接點進行多次 shuffle,那麼就沒問題。
貼一張 slide,上面列舉了很多 GNN 相關的應用。

## Graph Attention Network
上面的 GCN 和 GraphSAGE 雖然在 AGG 函式上絞盡腦汁,但最終還是給所有鄰接點相同的權重。如果現在我們希望能學習鄰接點上不同的側重,即給不同鄰接點不同的權重,那麼就需要用到 GAT。
現在定義 $\alpha_{vu}$,其中 $u\in N(v)$ 代表了節點 $v$ 到其鄰接點的權重。同時定義 attention coefficients $e_{vu}=a(W^{(k)}h_u^{(k-1)},W^{(k)}h_v^{(k-1)})$ 代表了 $v$ 的鄰接點 $u$ 對 $v$ 的重要性。那麼 $e_{vu}$ 和 $\alpha_{vu}$ 的關係就是
$$\alpha_{vu}=\frac{\exp(e_{vu})}{\sum_{k\in N(v)}\exp(e_{vk})}$$
那麼將這個 $\alpha_{vu}$ 加入 GNN 就會得到 $h_v^{(k)}=\sigma(\sum_{u\in N(v)}\alpha_{vu}W^{(k)}h_v^{(k-1)})$。這樣就完成了 GNN 中的 attention 機制。和一般的 attention 一樣,這裡也可以用 multi-head attention。
## Tips
- data preprocessing is important
- renormalization
- variance-scaled
- network whitening
- optimizer: adam
- activation: ReLU
- include bias in every layer
- GCN layer of size $64$ or $128$ is already plenty
- overfit on training set
## Deep Generative Models for Graphs
上面講了如何將圖中的節點進行編碼,那與之對應的就是解碼了。這裡的解碼抽象地理解就是生成一張圖。之前也有講過類似 E-R、Small-World、Kronecker 圖以及圖的零模型等,但這些生成圖的方法都很簡單不具有普適性。我們想要一種給定一類圖就能生成類似的圖的模型。
要提出一個生成圖的模型,首先需要明確幾個困難點
1. 如果用鄰接矩陣表示,那對於一個有 $n$ 個節點的圖,需要 $n^2$ 的引數
2. 由於節點編號的原因,同樣的圖可能有 $n!$ 種表示
3. 節點間的邊可能會產生很複雜的依賴關係,例如生成一個環需要數所有節點的個數
那麼將圖的生成模型用更數學的方式表達就是在給定一些從分佈 $p_{data}(G)$ 中取樣得到的圖,我們需要讓模型學習一個 $p_{model}(G)$,使得這個分佈接近給定的分佈。然後我們就可以從模型學習到的分佈得到新的圖。
如何使 $p_{model}(x;\theta)$ 接近 $p_{data}(x)$ 呢?很簡單,極大似然
$$\theta^*=\argmax_{\theta}E_{x\sim p_{data}}\log p_{model}(x|\theta)$$
有了模型後我們怎麼通過它得到新的圖呢?
1. 從一個簡單的噪聲分佈取樣 $z_i\sim N(0,1)$
2. 通過一個函式將噪聲種子轉換為圖 $x_i=f(z_i;\theta)$
而這裡的 $f(\cdot)$ 可以是神經網路。
### GraphRNN: a Auto-Regressive Models
Auto-regressive 模型的特點是基於過去的行為預測未來的行為。這也就是接下來要講的 GraphRNN 的工作原理。不過在此之前先回憶一下鏈式法則
$$p_{model}(x;\theta)=\prod\limits_{t=1}^np_{model}(x_t|x_1,...,x_{t-1};\theta)$$
在這兒的話 $x_t$ 指我們採取的第t個操作 (加節點,加邊)
對於節點順序的問題,我們先假設它是固定的,後面會說到怎麼編排順序。那麼在給定順序後,生成圖的序列定義為 $S^{\pi}=(S_1^{\pi},S_2^{\pi},S_3^{\pi},...)$。而每一項又是一個子序列,表示新加入的節點生成與之前節點連線的邊的序列。即這裡有兩種序列 node-level 和 edge-level。這兩個 level 之間相互依賴互相更新
- Node-level: 生成節點狀態,並作為 edge-level 的初始狀態
- Edge-level: 為新加入的節點生成邊,並用生成的結果更新 node-level 的狀態

但是如圖中這樣,將 edge-level 生成的結果直接輸入下一個 cell 的話會使這個過程是 deterministic 的。因此為了引入隨機性,將 edge-level 的輸出變成概率,然後再輸入下一個 cell 時進行 sampling。
訓練時只需要用 ground truth 替換概率並用 binary cross entropy 計算損失來更新引數。
> EOS (end of sequence) 在這裡可以當做一個單獨的狀態,然後讓模型在訓練的時候學習它。在推理的時候讓 node-level RNN 在 EOS 處停止;問題就是 edge-level 時是固定長度還是 EOS 停止?如果是 EOS 停止,那如果長度不夠/超過了怎麼辦?
### Tractability
那麼現在回到節點順序的問題上。如果節點順序沒有排好就可能會出現後生成的節點與最初生成的節點有連線,即過於複雜的依賴。隨著圖的規模增加,這樣可能會造成梯度消失或資訊丟失。因此我們用最簡單也最直觀地方法解決排序問題:BFS。因為 BFS 的 breadth 的性質,它能很好的將圖“分層”。
- 減少可能的排列組合
- 減少生成邊時“回顧”長度
![BFS ordering](https://img2020.cnblogs.com/blog/1996991/202005/1996991-20200516154716615-19487420