
【小白學AI】八種應對樣本不均衡的策略
阿新 • • 發佈:2020-08-03
**文章來自:微信公眾號【機器學習煉丹術】**
[TOC]
## 1 什麼是非均衡
分類(classification)問題是資料探勘領域中非常重要的一類問題,目前有琳琅滿目的方法來完成分類。然而在真實的應用環境中,**分類器(classifier)扮演的角色通常是識別資料中的“少數派”**,比如:
* 銀行識別信用卡異常交易記錄
* 垃圾郵件識別
* 檢測流水線識別殘次品
* 病情監測與識別等等
在這樣的應用環境下,作為少數派的群組在資料總體中往往佔了極少的比例:絕大多數的信用卡交易都是正常交易,八成以上的郵件都是正常郵件,大多數的流水線產品是合格產品,在進行檢查的人群中特定疾病的發病率通常非常低。
如果這樣的話,假設99%的正樣本+1%的負樣本構成了資料集,那麼假設模型的預測結果全是正,這樣的完全沒有分辨能力的模型也可以得到99%的準確率。這個按照樣本個數計算準確率的評價指標叫做——**Accuracy.**
因此我們為了避免這種情況,最常用的評價指標就是F-score,Precision&Recal,Kappa係數。
**【F-Score和Kappa係數已經在歷史文章中講解過啦】**
## 2 8種解決辦法
解決辦法主要有下面10種不同的方法。
- 重取樣resampling
- 上取樣:簡單上取樣,SMOT,ADASYN
- 下采樣:簡單下采樣,聚類Cluter,Tomek links
- 調整損失函式
- 異常值檢測框架
- 二分類變成多分類
- EasyEnsemble
### 2.1 重取樣(四種方法)
重取樣的目的就是讓少的樣本變多,或者是讓多的樣本變少。下圖很形象的展示出這個過程:
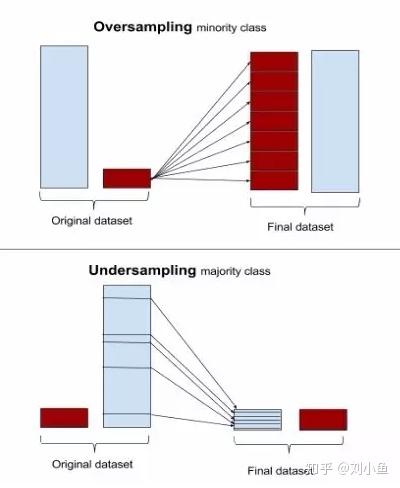
****
**【簡單上取樣】**
就是**有放回的隨機抽取少數量的樣本**,飯後不斷複製抽取的隨機樣本,直到少數量的樣本與多數量的樣本處於同一數量級。但是這樣容易造成過擬合問題。
**為什麼會造成過擬合呢?** 最極端的例子就是把一個樣本複製100次,這樣就有了一個100樣本的資料庫。模型訓練出來很可能得到100%的正確率,但是這模型真的學到東西了嗎?
****
**【SMOTE】**
- SMOT:Synthetic Minority Over-sampling Technique.(翻譯成中文,合成最少個體上取樣技術?)
核心思想是**依據現有的少數類樣本人為製造一些新的少數類樣本** SMOTE在先用K近鄰演算法找到K個近鄰,利用這個K個近鄰的各項指標,乘上一個0~1之間的隨機數就可以組成一個新的少數類樣本。容易發現的是,就是**SMOTE永遠不會生成離群樣本**
****
**【ADASYN】**
- ADASYN:Adaptive Synthetic Sampling Approach(自適應合成樣本方法)
ADASYN其實是SMOTE的一種衍生技術,相比SMOT在每一個少數類樣本的周圍**隨機**的建立樣本,ADASYN給每一個少數類的樣本分配了權重,在**學習難度較高的少數類樣本週圍建立更多的樣本**。在**K近鄰分類器分類錯誤的那些樣本**周圍生成更多的樣本,也就是給他們更大的權重,而並不是隨機0~1的權重。
這樣的話,就好像,一個負樣本週圍有正樣本,經過這樣的處理後,這個負樣本週圍會產生一些相近的負樣本。**這樣的弊端也是顯而易見的,就是對離群點異常敏感。**
****
**【簡單下采樣】**
這個很簡單,就是隨機刪除一些多數的樣本。弊端自然是,**樣本數量的減少,刪除了資料的資訊**
****
**【聚類】**
這個是一個非常有意思的方法。我們先選取樣本之間**相似度的評估函式**,比方說就用歐氏距離(可能需要對樣本的資料做歸一化來保證不同特徵的同一量綱)。
方法1:假設有10個負樣本和100個正樣本,對100個正樣本做kmeans聚類,總共聚10個類出來,然後每一個類中心作為一個正樣本。
方法2:使用K近鄰,然後用K個樣本的中心來代替原來K個樣本。一直這樣做,直到正樣本的數量等於負樣本的數量。
****
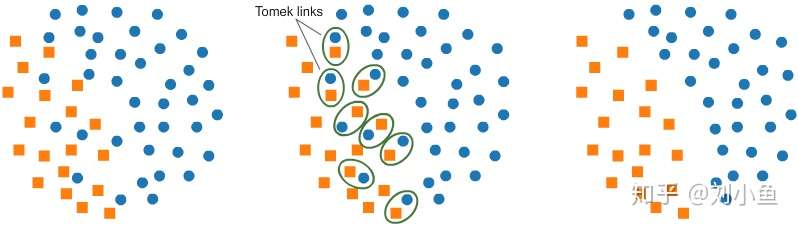
**【Tomek links】**
- 這個不知道咋翻譯
Tomek links是指相反類樣本的配對,這樣的配對距離非常近,也就是說這樣的配對中兩個樣本的各項指標都非常接近,但是屬於不同的類。如圖所示,這一方法能夠找到這樣的配對,並刪除配對中的多數類樣本。經過這樣的處理,兩類樣本之間的分界線變得更加清晰,使少數類的存在更加明顯。
下圖是操作的過程。
### 2.2 調整損失函式
調整損失函式的目的本身是為了使模型對少數量樣本更加敏感。訓練任何一個機器學習模型的最終目標是損失函式(loss function)的最小化,如果能夠在損失函式中加大錯判少數類樣本的損失,那麼模型自然而然能夠更好地識別出少數類樣本。
比較著名的損失函式就是目標檢測任務中的focal loss。不過在處理其他任務的時候,也可以人為的增加少數樣本錯判的損失。
### 2.3 異常值檢測框架
* 將分類問題轉換成為一個異常值監測框架
這個異常值檢測框架又是一個非常大的體系,有很多不同的模型,比方說:異常森立等。之後會專門講講這個體系的模型的。
**(小夥伴關注下公眾號唄,不迷路呀)**
### 2.4 二分類變成多分類
對於不均衡程度較低的資料,可以將多數量樣本進一步分為多個組,雖然二分類問題被轉化成了一個多分類問題,但是資料的不平衡問題被解決,接下來就可以使用多分類中的一對多(OVA)或一對一(OVO)的分類方式進行分類。
就是把多數類的樣本通過聚類等方法,劃分成不同的類別。這樣2分類任務就變成了多分類任務。
### 2.5 EasyEnsemble
另外一種欠取樣的改進方法是 EasyEnsemble ,它將多數樣本劃分成若 N個集合,然後將劃分過後的集合與少數樣本組合,這樣就形成了N個訓練集合,而且每個訓練都正負樣本均衡,並且從全域性來看卻沒有資訊