
Pytorch_第十篇_卷積神經網路(CNN)概述
阿新 • • 發佈:2020-08-15
# 卷積神經網路(CNN)概述(包含例子)
---
## Introduce
**卷積神經網路**(convolutional neural networks),簡稱**CNN**。卷積神經網路相比於人工神經網路而言更適合於影象識別、語音識別等任務。==本文主要涉及卷積神經網路的概念介紹,首先介紹卷積神經網路相比於人工神經網路的優勢,其次介紹卷積神經網路的基本結構,最後我們分別介紹神經網路的各個部件從而完整的瞭解CNN。==
==**以下均為初學者筆記,若有錯誤請不吝指出。**==
---
## Advantages of Convolutional Neural Networks
就拿影象舉例來說,一張影象的大小為寬X高X通道數(一般是三色通道)。假設有一組影象的大小為n,那麼如果我們用傳統的神經網路來處理這張影象的畫,輸入層需要n個神經元,並且若採用全連線結構的話則會有很多很多的權重引數,這對於網路的訓練來說是非常難且耗時的。並且如果影象非常複雜,我們不可能通過不斷增加隱層的數量來捕獲更加高階的影象特徵,因為隱層數過多的神經網路在梯度反向傳播的時候可能會出問題,比如之前講過的梯度爆炸和梯度消失問題。**因此傳統神經網路比較不適合處理影象任務**。**反觀卷積神經網路,其採用了局部連線、權重共享(即卷積核只與一個視窗進行連線,並且該卷積核可由多個視窗共享)以及池化的設計思路,三個策略的疊加使用大大減少了網路中非常多非常多的不必要的權值引數,使得網路訓練變得容易**。==本文餘下篇幅將更加全面的介紹CNN,以幫助讀者更加通俗地理解CNN相比傳統神經網路所具有的優勢。==
---
## Basic Structure of Convolution Neural Network
**卷積神經網路包含卷積層(Convolution)、非線性啟用層(常用ReLU層)、池化層(pooling)、全連線層(Full-Connected)和Softmax層。卷積神經網路的基本結構如下圖所示。**

==**文章餘下內容將結合具體例子並且按照上述各個部分具體展開介紹。**。==
**舉個梨子:** 假設我們要識別下述圖片(**菱形**)是菱形呀還是三角形呀,還是正方形長方形呀等等。人眼一看肯定想都不用想就知道是菱形了。那麼,計算機要怎麼才能知道這個圖片是個菱形呢?**其實,計算機識別的具體思路是這樣子的:** 菱形都有什麼特徵呀,這種圖片上有沒有滿足菱形的幾個特徵呀?帶著這幾個問題呀,計算機首先需要學習菱形具有的幾個特徵(**對應CNN的訓練過程**),其次計算機需要去圖上看是不是能找到菱形的特徵,如果都滿足了,那麼就判定這是個菱形(**對應CNN的預測過程**)。**以下從該例子逐步介紹CNN模型各個部件所做的事情**。

---
## 卷積層(Convolution)
卷積層是在做什麼呢?**卷積層就是利用攜帶某特徵的卷積核在圖上逐步匹配看看是否具有該卷積核攜帶的特徵。** 看了上面對於卷積層的描述(**個人理解**),我們腦子裡肯定還會有兩個疑問。**第一**,卷積核又是啥東西,怎麼攜帶圖片的特徵的?**第二**,卷積核在圖上逐步匹配(就是卷積運算)尋找是否具有該特徵,又是怎麼匹配的?**首先,我們來看第一個問題,卷積核是什麼呢?** 其實,卷積核就是一個權值矩陣,每個元素為對應的畫素值,卷積核可以表示圖片中的邊緣特徵,如正負斜線,豎直線和橫直線等等(**這些斜線、直線或者曲線等等就是圖片最基本的區域性特徵,更高階的全域性特徵(如正方形,長方形等等)捕獲可以通過多層卷積實現**)。以下分別展示正斜線、負斜線、豎直線以及橫直線的3X3卷積核,以幫助我們更近一步理解卷積核的概念。

**對於第二個問題,怎麼判斷圖上是否存在如卷積核所描述的特徵呢?即怎麼判斷圖上有正斜線、負斜線呢?** 其實這是通過在圖上移動視窗(**視窗大小=卷積核大小**),並且每次都將視窗與卷積核進行卷積運算實現的(**其實就是兩個矩陣對應位置相乘求和再取平均!!!**)。這樣解釋可能有點抽象,我們結合具體例子來看。假設我們要在上述菱形圖中尋找正斜線(如上圖中3X3的卷積核),那要怎麼找呢?首先用3X3的視窗遍歷整個圖,每次都將對應卷積核與視窗進行卷積運算並將所得值依次按序填入新矩陣中,**這個新的矩陣我們稱之為特徵圖(feature map)**。**特徵圖用來判斷原始圖中對應位置與卷積核的匹配程度,越大則表明原始圖中的這個位置越可能具有該卷積核所攜帶的特徵。** 現在我們通過代表正斜線特徵的卷積核與原始圖片中第一個視窗進行卷積運算來說明卷積運算的過程,**一個簡單的卷積示例如下**:
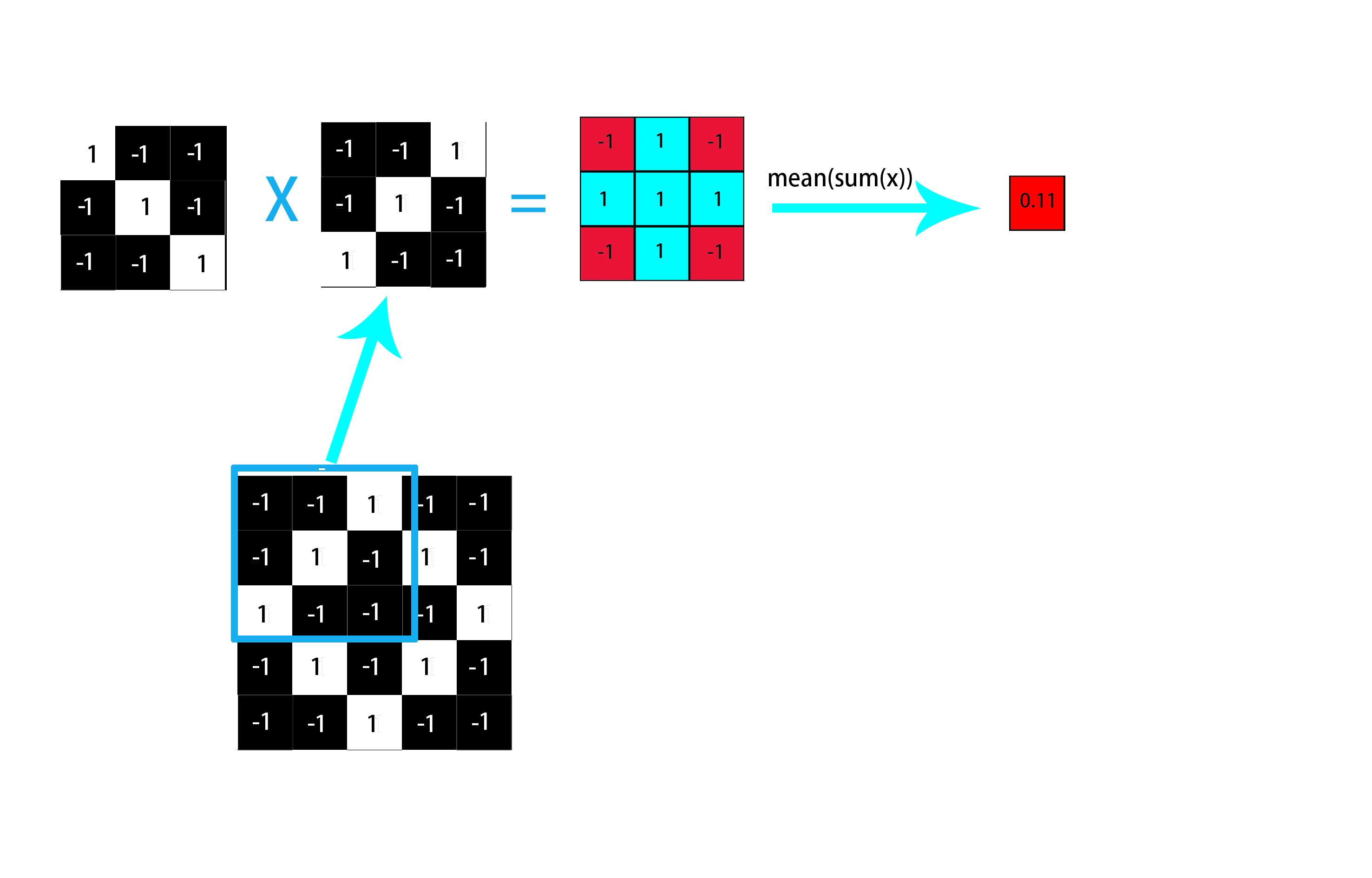
如上圖所示我們選取原始圖片中的第一個視窗與正斜線卷積核進行卷積運算,首先兩個矩陣對應位置相乘得到一個新的矩陣(**其實我們可以發現,如果對應位置的兩個畫素越相近,那麼對應相乘起來的值也就越大**),再對新的矩陣求和取平均之後可以得到一個代表匹配程度的數值(**同理,如果整個視窗與卷積核相似的畫素越多,則得到的該數值也就越大**),這個數值稍後將填入特徵圖的第一行第一列元素,代表原始圖中第一個視窗與卷積核的匹配程度為0.11。
理解了卷積運算之後,我們從左到右,從上到下移動視窗分別與選定卷積核做卷積運算(**這邊請注意,視窗的移動步長是可以設定的,這邊預設步長為1**),最後可以得到關於該卷積核的特徵圖(**特徵圖中的元素描述圖片對應視窗與該卷積核的匹配程度**)。**最終得到的特徵圖(feature map)如下(可以理解成是一個特徵提取過程圖片壓縮過程,作為後續卷積層的輸入):**
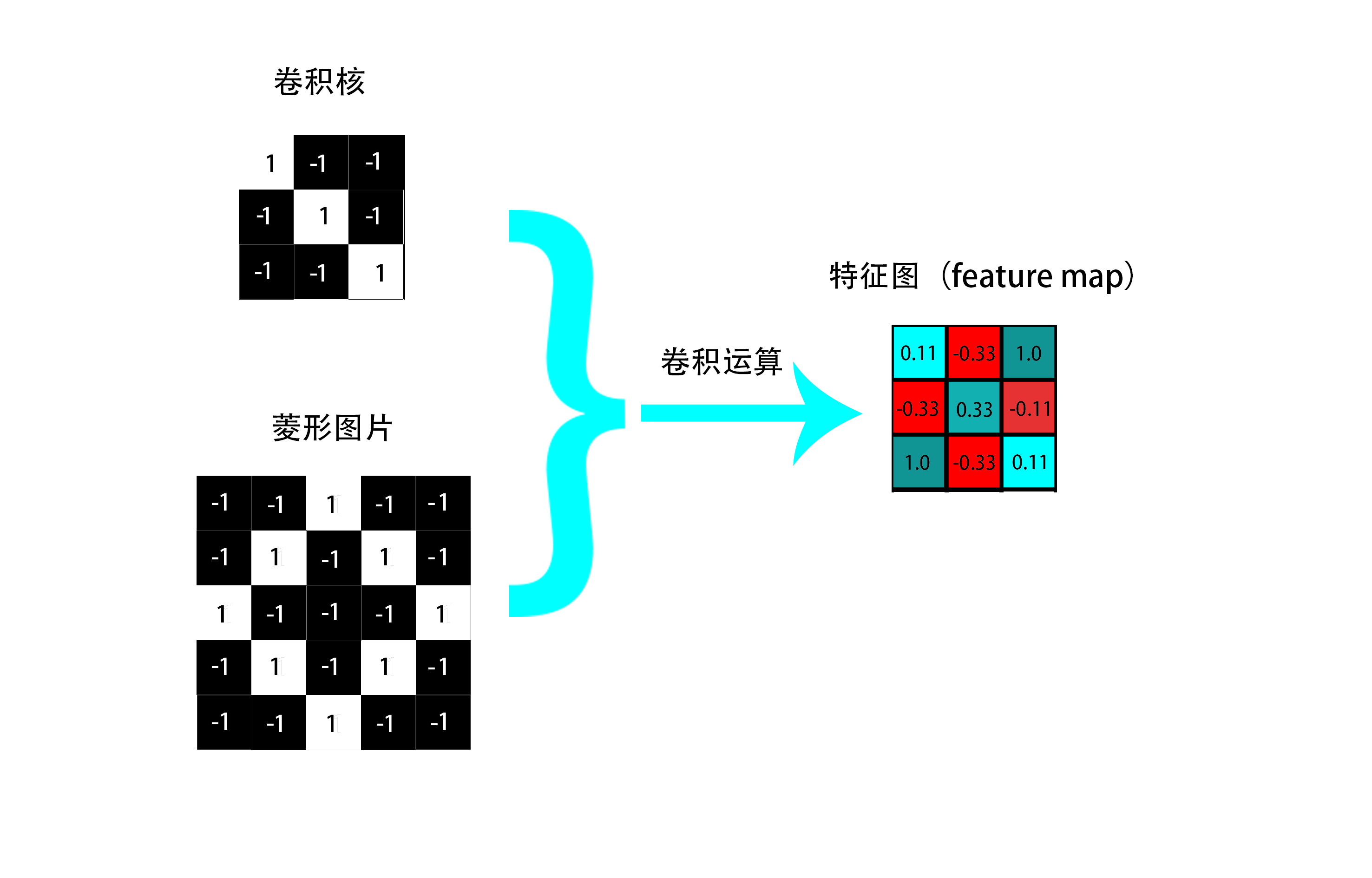
**值得說明的一點是**:feature map上的每個元素代表卷積核與原始圖種對應位置特徵的匹配程度,值越大原始圖中對應位置與卷積核攜帶的特徵越相似。並且,
每一個卷積核與原始圖片進行卷積運算都能得到一個對應的特徵圖(feature map),卷積核有多少個,經過卷積層運算之後得到的特徵圖就有多少個。
---
## 非線性啟用層(ReLU)
**與傳統神經網路一樣,卷積神經網路也需要使用啟用函式來融入非線性特徵(我覺得卷積運算應該是線性的,而且純做線性變換的也沒什麼意思)**。而卷積神經網路中現在比較常用的是ReLU啟用函式(**其實ReLU函式就是>=0的值不變,小於0的值變為0**),**ReLU啟用函式**的介紹可以參考我上一篇部落格[Pytorch_第九篇_神經網路中常用的啟用函式](https://www.cnblogs.com/wangqinze/p/13446081.html)。那捲積神經網路中的非線性啟用層是怎麼作用的呢?我們還是通過上述例子來進行說明:
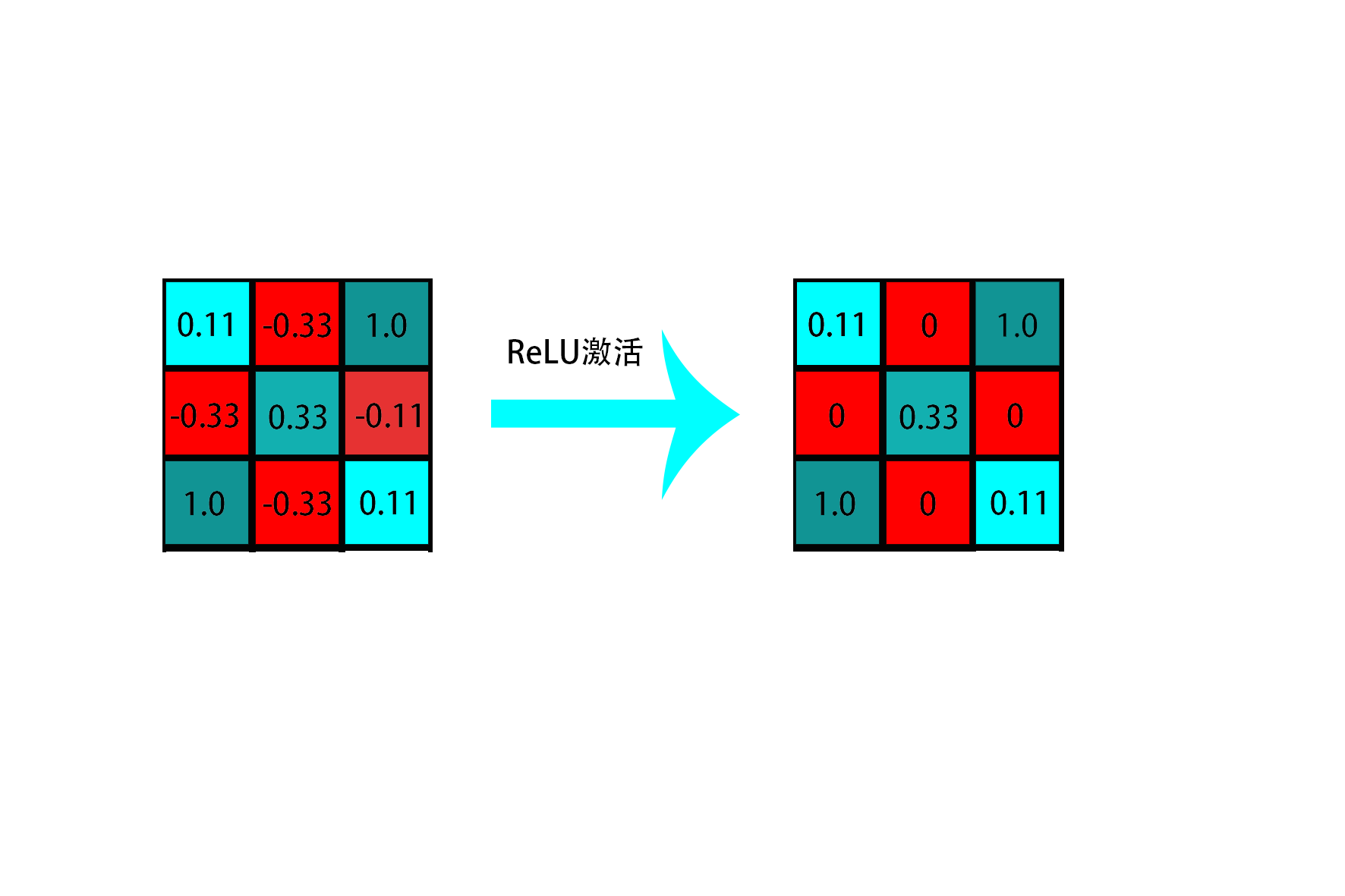
**如上圖所示**,對特徵圖中每個元素進行ReLU啟用,可以得到右圖中特徵圖。我們可以發現多了很多0(**需要注意的是,ReLU啟用之後的資料量比原始圖少了很多很多,後面可以通過池化層進一步削減資料量,畢竟深度學習圖片領域的訓練資料都是又大又多的,因此時間效率還是比較重要的**),即我們通過ReLU啟用將負相關的資料捨棄了,使得矩陣變成了一個更加稀疏的矩陣,**操作起來也更加方便**。(**並且若是在大規模網路中,對稀疏矩陣的處理也更加快速,有效率!!**)
---
## 池化層(pooling)
**在介紹池化層之前,我們先捋一捋到現在我們做了什麼**。卷積層通過卷積運算提取特徵,得到比原始圖更小的特徵圖,之後我們再通過ReLU層將特徵圖中的負相關的資料置為0,得到了一個更加稀疏的特徵矩陣,資料量進一步減少了,**但是這還不夠,我們這兒通過池化層進一步削減資料量**。
首先,我們需要先了解一下池化的概念。有兩種池化方式,分別是最大池化(Max Pooling)、平均池化(Average Pooling)。**顧名思義,最大池化就是取最大值,平均池化就是取平均值**。**其次我們通過上述同樣的例子來理解以下池化層具體做了什麼操作。** 假設池化視窗我們設定為2X2,類比於卷積層在滑動視窗上不斷做卷積運算,池化層就是在滑動視窗上不斷做池化運算,那池化運算怎麼做呢(**最大池化,取視窗內的最大值;平均池化,取視窗內的平均值**)?**以最大池化為例,如下圖所示:**

(**看著上面這個圖,應該很容易理解最大池化怎麼做了吧?**)
由於最大池化保留了每個小視窗內的最大值,因此可以認為最大池化相當於保留了視窗內的最佳匹配結果。現在從圖片壓縮角度來看看從卷積層、ReLU層到現在的池化層,我們原始的輸入大小是怎麼變化的。原始輸入是5X5的一個矩陣(先假設通道為1,即不算三原色),經過卷積層、ReLU層之後變為3X3稀疏矩陣,再經過池化層之後變為了2X2矩陣,是我們肉眼可見的壓縮啊!!其實每一層也可以理解成是在做特徵提取,只是最開始提取的可能是比較區域性的特徵(比如邊緣啊,斜邊啊啥的),而層層疊加之後提取的可能是比較全域性的一個特徵,比較形狀啊啥的,**對於CNN各層(卷積、ReLU、池化),我個人大概是這麼理解的**。(**以上各層是可以反覆使用的,取決於我們的具體需求**)
---
## 全連線層(Full-Connected)
在講全連線層之前,我們需要知道全連線層之前的所有操作都是在做一個特徵提取,提取出來的特徵輸入全連線層,利用全連線層來判定該圖片是屬於哪一個型別的圖片(其實就是分類,如菱形、正方形、長方形等等)。之前在[pytorch_第四篇_使用pytorch快速搭建神經網路實現二分類任務(包含示例)](https://www.cnblogs.com/wangqinze/p/13424368.html)我們學習過利用神經網路來進行分類,那捲積網路中的全連線層與傳統神經網路是類似的。**接受樣本的特徵作為輸入,輸出樣本所屬各個類的概率,這是全連線層所做的事情**。那捲積神經網路中的特徵怎麼來呢?別忘了,全連線層之前都是在做特徵提取,如上述例子所示,假設我們最終得到了一個2X2的特徵圖,我們把特徵圖攤開來排成一排,也就意味著我們提取了原始圖片的4個特徵,這4個特徵值輸入全連線層可以幫助我們進行圖片的分類。該層的結構就和傳統的神經網路類似(全連線),這裡不再贅述。
---
## Softmax層
假設每個樣本有一個**隸屬向量V**,長度為類數,元素值代表該樣本屬於對應類別的概率,我們可以利用softmax函式來進行一個概率歸一化。**softmax函式如下所示(對v中第i個向量做歸一化操作,即該元素的指數,與向量中所有元素指數和的比值):**
$$
Softmax(i,v)={e^{v_i} \over \sum_{j}e^{v_j}}
$$
**由於多分類任務中模型輸出樣本對多個類的隸屬概率,因此我們再最後一層加入Softmax函式來進行一個概率歸一化。**
---
[本文參考-1](https://github.com/zergtant/pytorch-handbook/blob/master/chapter2/2.4-cnn.ipynb)
[本文參考-2](https://zhuanlan.zhihu.com/p/27