
小白學PyTorch 動態圖與靜態圖的淺顯理解
阿新 • • 發佈:2020-08-23
**文章來自公眾號【機器學習煉丹術】,回覆“煉丹”即可獲得海量學習資料哦!**
[TOC]
本章節縷一縷PyTorch的動態圖機制與Tensorflow的靜態圖機制(最新版的TF也支援動態圖了似乎)。
## 1 動態圖的初步推導
- 計算圖是用來描述運算的**有向無環圖**
- 計算圖有兩個主要元素:結點(Node)和邊(Edge);
- **結點表示資料** ,如向量、矩陣、張量;
- **邊表示運算** ,如加減乘除卷積等;
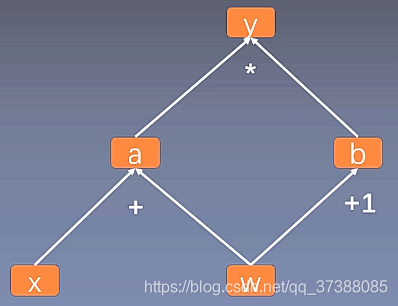
上圖是用計算圖表示:
$y=(x+w)∗(w+1)y=(x+w)∗(w+1)$
其中呢,$a=x+w$ ,$b=w+1$ , $y=a∗b$. (a和b是類似於中間變數的那種感覺。)
Pytorch在計算的時候,就會把計算過程用上面那樣的動態圖儲存起來。現在我們計算一下y關於w的梯度:
$\frac{\partial y}{\partial w} = \frac{\partial y}{\partial a} \frac{\partial a}{\partial w} + \frac{\partial y}{\partial b} \frac{\partial b}{\partial w}$
$=2\times w + x + 1=5$
(上面的計算中,w=1,x=2)
現在我們用Pytorch的程式碼來實現這個過程:
```python
import torch
w = torch.tensor([1.],requires_grad = True)
x = torch.tensor([2.],requires_grad = True)
a = w+x
b = w+1
y = a*b
y.backward()
print(w.grad)
```
得到的結果:

## 2 動態圖的葉子節點

這個圖中的葉子節點,是w和x,是整個計算圖的根基。之所以用葉子節點的概念,是為了**減少記憶體,在反向傳播結束之後,非葉子節點的梯度會被釋放掉** , 我們依然用上面的例子解釋:
```python
import torch
w = torch.tensor([1.],requires_grad = True)
x = torch.tensor([2.],requires_grad = True)
a = w+x
b = w+1
y = a*b
y.backward()
print(w.is_leaf,x.is_leaf,a.is_leaf,b.is_leaf,y.is_leaf)
print(w.grad,x.grad,a.grad,b.grad,y.grad)
```
執行結果是:

可以看到只有x和w是葉子節點,然後反向傳播計算完梯度後(```.backward()```之後),只有葉子節點的梯度儲存下來了。
當然也可以通過```.retain_grad()```來保留非任意節點的梯度值。
```python
import torch
w = torch.tensor([1.],requires_grad = True)
x = torch.tensor([2.],requires_grad = True)
a = w+x
a.retain_grad()
b = w+1
y = a*b
y.backward()
print(w.is_leaf,x.is_leaf,a.is_leaf,b.is_leaf,y.is_leaf)
print(w.grad,x.grad,a.grad,b.grad,y.grad)
```
執行結果:

## 3. grad_fn
```torch.tensor```有一個屬性```grad_fn```,```grad_fn```的作用是記錄建立該張量時所用的函式,這個屬性反向傳播的時候會用到。例如在上面的例子中,```y.grad_fn=MulBackward0```,表示y是通過乘法得到的。所以求導的時候就是用乘法的求導法則。同樣的,```a.grad=AddBackward0```表示a是通過加法得到的,使用加法的求導法則。
```python
import torch
w = torch.tensor([1.],requires_grad = True)
x = torch.tensor([2.],requires_grad = True)
a = w+x
a.retain_grad()
b = w+1
y = a*b
y.backward()
print(y.grad_fn)
print(a.grad_fn)
print(w.grad_fn)
```
執行結果是:

葉子節點的```.grad_fn```是None。
## 4 靜態圖
兩者的區別用一句話概括就是:
- 動態圖:pytorch使用的,運算與搭建同時進行;靈活,易調節。
- 靜態圖:老tensorflow使用的,先搭建圖,後運算;高效,不靈活。
靜態圖我們是需要先定義好運算規則流程的。比方說,我們先給出
$a = x+w$ , $b=w+1$ , $y=a\times b$
然後把上面的運算流程儲存下來,然後把w=1,x=2放到上面運算框架的入口位置進行運算。而動態圖是直接對著已經賦值的w和x進行運算,然後變運算變構建運算圖。
在一個課程http://cs231n.stanford.edu/slides/2018/cs231n_2018_lecture08.pdf中的第125頁,有這樣的一個對比例子:

這個程式碼是Tensorflow的,構建運算的時候,先構建運算框架,然後再把具體的數字放入其中。整個過程類似於訓練神經網路,我們要構建好模型的結構,然後再訓練的時候再吧資料放到模型裡面去。又類似於在旅遊的時候,我們事先定要每天的行程路線,然後每天按照路線去行動。
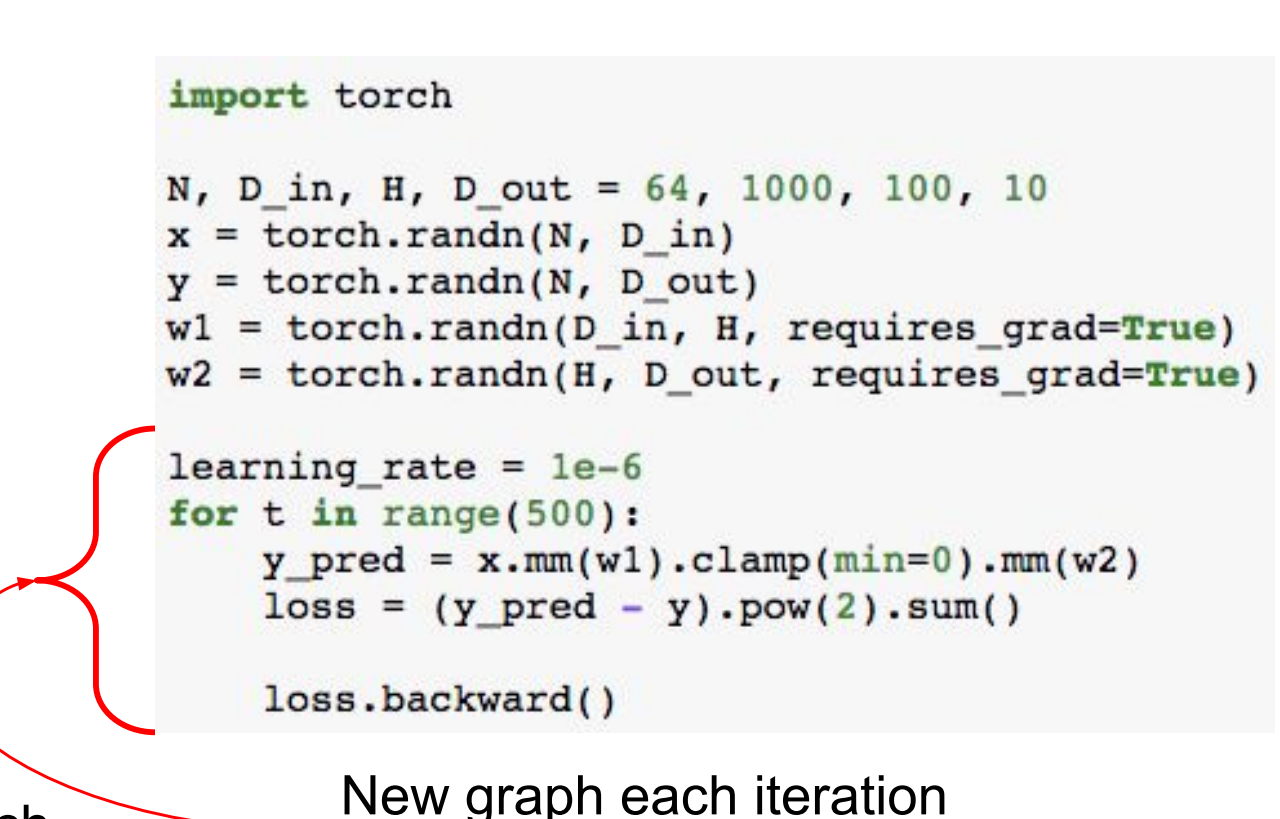
動態圖呢,就是直接對資料進行運算,然後動態的構建出運算圖。很符合我們的運算習慣。
兩者的區別在於,靜態圖先說明資料要怎麼計算,然後再放入資料。假設要放入50組資料,運算圖因為是事先構建的,所以每一次計算梯度都很快、高效;動態圖的運算圖是在資料計算的同時構建的,假設要放入50組資料,那麼就要生成50次運算圖。這樣就沒有那麼高效。所以稱為**動態圖**。
動態圖雖然沒有那麼高效,但是他的優點有以下:
1. 更容易除錯。
2. 動態計算更適用於自然語言處理。(這個可能是因為自然語言處理的輸入往往不定長?)
3. 動態圖更面向物件程式設計,我們會感覺更加