
Spark Job-Stage-Task例項理解
阿新 • • 發佈:2020-09-21
# Spark Job-Stage-Task例項理解
基於一個word count的簡單例子理解Job、Stage、Task的關係,以及各自產生的方式和對並行、分割槽等的聯絡;
### 相關概念
- Job:Job是由Action觸發的,因此一個Job包含一個Action和N個Transform操作;
- Stage:Stage是由於shuffle操作而進行劃分的Task集合,Stage的劃分是根據其寬窄依賴關係;
- Task:最小執行單元,因為每個Task只是負責一個分割槽的資料
處理,因此一般有多少個分割槽就有多少個Task,這一類的Task其實是在不同的分割槽上執行一樣的動作;
### 例子程式碼
```python
'''
DAG: Job vs Stage vs Task
'''
# 初始化spark環境
from pyspark import SparkContext,SparkConf
conf = SparkConf()
conf.setMaster('local').setAppName('Job vs Stage vs Task')
sc = SparkContext(conf=conf)
alpha_rdd1 = sc.parallelize(['a c','a b','b c','b d','c d'],10)
word_count1 = alpha_rdd1.flatMap(lambda a:a.split(' ')).map(lambda a:(a,1)).reduceByKey(lambda x,y:x+y)
alpha_rdd2 = sc.parallelize(['a c','a b','b c','b d','c d'],10)
word_count2 = alpha_rdd2.flatMap(lambda a:a.split(' ')).map(lambda a:(a,1)).reduceByKey(lambda x,y:x+y)
word_count1.join(word_count2).collect()
print('END')
input() # input是方便指令碼執行不會終止導致web ui不能正常瀏覽
```
可以看到,主要的資料處理邏輯分為三部分,分別是兩個word count,以及最後對兩個結果的join,事實上這也對應了3個stage,下面是程式碼與stage的對應圖,注意圖中的並行關係:
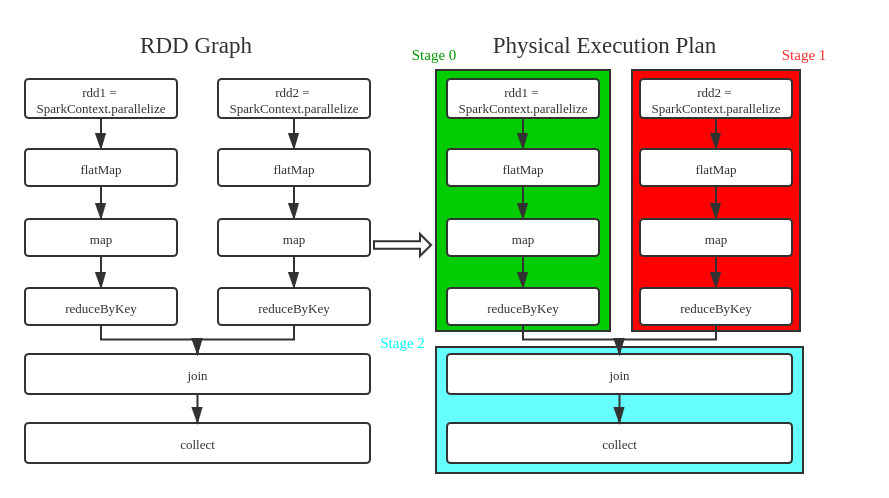
從圖中可以看出,原始碼只有一個action(collect),因此只有一個Job,這個Job被換分為3個Stage,劃分原因是有shuffle出現(reductByKey),而明顯看出的是Stage 0和Stage 1互相沒有依賴關係,因此可以並行,而Stage 2則是依賴於0和1的,因此會最後一個執行;
### Spark Web UI
下面通過Web UI來進一步檢視Job、Stage、Task的關係;

從上圖看到,只有一個已完成的Job,該Job包含3個Stage,30個Task(注意之前的程式碼裡parallelize設定的分割槽數為10,3*10=30);

上圖表示該Job的執行時間線圖,可以明顯的看到Stage0和Stage1在時間上有大部分重疊,也就是並行進行,而Stage2是在Stage1結束後才開始,因為Stage0結束的更早,這裡對於依賴關係的展示還是很明顯的;
另外,對於stage0和stage1,雖然處理的資料量很小,但是依然可以看出二者的執行時間比較接近,也就是沒有明顯的資料偏斜的情況出現,當然,這裡因為只是測試資料,而真實場景下很容易出現個別stage執行時間遠遠超過其他的stage,導致整體的時間被拖長;

上圖是該Job對應的DAG視覺化圖,它是直接的對Stage以及Stage間的依賴關係進行展示,也驗證了我們之前的分析,這裡每個Stage還可以繼續點進去;

上圖中可以更清晰的看到,每個Stage中都包含10個Task,其實就是對應10個partition,對於Stage0和Stage1,他們都是在shuffle前的Stage,因此他們都有Shuffle Write的動作,大小都是514,而Stage2則是join這兩部分資料,因此有Shuffle Read動作,大小而前二者之和,也就是1028;