神經網路模型與誤差逆傳播演算法
阿新 • • 發佈:2021-01-10
[toc]
#### 一、神經元模型
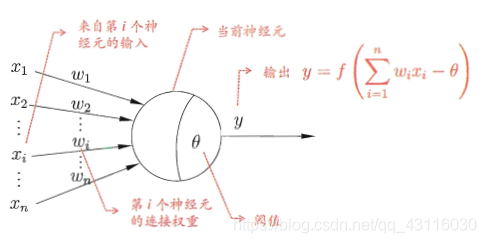
##### 1.1 M-P神經元
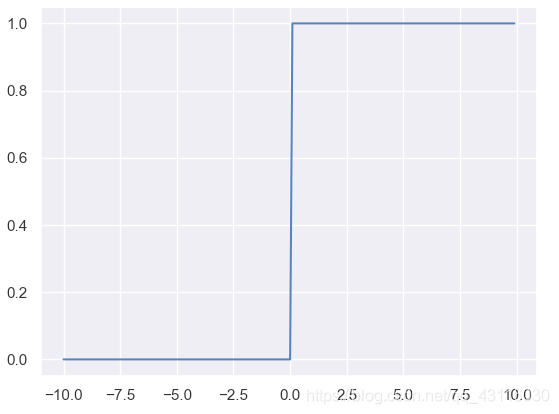
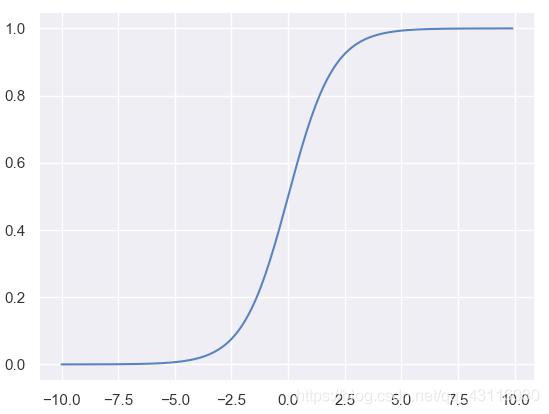
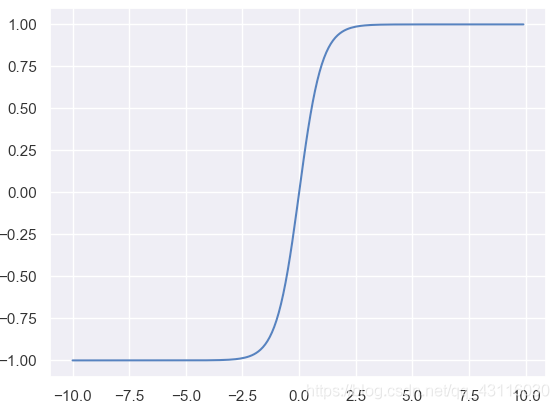
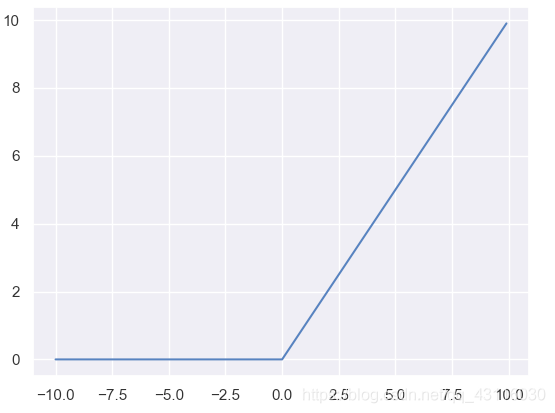
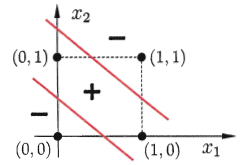
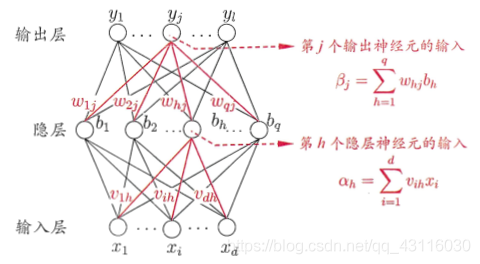
**神經元**(***neuron***)模型是神經網路的基本組成部分,它參考了生物神經元的工作原理:通過多個樹突接收輸入,在神經元進行處理後,如果電平訊號超過某個**闕值**(***threshold***),那麼該神經元就會被啟用並通過一個軸突向其他神經元傳送訊號。對上述流程進行數學抽象,便可以得到如下的**M-P神經元模型**: