
Spark推薦系統實踐
推薦系統是根據使用者的行為、興趣等特徵,將使用者感興趣的資訊、產品等推薦給使用者的系統,它的出現主要是為了解決資訊過載和使用者無明確需求的問題,根據劃分標準的不同,又分很多種類別:
- 根據目標使用者的不同,可劃分為基於大眾行為的推薦引擎和個性化推薦引擎
- 根據資料之間的相關性,可劃分為基於人口統計學的推薦和基於內容的推薦
......
通常,我們在討論推薦系統時主要是針對個性化推薦系統,因為它才是更加智慧的資訊發現過程。在個性化推薦系統中,協同過濾演算法是目前應用最成功也是最普遍的演算法,主要包括兩大類,基於使用者的協同過濾演算法和基於物品的協同過濾演算法。
此外,在實際的推薦系統中,往往會針對不同的場景使用不同的策略以及多策略組合,從而達到最好的推薦效果。
本篇文章主要通過應用Spark KMeans、ALS以及基於內容的推薦演算法來進行推薦系統的構建,具體涉及到的資料、表和程式碼比較多,後續會在github上給出詳細說明。
首先看一下推薦系統的概況圖:
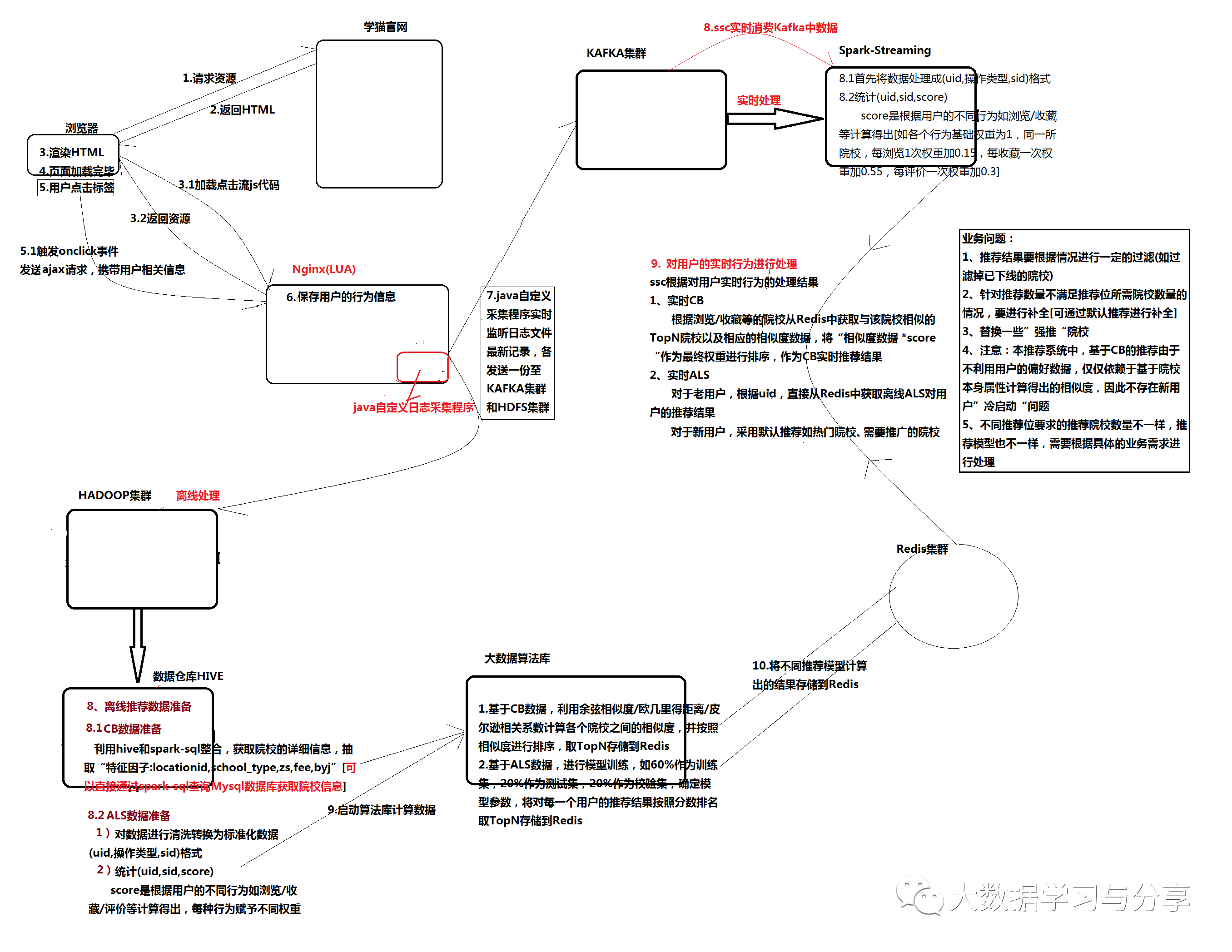
下面主要針對推薦演算法的應用和推薦過程做詳細闡述。
1. 基於Spark KMeans實現對院校聚類
1.1 資料準備
通過院校資訊的結構化資料school.txt和school_loca.txt,將兩個結構化檔案載入到hive表中。
(1)school.txt資料樣例
院校id 名稱 地址 型別 住宿方式 學費 備用金 運營歸屬 授權平臺 稽核狀態 1,諾丹姆吉本斯主教中學(Notre Dame-Bishop Gibbons School),紐約州-斯克內克塔迪,混校,寄宿家庭,283047,13289,UC獨家代理,校代網/微信,稽核通過 2,畢曉普馬金高中(Bishop Maginn High School),紐約州-奧爾巴尼,混校,寄宿家庭,277488,13028,UC獨家代理,校代網/微信,稽核通過
school.txt載入到hive表中的表結構資訊:
schoolid int ##院校id name string ##院校名稱 location string ##院校地址 type string ##學校型別 zhusu string ##住宿方式 fee double ##學費 byj double ##備用金 yygs string ##運營歸屬 sqpt string ##授權平臺 shzt string ##稽核狀態
(2)school_loca.txt資料樣例
地址id 地址名稱 1,加利福尼亞州-洛杉磯 2,紐約州-裡弗黑德 3,新澤西州-萊克伍德市 4,安大略省-鮑曼維爾市
school_loca.txt載入到hive表中的表結構資訊
locationid int ##院校地址id name string ##院校地址名稱
(3)對院校資訊進行量化處理
sql語句示例: select sd.schoolid, sd.name schoolname, sd.location, sl.locationid, (case when sd.type="混校" then "0" when sd.type="男校" then "1" when sd.type="女校" then "2" end) as school_type, (case when sd.zhusu="寄宿家庭" then "0" when sd.zhusu="學校宿舍" then "1" when sd.zhusu="男生學校宿舍/女生寄宿家庭" then "2" when sd.zhusu="學校宿舍/寄宿家庭" then "3" when sd.zhusu="學校宿舍-寄宿家庭" then "3" end) as zs, sd.fee, sd.byj from school2_detail sd join school2_location sl on sd.location = sl.name;
提取出唯一描述一所院校的“特徵因子”:學校地址id(locationid)、學校型別(school_type)、住宿方式(zs)、學費(fee)、備用金(byj),並將這些"特徵因子"進行量化(除了locationid、fee、byj按照實際值進行量化,scool_type、zs量化標準參考上述sql語句)。
1.2 資料歸一化處理
首先了解一個概念,奇異樣本資料資料:指相對於其他輸入樣本特別大或特別小的樣本向量。奇異樣本資料資料的存在會引起訓練時間增大,並可能引起無法收斂。所以在存在奇異樣本資料的情況下,進行訓練之前最好進行歸一化,如果不存在奇異樣本資料,則可以不用歸一化。
院校"特徵因子"具有不同的量綱,為了消除指標之間的量綱影響,需要進行資料標準化處理,以解決資料指標之間的可比性。原始資料經過資料標準化處理後,各指標處於同一數量級,適合進行綜合對比評價。
本資料處理採取歸一化方式:最大—最小標準化。
最大—最小標準化是對原始資料進行線性變換,設MIN(A)和MAX(A)分別是屬性A的最小值和最大值,將A的一個原始值x通過最大—最小標準化對映到區間[0, 1]的值x’,那麼公式如下:x’ = (x - MIN(A)) / (MAX(A) - MIN(A))。
在院校資訊中,school_type、zs往往取值較小,而fee、byj取值較大,量綱對資料分析時會產生一定影響,需要進行歸一化處理:
schoolId schoolName locationId school_type zs fee byj 歸一化前:1 諾丹姆吉本斯主教中學(Notre Dame-Bishop Gibbons School) 71 0 0 283047.0 13289.0 歸一化後:1 諾丹姆吉本斯主教中學(Notre Dame-Bishop Gibbons School) 0.693069306930693 0.0 0.0 0.4018890324907577 0.4000060201071579
歸一化處理sql語句示例:
create table school2_detail_number as select sd.schoolid, sd.name schoolname, sl.locationid, (case when sd.type="混校" then "0" when sd.type="男校" then "1" when sd.type="女校" then "2" end) as school_type, (case when sd.zhusu="寄宿家庭" then "0" when sd.zhusu="學校宿舍" then "1" when sd.zhusu="男生學校宿舍/女生寄宿家庭" then "2" when sd.zhusu="學校宿舍/寄宿家庭" then "3" when sd.zhusu="學校宿舍-寄宿家庭" then "3" end) as zs, sd.fee, sd.byj from school2_detail sd join school2_location sl = = = table school2_detail_number_gyh 最終歸一化結果表 = = = = create table school2_detail_number_gyh as select t1.schoolid, t1.name, (t1.locationid-t2.min_lid)/(t2.max_lid-t2.min_lid) as gyh_lid, (t1.school_type-t2.min_type)/(t2.max_type-t2.min_type) as gyh_school_type, (t1.zs-t2.min_zs)/(t2.max_zs-t2.min_zs) as gyh_zs, (t1.fee-t2.min_fee)/(t2.max_fee-t2.min_fee) as gyh_fee, (t1.byj-t2.min_byj)/(t2.max_byj-t2.min_byj) as gyh_byj from school2_detail_number t1 join (select MAX(locationid) as max_lid, MIN(locationid) as min_lid, MAX(school_type) as max_type, MIN(school_type) as min_type, MAX(zs) as max_zs, MIN(zs) as min_zs, MAX(fee) as max_fee, MIN(fee) as min_fee, MAX(byj) as max_byj, MIN(byj) as min_byj from school2_detail_number) as t2;
2. 基於內容的推薦
2.1 基於內容推薦概述
基於內容的推薦(CB):主要是根據使用者過去喜歡的物品(item),為使用者推薦和他過去喜歡的物品相似的物品,關鍵在於item相似度的度量。CB的過程一般包括以下三步:
1. 根據item的屬性抽取一些特徵來表示此item
2. 利用一個使用者過去喜歡(及不喜歡)的item特徵資料,來學習此使用者的喜好特徵
3. 通過比較上一步得到的使用者喜好特徵與“候選”item特徵,為此使用者推薦一組相似度較大的item
優點:易於實現,不需要使用者資料因此不存在稀疏性和冷啟動問題;基於物品本身特徵推薦,因此不存在過度推薦熱門的問題。
缺點:抽取的特徵既要保證準確性又要具有一定的實際意義,否則很難保證推薦結果的相關性。
2.2 相似度演算法描述
1. 歐幾里得距離
衡量空間各個點之間的絕對距離,跟各個點所在位置的座標直接相關。歐氏距離能夠體現個體數值特徵的絕對差異,所以更多的用於需要從維度的數值大小中體現差異的分析,如使用使用者行為指標分析使用者價值的相似度或差異。值域範圍[0,正無窮大]
2. 皮爾遜相關係數
強調的是空間中各點之間的線性相關關係。值域範圍[-1,1]。0代表無相關性,負值代表負相關,正值代表正相關
3. 餘弦相似度
衡量空間向量的夾角,主要體現在方向上的差異,而不是位置。比如A、B兩點:保持A點位置不變,B點朝原方向遠離座標軸原點,則二者之間的餘弦距離是保持不變的(因為夾角沒有變化),但A、B兩點的距離明顯發生變化。餘弦距離更多的是從方向上區分差異,而對絕對的數值不敏感,更多的用於使用使用者對內容評分來區分興趣的相似度和差異,同時修正了使用者間可能存在的度量標準不統一的問題(因為餘弦距離對絕對數值不敏感)。值域範圍[-1,1]
2.3 資料準備和處理
同“基於Spark KMeans對院校進行聚類”中的資料準備
對於相似度演算法實現,參考文章《Spark實現推薦系統中的相似度演算法》
2.4 具體實現邏輯
待處理資料示例:
院校id 院校名稱 院校地址 院校地址id 學校型別 住宿方式 學費 備用金 1,諾丹姆吉本斯主教中學(Notre Dame-Bishop Gibbons School),紐約州-斯克內克塔迪,71,0,0,283047.0,13289.0 2,畢曉普馬金高中(Bishop Maginn High School),紐約州-奧爾巴尼,25,0,0,277488.0,13028.0 4,薩拉託加中央天主中學(Saratoga Central Catholic School),紐約州-薩拉託加斯普林斯,72,0,0,285705.0,13289.0 5,天主教中央中學(Catholic Central High School),紐約州-特洛伊,66,0,0,283047.0,13289.0
實現思路:根據上述獲得院校詳細資料,提取出特徵因子,計算各個院校之間的相似度並根據相似度倒序排序,並計算每個院校與它相似的院校取TopN儲存到reids中【注意:去掉基準院校】。
3. 基於SparkALS實現離線推薦
3.1 Spark基於模型協同過濾推薦演算法ALS
Spark沒有像mahout那樣,嚴格區分基於物品的協同過濾推薦(ItemCF)和基於使用者的協同過濾推薦(UserCF)。只有基於模型的協同過濾推薦演算法ALS(model-based CF)。
ALS通過數量相對少的未被觀察到的隱藏因子,來解釋大量使用者和物品之間潛在聯絡。ALS基於矩陣分解通過降維的方法來補全使用者-物品矩陣,對矩陣中沒有出現的值進行估計。
ALS基本假設:任何一個評分矩陣均可近似分解成兩個低維的使用者特徵矩陣和物品特徵矩陣。矩陣分解過程可理解成將使用者和物品均抽象的對映到相同的低維潛在特徵空間中。
3.2 具體實現邏輯
3.2.1 預處理日誌資料獲得使用者對院校的“綜合分數”
通過處理採集到的日誌資料,得到school_als.txt,示例如下:
|
使用者id,操作型別(瀏覽/收藏等),院校id 1,瀏覽,14 1,瀏覽,26 1,瀏覽,1 1,收藏,1 2,瀏覽,15 2,瀏覽,8 2,瀏覽,12 2,瀏覽,10 |
根據使用者id和院校id分組獲得各個使用者對院校的操作型別的次數,從而計算最終對應院校的分值(score)【注意:這裡暫且將各個操作型別的基礎權重設為1,瀏覽一次權重加0.15、收藏一次權重加0.55,評論一次權重加0.3。後續具體根據業務來定具體的權重】。最終得到的資料示例如下:
使用者id,院校id,分數,唯一標示id(方便後邊切分資料訓練ALS模型) ((1,16,1.15),16) ((1,3,1.15),87) ((1,26,2.3),88) ((1,34,1.15),154)
3.2.2 訓練Spark ALS模型,進行推薦
1. 準備資料
1)“歷史”綜合評分資料:將上一步處理得到的資料,轉換成ALS的Rating格式資料,並將唯一標示id模於10(用於切分資料)
2)院校資料(school.txt)處理成(院校id -> 院校名稱)並轉成map
3)單一使用者“實時”綜合評分資料:使用者在頁面實時的行為資料並處理成“使用者id,院校id,綜合分數”的格式
2. 切分資料
將“綜合評分資料”切分成3個部分,60%用於訓練(加上單一使用者“實時”綜合評分資料),20%用於校驗,20%用於測試
3. 訓練模型
spark ALS訓練API主要有這幾個引數:
ratings:使用者評分資料RDD[Rating]
rank:隱因子個數,越大計算量越大,一般越精確
iterations:迭代次數
lambda:控制正則化過程,值越高正則化程度越高
計算不同引數下,根據訓練集獲得的模型計算校驗集的RMSE(均方根誤差)RMSE最小的即為最佳模型。
將使用者“實時”瀏覽的院校去掉,其他院校作為“候選”推薦院校,根據訓練的最優模型取TopN進行推薦。
4. 基於ALS和CB的業務角度分析
4.1 針對使用者是否產生實時行為資料的不同處理
注意:由於本推薦系統中基於CB的推薦,是基於院校相似度的推薦(不依賴於使用者偏好度資料),只要使用者產生瀏覽/收藏等行為,就能基於瀏覽/收藏等的院校計算相似院校,所以不考慮新使用者“冷啟動”問題。
4.1.1 使用者產生實時行為資料(瀏覽/收藏/評論等,設定不同權重)1)ALS
正常處理
2)CB
參考下方"基於CB的離線和實時推薦結果落地分析"
4.1.2 使用者沒有產生實時行為資料
1)ALS老使用者:直接根據使用者歷史資料,按照ALS的正常處理邏輯進行處理
新使用者:可以推薦一些熱門院校、需要推廣的院校等
2)CB參考下方"基於CB的離線和實時推薦結果落地分析"
4.2 推薦結果"落地"分析
注意:
1. 原始載入的院校資料是最基層、完整的資料(包括下線院校),所以推薦院校集要過濾掉已下線院校再進行推薦【也可以在載入院校資料時通過sql語句過濾已下線院校,通過離線計算獲得的推薦院校集也就不包含已下線院校;實時的推薦結果也會利用離線的推薦結果集所以獲得推薦院校也不包含已下線院校。但是如果在離線結果已形成(當天或之前)或實時計算時下線院校更新而沒有及時更新相應的推薦資料會有一定延遲誤差】
2. 取TopN儲存到redis中,但實際推薦院校的時候只取TopN中的前幾個院校資料作為推薦,為了方便進行院校做CRUD處理時,redis中推薦資料的更新
3. 離線推薦結果和線上推薦結果進行彙總做最終推薦時,要過濾掉使用者已瀏覽的院校[根據業務具體需求看是否過濾掉近期已經推薦過的院校]
4. 最終推薦院校集數量可能不滿足需要推薦的院校數量,可以設定預設推薦集(如熱點院校)進行補全
4.2.1 離線結果"落地"分析
1. 基於CB的離線推薦結果"落地"
利用相似度演算法,分別計算每一所院校與其他院校的相似度(並根據相似度倒序排序)
==> 如果沒有新增院校或已有院校屬性("特徵因子")不改變,只需計算一次。計算量:200+所院校,計算4W+次。
將每個院校相似度計算結果,取TopN進行儲存(redis/HBase等)
==> 如儲存到redis中:以字首"recom:offlineCB:"和"基準院校id"拼接成的字串為key,以與基準院校”相似院校id:相似度”為value("recom:offlineCB:"+baseSchoolId,"sid1:sims1,sid2:sims2,…")
2. 基於Spark ALS的離線推薦結果"落地"
由於ALS需要訓練模型,如果每來一個使用者,產生了瀏覽/收藏等行為,ALS模型就要實時重新訓練一次,會有一定的延遲;當用戶比較多時產生的資料量也比較大,延遲性會進一步加大。因此,採取根據前一天及之前的歷史資料,每天訓練一次ALS模型,取TopN結果進行儲存(redis/HBase等)
==> 如儲存到redis中:以字首"recom:offlineALS:"和"使用者id"拼接成的字串為key,以"推薦給該使用者的院校id"為value("recom:offlineALS:"+uId,"sid1,sid2,sid3,…")
注意:設定redis的key字首是為了區別不同推薦模型
4.2.2 實時結果"落地"分析
使用者瀏覽官網,spark-streaming從kafka消費資料進行處理,先將資料處理成標準化資料:“使用者id,操作型別,院校id”,再處理成“使用者id,院校id,score”格式。
1. 基於CB的實時推薦結果"落地"
根據院校id從Redis中獲取該院校基於CB的相似度推薦列表,自定義一個類CusItem.scala(屬性:院校id,weight),以“score*相似度”作為最終權重weight並根據weight進行倒序排序,取TopN進行推薦(儲存到redis:以"recom:realCB:+userId"為key,以推薦院校id列表[拼接成字串]為value)
2. 基於spark ALS的實時推薦結果"落地"
老使用者直接通過使用者id獲取redis中ALS離線推薦結果(儲存到redis中:以"recom:realALS:+userId"為key,以推薦院校id列表[拼接成字串]為value)
4.3 基於院校"流行度"對實時和離線推薦結果的補充
主要是對熱門院校(比如點選率高的、申請率高的)、需要推廣的院校等進行推薦。可以根據PV、UV、日均PV或分享率等資料分析出熱門院校。能夠解決新使用者冷啟動問題,同時根據不同的使用者特點推薦不同的院校
4.4 院校資訊發生改變具體分析
當有“新增/刪除(包括院校下線)院校”或“已有院校屬性發生改變”時,後臺錄入對院校資訊進行處理的同時,非同步傳送一條訊息(如通過ActiveMQ,將院校id和對應的操作型別[add、delete、update])給“調整”計算院校相似度的程式,進行相應的處理。【注意:如果更新院校的屬性不是“特徵因子”,就不要傳送資訊了】
4.4.1 新增院校
step1:以新增院校為基準,計算其他院校與該院校的相似度資料,並按照相似度資料進行倒序排序,取TopN儲存到redis【去掉基準院校】
step2:以其他院校為基準,分別計算新增院校與其他院校的相似度,用該相似度與其他院校相似度資料中TopN院校最後一個院校的相似度資料比較,如果前者比後者小,不作任何操作;如果前者比後者大,根據TopN院校和新增院校的相似度資料進行倒序排序,去除相似度最小的,然後更新Redis中相應的資料
4.4.2 刪除院校(包括院校下線)
step1:刪除Redis中對應刪除院校的CB相似度資料
step2:兩種情況 =>1)“刪除院校”不在其他院校的TopN列表中,不更新Redis中其他院校的相似度資料
2)“刪除院校”在其他院校的TopN列表中,移除該院校[TopN列表移除完的情況:實際業務場景可能性比較小,可不考慮]
4.4.3 已有院校屬性發生改變
1. 改變屬性不是"特徵因子"
不作任何處理[讓業務方那邊先判斷一下改變的屬性是不是“特徵因子”,如果不是就不要發訊息了]。
特殊情況:改變屬性是“上線狀態”,如果由下線改為上線,則呼叫‘新增院校’的處理方法
2. 改變屬性是"特徵因子"
step1:更新自己redis中相似度資料
step2:更新其他院校[兩種方式:直接計算各個院校之間的相似度資料,但計算量為200*200+;下面的方式麻煩一點但相對計算量會少很多]1) 改變院校在其他院校redis中TopN列表計算該院校與其他院校的相似度資料,將該值與TopN列表最後一個院校相似度資料進行比較:如果前者比後者大則TopN排序更新redis資料;如果前者比後者小則,重新計算其他院校所有的相似度資料倒序取TopN2) 改變院校不在其他院校redis中TopN列表
計算該院校與其他院校的相似度資料,將該值與TopN列表最後一個院校相似度資料進行比較:如果前者比後者大,進行TopN相似度資料和改變院校相似度資料倒序排序,並移除最後一個;如果前者比後者小,不作處理。
對於上述的演算法模型實現邏輯以及具體的資料處理、推薦處理等除了演算法建模本身的考量,還要結合實際業務做相應調整,企業實際運用中要比上述複雜的多,包括推薦演算法的種類、訓練模型、資料的標準化,業務的場景,等等。本文更多是拋磚引玉,希望在大家做推薦系統的過程中給出一個參考思路。
關聯文章:
Spark MLlib中KMeans聚類演算法的解析和應用
Spark實現推薦系統中的相似度演算法
Hive常用效能優化方法實踐全面總結
SparkSQL真的不支援儲存NullType型別資料到Parquet嗎?
經典的SparkSQL/Hive-SQL/MySQL面試-練習題
Spark在處理資料的時候,會將資料都載入到記憶體再做處理嗎?
關於HDFS應知應會的幾個問題
如何獲取流式應用程式中checkpoint的最新offset
關於一些技術點的隨筆記錄
關注微信公眾號:大資料學習與分享,獲取更對技術