
RandomForest 隨機森林演算法與模型引數的調優
阿新 • • 發佈:2021-01-19
> **公號:碼農充電站pro**
> **主頁:**
本篇文章來介紹**隨機森林**(*RandomForest*)演算法。
### 1,整合演算法之 bagging 演算法
在前邊的文章《[AdaBoost 演算法-分析波士頓房價資料集](https://www.cnblogs.com/codeshell/p/14149923.html)》中,我們介紹過**整合演算法**。整合演算法中有一類演算法叫做 **bagging** 演算法。
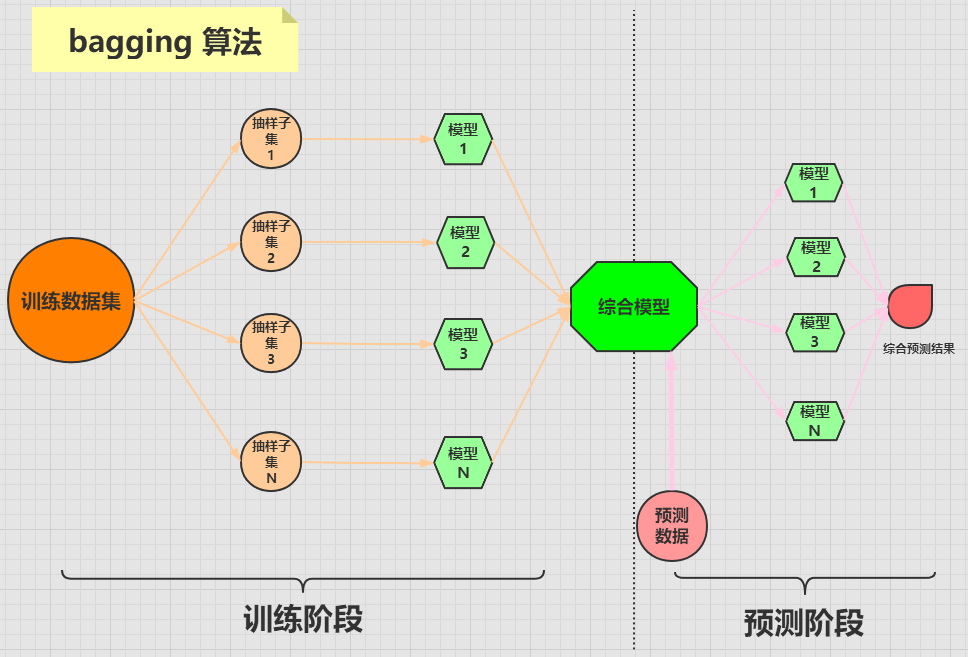
**bagging** 演算法是將一個原始資料集隨機抽樣成 **N** 個新的資料集。然後將這 **N** 個新的資料集作用於同一個機器學習演算法,從而得到 **N** 個模型,最終整合一個綜合模型。
在對新的資料進行預測時,需要經過這 **N** 個模型(每個模型互不依賴干擾)的預測(投票),最終綜合 **N** 個投票結果,來形成最後的預測結果。
**bagging** 演算法的流程可用下圖來表示:
### 2,隨機森林演算法
隨機森林演算法是 **bagging** 演算法中比較出名的一種。
隨機森林演算法由多個決策樹分類器組成,每一個子分類器都是一棵 **CART** 分類迴歸樹,所以隨機森林既可以做分類,又可以做迴歸。
當隨機森林演算法處理分類問題的時候,分類的最終結果是由所有的子分類器投票而成,投票最多的那個結果就是最終的分類結果。
當隨機森林演算法處理迴歸問題的時候,最終的結果是每棵 **CART** 樹的迴歸結果的平均值。
### 3,隨機森林演算法的實現
**sklearn** 庫即實現了**隨機森林分類樹**,又實現了**隨機森林迴歸樹**:
- [RandomForestClassifier](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html):分類樹
- [RandomForestRegressor](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestRegressor.html):迴歸樹
**RandomForestClassifier** 類的原型如下:
```python
RandomForestClassifier(n_estimators=100,
criterion='gini', max_depth=None,
min_samples_split=2, min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
bootstrap=True, oob_score=False,
n_jobs=None, random_state=None,
verbose=0, warm_start=False,
class_weight=None, ccp_alpha=0.0,
max_samples=None)
```
可以看到分類樹的引數特別多,我們來介紹幾個重要的引數:
- **n_estimators**:隨機森林中決策樹的個數,預設為 100。
- **criterion**:隨機森林中決策樹的演算法,可選的有兩種:
- **gini**:基尼係數,也就是 **CART 演算法**,為預設值。
- **entropy**:資訊熵,也就是 **ID3 演算法**。
- **max_depth**:決策樹的最大深度。
**RandomForestRegressor** 類的原型如下:
```python
RandomForestRegressor(n_estimators=100,
criterion='mse', max_depth=None,
min_samples_split=2, min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
bootstrap=True, oob_score=False,
n_jobs=None, random_state=None,
verbose=0, warm_start=False,
ccp_alpha=0.0, max_samples=None)
```
迴歸樹中的引數與分類樹中的引數基本相同,但 **criterion** 引數的取值不同。
在迴歸樹中,**criterion** 引數有下面兩種取值:
- **mse**:表示**均方誤差演算法**,為預設值。
- **mae**:表示**平均誤差演算法**。
### 4,隨機森林演算法的使用
下面使用隨機森林分類樹來處理[鳶尾花資料集](https://github.com/scikit-learn/scikit-learn/blob/master/sklearn/datasets/data/iris.csv),該資料集在《[決策樹演算法-實戰篇](https://www.cnblogs.com/codeshell/p/13984334.html)》中介紹過,這裡不再介紹,我們直接使用它。
首先載入資料集:
```python
from sklearn.datasets import load_iris
iris = load_iris() # 準備資料集
features = iris.data # 獲取特徵集
labels = iris.target # 獲取目標集
```
將資料分成**訓練集**和**測試集**:
```python
from sklearn.model_selection import train_test_split
train_features, test_features, train_labels, test_labels =
train_test_split(features, labels, test_size=0.33, random_state=0)
```
接下來構造隨機森林分類樹:
```python
from sklearn.ensemble import RandomForestClassifier
# 這裡均使用預設引數
rfc = RandomForestClassifier()
# 訓練模型
rfc.fit(train_features, train_labels)
```
`estimators_` 屬性中儲存了訓練出來的所有的子分類器,來看下子分類器的個數:
```python
>