
二分類問題中混淆矩陣、PR以及AP評估指標
阿新 • • 發佈:2021-02-18
仿照上篇博文對於混淆矩陣、ROC和AUC指標的探討,本文簡要討論機器學習二分類問題中的混淆矩陣、PR以及AP評估指標;實際上,(ROC,AUC)與(PR,AP)指標對具有某種相似性。
####按照循序漸進的原則,依次討論混淆矩陣、PR和AP:
設定一個機器學習問題情境:給定一些腫瘤患者樣本,構建一個分類模型來預測腫瘤是良性還是惡性,顯然這是一個二分類問題。
本文中,將良性腫瘤視為正類標籤(可能在具體實踐中更為關注惡性腫瘤,不過這並不影響技術上的操作)。
當分類模型選定以後,將其在測試資料集上進行評估,分別可以得到以下評估指標:
##混淆矩陣
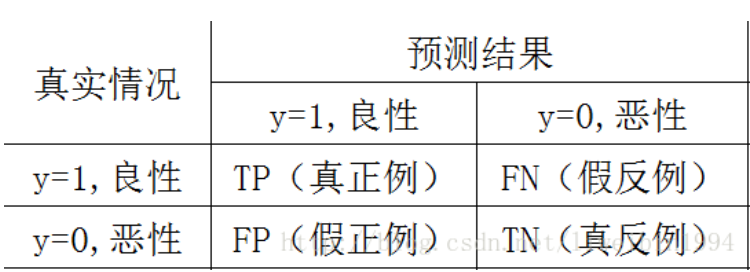
TP表示預測為良性,真實情況是良性的樣例數;
FN表示預測為惡性,真實情況是良性的樣例數;
FP表示預測為良性,真實情況是惡性的樣例數;
TN表示預測為惡性,真實情況是惡性的樣例數;
以上四類資料構成混淆矩陣。
##PR
在混淆矩陣的基礎上,進一步地定義兩個指標。
####按照下式定義precision(P)指標
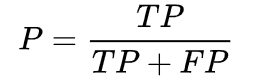
precision表示,預測為正的樣本中有多少是真正的正樣本;精準率強調對某類樣本識別的準確性。
####按照下式定義recall(R)指標
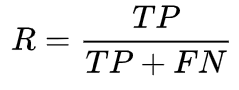
recall表示,樣本中的正例有多少被預測正確了;召回率強調對某類樣本識別的全面性。
precision,recall分別反映分類器對某一類樣本鑑別能力的兩個方面;通常,這兩個指標呈現互斥關係,即一個指標高了往往會致使另一指標降低。
####由上,一個混淆矩陣對應一對(precision,recall)
需要明確的是,P和R是建立在類別明確的預測結果之上的,即分類模型明確地指出待預測樣本的類別。
然而,在二分類問題(0,1)中,一般模型最後的輸出是一個概率值,表示結果是1的概率。此時需要確定一個閾值,若模型的輸出概率超過閾值,則歸類為1;若模型的輸出概率低於閾值,則歸類為0。
不同的閾值會導致分類的結果不同,也就是混淆矩陣有差,P和R也就不同。
當閾值從0開始慢慢移動到1的過程,就會形成很多對(precision,recall)的值,將它們畫在座標系上,就是所謂的PR曲線了。
##AP
得到PR曲線後,就可以計算曲線下方的面積,計算出來的面積就是AP值。
一般而言,AP越大,模型的效能越好。
##示例
![](https://img2020.cnblogs.com/blog/1875829/202102/1875829-20210218115231506-19239447