
使用迴歸分析預測連續型變數
線性迴歸模型
線性函式的定義如下:
h(x)=w1x1+w2x2+...+wdxd+b=wTx+b
給定資料集
D={(xi,yi)}1N,其中
xi,yi都是連續型變數。線性迴歸試圖去學習到
h(x)能準確地預測
y。
迴歸任務最常用的效能度量就是均平方誤差(MSE,mean squared error):
J(w,b)=21i=1∑N(yi−h(xi))2=21i=1∑N(yi−wTxi+b)2
引數的優化:(入門人士只需掌握(1)即可,實用簡單)
(1)可以使用梯度下降來優化誤差,每一步的更新為:
wj:=wj−η∂wj∂J(w,b)=wj−ηi=1∑N(yi−h(xi))xij,j=1,2,...db:=b−η∂b∂J(w,b)=wj−ηi=1∑N(yi−h(xi)),j=1,2,...d
(2)最小二乘估計:
將
w和
b合起來寫為
w^=(w;b),把資料集表示為
N×(d+1)的矩陣,前
d個元素對應屬性值,最後一個數為
1對應引數
b。
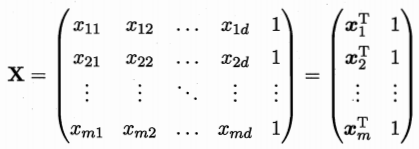
標記也寫為向量的形式:
y=(y1;y2;...;yN),則求最小化誤差的引數
w^可表示為:
相關推薦
使用迴歸分析預測連續型變數
線性迴歸模型 線性函式的定義如下: h ( x
神經網絡實現連續型變量的回歸預測(python)
是我 labels set 直接 append TP 輸入數據 main setup 轉至:https://blog.csdn.net/langb2014/article/details/50488727 輸入數據變為房價預測: 105.0,2,0.89,510.010
機器學習實戰——預測數值型資料:迴歸 實現記錄
關於利用資料集繪圖建立模型 >>> import regression >>> xArr, yArr= regression.loadDataSet('ex0.txt') >>> ws= regression.standRegres(xAr
《用Python玩轉資料》專案—線性迴歸分析入門之波士頓房價預測(二)
接上一部分,此篇將用tensorflow建立神經網路,對波士頓房價資料進行簡單建模預測。 二、使用tensorflow擬合boston房價datasets 1、資料處理依然利用sklearn來分訓練集和測試集。 2、使用一層隱藏層的簡單網路,試下來用當前這組超引數收斂較快,準確率也可以。 3、啟用函式
python資料分析6:雙色球 使用線性迴歸演算法預測下期中獎結果
本次將進行下期雙色球號碼的預測,想想有些小激動啊。 程式碼中使用了線性迴歸演算法,這個場景使用這個演算法,預測效果一般,各位可以考慮使用其他演算法嘗試結果。 發現之前有很多程式碼都是重複的工作,為了讓程式碼看的更優雅,定義了函式,去呼叫,頓時高大上了 #!/usr/bi
機器學習---預測數值型資料:迴歸3(使用LAR演算法進行求解lasso演算法)
上一節我們詳細的介紹了嶺迴歸演算法和lasso演算法的來歷和使用,不過還沒有詳解lasso的計算方式,本節將進行全面的詳解,在詳解之前,希望大家都理解了嶺迴歸和lasso 的來歷,他們的區別以及使用的範圍。下面將開始詳解求解過程: 一樣的,講解之前先把本節需要的基礎知識和大
【自然語言處理入門】03:利用線性迴歸對資料集進行分析預測(下)
上一篇中我們簡單的介紹了利用線性迴歸分析並預測波士頓房價資料集,那麼在這一篇中,將使用相同的模型來對紅酒資料集進行分析。 1 基本要求 利用線性迴歸,對紅酒資料集進行分析。資料集下載地址。 2 完整程式碼 #-*- codin
常見的離散型和連續型隨機變數的概率分佈
目錄 1 基本概念 4 參考文獻 1 基本概念 在之前的博文中,已經明白了概率分佈函式和概率密度函式。下面來講解一下常見的離散型和連續型隨機變數概率分佈。 在此之前,介紹幾個基本概念: 均值(期望值exp
隨機變數概率分佈函式彙總-離散型分佈+連續型分佈
2018.08.18-更新 概率分佈用以表達隨機變數取值的概率規律,根據隨機變數所屬型別的不同,概率分佈取不同的表現形式 離散型分佈:二項分佈、多項分佈、伯努利分佈、泊松分佈 連續型分佈:均勻分佈、正態分佈、指數分佈、伽瑪分佈、偏態分佈、貝塔分佈、威布林分佈、卡方分佈、
python迴歸分析相關程式碼-散點圖,迴歸,預測
from sklearn.linear_model import LinearRegression import matplotlib.pyplot as plt from sklearn import metrics import numpy as np #1 #
【自然語言處理入門】03:利用線性迴歸對資料集進行分析預測(上)
本篇筆記是《從自然語言處理到機器學習入門》課程第三次作業的上篇,主要是復現了老大課上講的利用線性迴歸對波士頓房價進行預測的實驗。在下篇中,將利用該模型對紅酒資料集進行線性迴歸分析。 1 基本要求 利用提供的波士頓房價資料,對其進行分析。資
#使用SAS進行變數篩選、模型診斷、多元線性迴歸分析 #
轉載, 太經典了,學習了 第一節 多元線性迴歸分析的概述 迴歸分析中所涉及的變數常分為自變數與因變數。當因變數是非時間的連續性變數(自變數可包括連續性的和離散性的)時,欲研究變數之間的依存關係,多元線性迴歸分析是一個有力的研究工具。 多元迴歸
預測數值型資料:迴歸(二)
上次我們留了個兩個問題沒有仔細說明,一個是區域性加權線性迴歸,另一個是嶺迴歸。今天依次對這兩種演算法進行說明。 一、區域性加權線性迴歸 欠擬合這種問題是僅僅憑藉一條直線來對資料點進行擬合
R語言 | 多元迴歸分析中的對照編碼(contrast coding) | 第一節 dummy variable(啞變數) 和 dummy coding
對於一個自變數是分類變數Categorical Factor的迴歸模型,需要為該Factor的每個Level建立dummy variable。Contrast Matrix把每個Level對映為dummy variable的值。 我們看一個例子來感性認識下dummy v
挖掘建模-分類與預測-迴歸分析-邏輯迴歸
利用Scikit-Learn對以下資料集進行邏輯迴歸分析。首先進行特徵篩選,特徵篩選的方法很多,主要包含在Scikit-Learn的feature-selection庫中,比較簡單的有通過F檢驗(f_regression)來給出各個特徵的F值和p值,從而可以篩選變數(選擇F值
線性迴歸預測數值型資料
所謂線性迴歸(linear regression),就是根據訓練資料找到一組引數w,利用 y = w*s 對新資料進行預測。 通常使用誤差函式為平方誤差: 使該誤差最小化,求導令其導數為零求得係數w,利用矩陣可以表示為: 該過程成為普通最小二乘法(ordinar
量化投資學習筆記18——迴歸分析:變數的選擇、多重共線性及迴歸分析的改進
如果模型包含了所有影響因素,稱為全模型。如果只包含部分影響因素,稱為選模型。 影響:①未選入的引數不全為0時,選模型的迴歸引數為有偏估計。②選模型的預測結果是有偏預測。③選模型的引數估計有較小的方差。④選模型的預測殘差有較小的方差。⑤選模型預測的均方誤差比全模型小。 自變數選擇的準則: ①殘差平方和SSE越小
量化投資學習筆記19——迴歸分析:實操,泰坦尼克號乘客生還機會預測,線性迴歸方法。
用kaggle上的泰坦尼克的資料來實操。 https://www.kaggle.com/c/titanic/overview 在主頁上下載了資料。 任務:使用泰坦尼克號乘客資料建立機器學習模型,來預測乘客在海難中是否生存。 在實際海難中,2224位乘客中有1502位遇難了。似乎有的乘客比其它乘客更有機會獲救。
tlm源碼分析——sqr_if_base類型
函數 idt port pull con driver 調用 fun 實現 基於sqr_if_base類型的uvm_port_base,主要擴展出了三個class; uvm_seq_port的宏,與tlm_ifs的類似,只是定義了new函數
機器學習實戰第8章預測數值型數據:回歸
矩陣 向量 from his sca ima 用戶 targe 不可 1.簡單的線性回歸 假定輸入數據存放在矩陣X中,而回歸系數存放在向量W中,則對於給定的數據X1,預測結果將會是 這裏的向量都默認為列向量 現在的問題是手裏有一些x