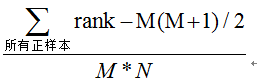ROC與AUC學習
阿新 • • 發佈:2018-11-11
全文轉自:https://www.cnblogs.com/gatherstars/p/6084696.html#commentform
這篇真的講的清楚明白!要多複習!加深記憶!
1.概述
AUC(Area Under roc Curve)是一種用來度量 分類模型好壞的一個標準。這樣的標準其實有很多,例如:大約10年前在machine learning文獻中一統天下的標準:分類精度;在資訊檢索(IR)領域中常用的recall和 precision,等等。其實,度量反應了人們對”好”的分類結果的追求,同一時期的不同的度量反映了人們對什麼是”好”這個最根本問題的不同認識,而不同時期流行的度量則反映了人們認識事物的深度的變化。 近年來,隨著machine learning的相關技術從實驗室走向實際應用,一些實際的問題對度量標準提出了新的需求。特別的,現實中樣本在不同類別上的不均衡分佈(class distribution imbalance problem)。使得accuracy這樣的傳統的度量標準不能恰當的反應分類器的performance。舉個例子:測試樣本中有A類樣本90個,B 類樣本10個。分類器C1把所有的測試樣本都分成了A類,分類器C2把A類的90個樣本分對了70個,B類的10個樣本分對了5個。則C1的分類精度為 90%,C2的分類精度為75%。但是,顯然C2更有用些。另外,在一些分類問題中犯不同的錯誤代價是不同的(cost sensitive learning)。這樣,預設0.5為分類閾值的傳統做法也顯得不恰當了。 為了解決上述問題,人們從醫療分析領域引入了一種新的分類模型 performance2.ROC曲線
2.1ROC的動機
對於0,1兩類分類問題,一些分類器得到的結果往往不是0,1這樣的標籤,如神經網路得到諸如0.5,0.8這樣的分類結果。這時,我們人為取一個閾值,比如0.4,那麼小於0.4的歸為0類,大於等於0.4的歸為1類,可以得到一個分類結果。同樣,這個閾值我們可以取0.1或0.2等等。取不同的閾值,最後得到的分類情況也就不同。如下面這幅圖: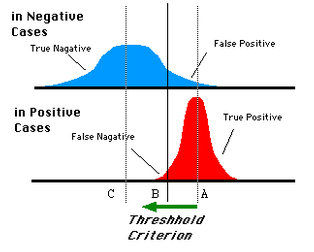
2.2ROC的定義
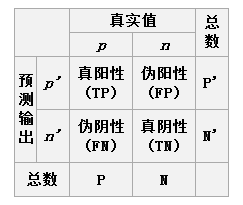
2.3ROC的圖形化表示
我們以FPR為橫軸,TPR為縱軸,得到如下ROC空間: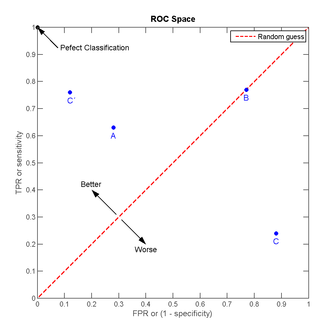
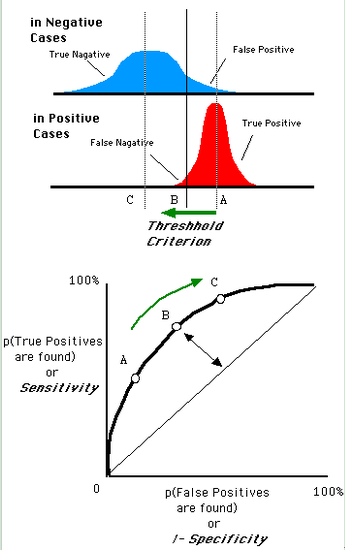
曲線距離左上角越近,證明分類器效果越好。
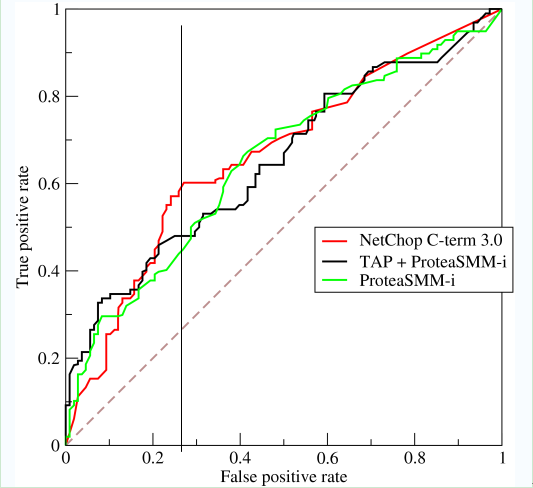 如上,是三條ROC曲線,在0.23處取一條直線。那麼,在同樣的FPR=0.23的情況下,紅色分類器得到更高的TPR。也就表明,ROC越往上,分類器效果越好。我們用一個標量值AUC來量化他。
如上,是三條ROC曲線,在0.23處取一條直線。那麼,在同樣的FPR=0.23的情況下,紅色分類器得到更高的TPR。也就表明,ROC越往上,分類器效果越好。我們用一個標量值AUC來量化他。
3.AUC值
3.1AUC值的定義
AUC值為ROC曲線所覆蓋的區域面積,顯然,AUC越大,分類器分類效果越好。 AUC = 1,是完美分類器,採用這個預測模型時,不管設定什麼閾值都能得出完美預測。絕大多數預測的場合,不存在完美分類器。 0.5 < AUC < 1,優於隨機猜測。這個分類器(模型)妥善設定閾值的話,能有預測價值。 AUC = 0.5,跟隨機猜測一樣(例:丟銅板),模型沒有預測價值。 AUC < 0.5,比隨機猜測還差;但只要總是反預測而行,就優於隨機猜測。3.2AUC值的物理意義
假設分類器的輸出是樣本屬於正類的socre(置信度),則AUC的物理意義為,任取一對(正、負)樣本,正樣本的score大於負樣本的score的概率。3.3AUC值的計算
(1)第一種方法:AUC為ROC曲線下的面積,那我們直接計算面積可得。面積為一個個小的梯形面積之和,計算的精度與閾值的精度有關。 (2)第二種方法:根據AUC的物理意義,我們計算正樣本score大於負樣本的score的概率。取N*M(N為正樣本數,M為負樣本數)個二元組,比較score,最後得到AUC。時間複雜度為O(N*M)。 (3)第三種方法:與第二種方法相似,直接計算正樣本score大於負樣本的score的概率。我們首先把所有樣本按照score排序,依次用rank表示他們,如最大score的樣本,rank=n(n=N+M),其次為n-1。那麼對於正樣本中rank最大的樣本(rank_max),有M-1個其他正樣本比他score小,那麼就有(rank_max-1)-(M-1)個負樣本比他score小。其次為(rank_second-1)-(M-2)。最後我們得到正樣本大於負樣本的概率為: