
最小二乘迴歸,嶺迴歸,Lasso迴歸,彈性網路
普通最小二乘法
理論:

損失函式:

權重計算:
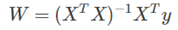
1、對於普通最小二乘的係數估計問題,其依賴於模型各項的相互獨立性。
2、當各項是相關的,且設計矩陣 X的各列近似線性相關,那麼,設計矩陣會趨向於奇異矩陣,這會導致最小二乘估計對於隨機誤差非常敏感,產生很大的方差。
例如,在沒有實驗設計的情況下收集到的資料,這種多重共線性(multicollinearity)的情況可能真的會出現。
使用:
from sklearn import datasets, linear_model
regr = linear_model.LinearRegression()
reg.fit(X_train, y_train)
嶺迴歸
理論:
損失函式:
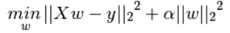
其中阿爾法大於0,它的值越大,收縮量越大,這樣係數對公線性的魯棒性也更強
當X矩陣不存在廣義逆(即奇異性),最小二乘法將不再適用。可以使用嶺迴歸
X矩陣不存在廣義逆(即奇異性)的情況:
1)X本身存線上性相關關係(即多重共線性),即非滿秩矩陣。
當取樣值誤差造成本身線性相關的樣本矩陣仍然可以求出逆陣時,此時的逆陣非常不穩定,所求的解也沒有什麼意義。
2)當變數比樣本多,即p>n時.
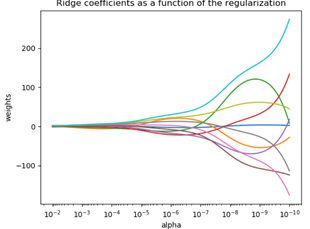
嶺跡圖:
嶺跡圖作用:
1)觀察λ較佳取值;
2)觀察變數是否有多重共線性;
在λ很小時,W很大,且不穩定,當λ增大到一定程度時,W係數迅速縮小,趨於穩定。
λ的選擇:一般通過觀察,選取喇叭口附近的值
嶺引數的一般選擇原則
選擇λ值,使到
1)各回歸係數的嶺估計基本穩定;
2)用最小二乘估計時符號不合理的迴歸係數,其嶺估計的符號變得合理;
3)迴歸係數沒有不合乎實際意義的值;
4)殘差平方和增大不太多。 一般λ越大,係數β會出現穩定的假象,但是殘差平方和也會更大
嶺迴歸選擇變數的原則(僅供參考)
1)在嶺迴歸中設計矩陣X已經中心化和標準化了,這樣可以直接比較標準化嶺迴歸係數的大小。可以剔除掉標準化嶺迴歸係數比較穩定且值很小的自變數。
2)隨著λ的增加,迴歸係數不穩定,震動趨於零的自變數也可以剔除。
3)如果依照上述去掉變數的原則,有若干個迴歸係數不穩定,究竟去掉幾個,去掉哪幾個,這無一般原則可循,這需根據去掉某個變數後重新進行嶺迴歸分析的效果來確定。
使用:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model
# X is the 10x10 Hilbert matrix
X = 1. / (np.arange(1, 11) + np.arange(0, 10)[:, np.newaxis])
y = np.ones(10)
# #############################################################################
# Compute paths
n_alphas = 200
alphas = np.logspace(-10, -2, n_alphas)
coefs = []
for a in alphas:
ridge = linear_model.Ridge(alpha=a, fit_intercept=False)
ridge.fit(X, y)
coefs.append(ridge.coef_)
# #############################################################################
# Display results
ax = plt.gca()
ax.plot(alphas, coefs)
Lasso迴歸
理論:
維數災難:
何謂高維資料?高維資料指資料的維度很高,甚至遠大於樣本量的個數。高維資料的明顯的表現是:在空間中資料是非常稀疏的,與空間的維數相比樣本量總是顯得非常少。
在分析高維資料過程中碰到最大的問題就是維數的膨脹,也就是通常所說的“維數災難”問題。研究表明,隨著維數的增長,分析所需的空間樣本數會呈指數增長。
如下所示,當資料空間維度由1增加為3,最明顯的變化是其所需樣本增加;換言之,當樣本量確定時,樣本密度將會降低,從而樣本呈稀疏狀態。假設樣本量n=12,單個維度寬度為3,那在一維空間下,樣本密度為12/3=4,在二維空間下,樣本分佈空間大小為3*3,則樣本密度為12/9=1.33,在三維空間下樣本密度為12/27=0.44。
設想一下,當資料空間為更高維時,X=[x1x1,x2x2,….,xnxn]會怎麼樣?
1、需要更多的樣本,樣本隨著資料維度的增加呈指數型增長;
2、資料變得更稀疏,導致資料災難;
3、在高維資料空間,預測將變得不再容易;
4、導致模型過擬合。
資料降維:
對於高維資料,維數災難所帶來的過擬合問題,其解決思路是:1)增加樣本量;2)減少樣本特徵,而對於現實情況,會存在所能獲取到的樣本資料量有限的情況,甚至遠小於資料維度,即:d>>n。如證券市場交易資料、多媒體圖形影象視訊資料、航天航空採集資料、生物特徵資料等。
主成分分析作為一種資料降維方法,其出發點是通過整合原本的單一變數來得到一組新的綜合變數,綜合變數所代表的意義豐富且變數間互不相關,綜合變數包含了原變數大部分的資訊,這些綜合變數稱為主成分。主成分分析是在保留所有原變數的基礎上,通過原變數的線性組合得到主成分,選取少數主成分就可保留原變數的絕大部分資訊,這樣就可用這幾個主成分來代替原變數,從而達到降維的目的。
但是,主成分分析法只適用於資料空間維度小於樣本量的情況,當資料空間維度很高時,將不再適用。
Lasso是另一種資料降維方法,該方法不僅適用於線性情況,也適用於非線性情況。Lasso是基於懲罰方法對樣本資料進行變數選擇,通過對原本的係數進行壓縮,將原本很小的係數直接壓縮至0,從而將這部分系數所對應的變數視為非顯著性變數,將不顯著的變數直接捨棄。
目標函式:
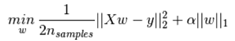
1、Lasso 是估計稀疏係數的線性模型。
2、它在一些情況下是有用的,因為它傾向於使用具有較少引數值的情況,有效地減少給定解決方案所依賴變數的數量。 因此,Lasso 及其變體是壓縮感知領域的基礎。 在一定條件下,它可以恢復一組非零權重的精確集
彈性網路
1、彈性網路 是一種使用 L1, L2 範數作為先驗正則項訓練的線性迴歸模型。
2、這種組合允許學習到一個只有少量引數是非零稀疏的模型,就像 Lasso 一樣,但是它仍然保持 一些像 Ridge 的正則性質。我們可利用 l1_ratio 引數控制 L1 和 L2 的凸組合。
3、彈性網路在很多特徵互相聯絡的情況下是非常有用的。Lasso 很可能只隨機考慮這些特徵中的一個,而彈性網路更傾向於選擇兩個。
4、在實踐中,Lasso 和 Ridge 之間權衡的一個優勢是它允許在迴圈過程(Under rotate)中繼承 Ridge 的穩定性。
損失函式:

使用:
from sklearn.linear_model import ElasticNet
enet = ElasticNet(alpha=0.2, l1_ratio=0.7) #alpha=α l1_ratio=ρ