
基於KD-Tree的最近鄰搜尋
目標:查詢目標點附近的10個最近鄰鄰居。
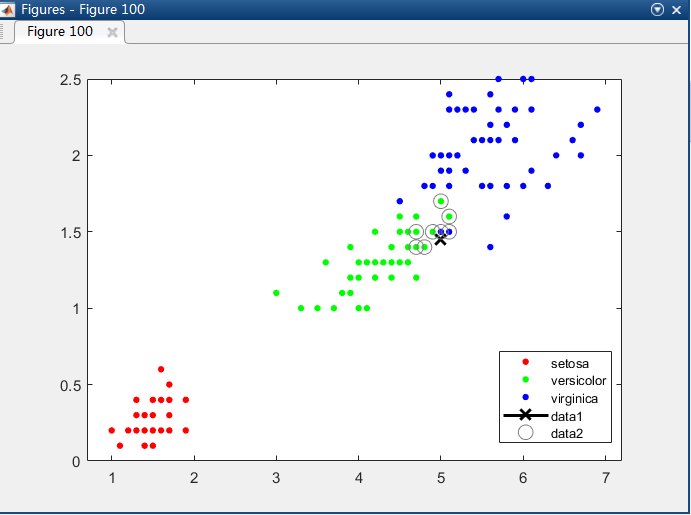
load fisheriris x = meas(:,3:4); figure(100); g1=gscatter(x(:,1),x(:,2),species); %species分類中是有三個分類:setosa,versicolor,virginica legend('Location','best') newpoint = [5 1.45]; line(newpoint(1),newpoint(2),'marker','x','color','k',... 'markersize',10,'linewidth',2) Mdl= KDTreeSearcher(x) ; [n,d] = knnsearch(Mdl,newpoint,'k',10); %k代表個數,即搜尋給定點附近的幾個最近鄰點 line(x(n,1),x(n,2),'color',[.5 .5 .5],'marker','o',... 'linestyle','none','markersize',10) disp(x(n,:))
相關推薦
基於KD-Tree的最近鄰搜尋
目標:查詢目標點附近的10個最近鄰鄰居。 load fisheriris x = meas(:,3:4); figure(100); g1=gscatter(x(:,1),x(:,2),species); %species分類中是有三個分類:setosa,versicolor,virgini
《推薦系統》003 基於物品的最近鄰推薦
在基於使用者的最近鄰推薦演算法中,使用者資訊的大批量計算是很難達到實時性要求的。而基於物品的最近鄰推薦演算法通常線上下進行預處理,所以能夠實現實時計算。 預處理的時候會建立物品相似度矩陣,描述物品之間兩兩相似度關係。近鄰的數量受使用者已經評論物品數量的限制。 基於物品的最近
《推薦系統》002 基於使用者的最近鄰推薦
協同過濾: 利用已經存在的使用者群體,對當前的使用者的喜好進行推測。 基於使用者的最近鄰推薦: 先找出與當前使用者喜好相似的使用者資訊,然後根據他們的評價體系對當前使用者對未知物品的評價等級。 前提假設: 1
Java推薦系統-基於使用者的最近鄰協同過濾演算法
基於使用者的最近鄰演算法(User-Based Neighbor Algorithms),是一種非概率性的協同過濾演算法,也是推薦系統中最最古老,最著名的演算法,我們稱那些興趣相似的使用者為鄰居,如果使用者n相似於使用者u,我們就說n是u的一個鄰居。起初演算法,對於未知目標的預測是根據該使用者的
演算法一 knn 中的 最近鄰搜尋
By RaySaint 2011/10/12 本文的主要目的是講一下如何建立k-d tree對目標物體的特徵點集合進行資料組織和使用k-d tree最近鄰搜尋來加速特徵點匹配。上面已經講了特徵點匹配的問題其實上是一個最近鄰(K近鄰)搜尋的問題。所以為了更好的引出k-d tree,先講一講最近鄰搜尋。 最
KD樹詳解及KD樹最近鄰演算法
2.1、什麼是KD樹 Kd-樹是K-dimension tree的縮寫,是對資料點在k維空間(如二維(x,y),三維(x,y,z),k維(x1,y,z..))中劃分的一種資料結構,主要應用於多維空間關鍵資料的搜尋(如:範圍搜尋和最近鄰搜尋)。本質上說,Kd-樹就是一種平衡二叉樹。
基於TensorFlow的最近鄰(NN)分類器——以MNIST識別為例
一、最近鄰分類理論 二、TF在CPU上實現NN分類 具體程式碼如下: import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data
學習OpenCV——Surf(特徵點篇)&flann快速最近鄰搜尋演算法
Surf(Speed Up Robust Feature) Surf演算法的原理 1.構建Hessian矩陣構造
kd-tree : k近鄰查詢和範圍查詢
想象一下我們有如下兩個任務: 我現在想騎一輛小黃車,我想查詢離我最近的k輛小黃車. 找到百度地圖中顯示在螢幕上區域中的所有酒店 這兩個任務均可以用kd-tree來解決 kd-tree 主要兩個用途: 查詢離某個點的最近的k 個鄰居, 搜尋某個區
KNN(三)--KD樹詳解及KD樹最近鄰演算法
之前blog內曾經介紹過SIFT特徵匹配演算法,特徵點匹配和資料庫查、影象檢索本質上是同一個問題,都可以歸結為一個通過距離函式在高維向量之間進行相似性檢索的問題,如何快速而準確地找到查詢點的近鄰,不少人提出了很多高維空間索引結構和近似查詢的演算法。 一般說來,索引結構中相似性查詢有兩種基本的方式:
最近鄰和K近鄰及其優化演算法LSH(區域性敏感雜湊,Locality Sensitive Hashing) Kd-Tree
引言 在處理大量高維資料時,如何快速地找到最相似的資料是一個比較難的問題。如果是低維的小量資料,線性查詢(Linear Search)就可以解決,但面對海量的高維資料集如果採用線性查詢將會非常耗時。因此,為了解決該問題通常採用些優化演算法。稱之為近似最近鄰查詢
最近鄰查詢演算法kd-tree
海量資料最近鄰查詢的kd-tree簡介利用Octree,為封閉的3D空間建立一個資料結構來管理空間中的每個元素。如此我們可以在 O(log N) 的時間內對這3D空間進行搜尋。3D空間可以用Octree,2D空間可以用Quadtree(四元樹,概念跟Octree一樣)。那麼4
Kd-Tree演算法原理 最近鄰查詢
本文介紹一種用於高維空間中的快速最近鄰和近似最近鄰查詢技術——Kd-Tree(Kd樹)。Kd-Tree,即K-dimensional tree,是一種高維索引樹形資料結構,常用於在大規模的高維資料空間進行最近鄰查詢(Nearest Neighbor)和近似最近鄰查詢(Ap
實現基於最近鄰內插和雙線性內插的圖像縮放
spa 實現 多圖像 掌握 機器 圖像處理 必須掌握 res c++ 平時我們寫圖像處理的代碼時,如果需要縮放圖片,我們都是直接調用圖像庫的resize函數來完成圖像的縮放。作為一個機器視覺或者圖像處理算法的工作者,圖像縮放代碼的實現應該是必須掌握的。在眾多圖像縮放算法中,
kd-tree找最鄰近點 Python實現
kd-tree找最鄰近點 Python實現 基本概念 kd-tree是KNN演算法的一種實現。演算法的基本思想是用多維空間中的例項點,將空間劃分為多塊,成二叉樹形結構。劃分超矩形上的例項點是樹的非葉子節點,而每個超矩形內部的例項點是葉子結點。 超矩形劃分方法 有資料集data
用TensorFlow基於最近鄰域法實現影象識別
1、匯入程式設計庫 import random import numpy as np import tensorflow as tf import matplotlib.pyplot as plt from PIL import Image from tens
[LeetCode] Lowest Common Ancestor of a Binary Search Tree 二叉搜尋樹的最小共同父節點
Given a binary search tree (BST), find the lowest common ancestor (LCA) of two given nodes in the BST. According to the definition of LCA on Wikipedia:
基於使用者最近鄰模型的協同過濾演算法的Python程式碼實現
#------------------------------------------------------------------------------- # Name: PearsonUserNeighCF # Purpose: Personalized Recommendati
最近鄰法和k-近鄰法 KD樹
最近鄰法和k-近鄰法 下面圖片中只有三種豆,有三個豆是未知的種類,如何判定他們的種類? 提供一種思路,即:未知的豆離哪種豆最近就認為未知豆和該豆是同一種類。由此,我們引出最近鄰演算法的定義:為了判定未知樣本的類別,以全部訓練樣本作為代表點,
knn之構造kd樹和最近鄰求取c++實現
這份程式碼測試樣例為 6 7 2 2 3 5 4 4 7 9 6 8 1 8 2 這樣,通過中位數來選取根節點(這樣的方法其實在一定程度上是有很大問題的,因為根節點的選取方法不同,會導致整棵樹的結構不同,這裡由於資料的關係,不能構成完全二叉樹,所以在對於特殊的樣例來說