
pytorch-RNN進行迴歸曲線預測
阿新 • • 發佈:2018-11-30
任務
通過輸入的sin曲線與預測出對應的cos曲線
#初始載入包 和定義引數
import torch
from torch import nn
import numpy as np
import matplotlib.pyplot as plt
torch.manual_seed(1) #為了可復現
#超引數設定
TIME_SETP=10
INPUT_SIZE=1
LR=0.02
DOWNLoad_MNIST=True定義RNN網路結構
from torch.autograd import Variable class RNN(nn.Module): def __init__(self): #在這個函式中,兩步走,先init,再逐步定義層結構 super(RNN,self).__init__() self.rnn=nn.RNN( #定義32隱層的rnn結構 input_size=1, hidden_size=32, #隱層有32個記憶體 num_layers=1, #隱層層數是1 batch_first=True ) self.out=nn.Linear(32,1) #32個記憶體對應一個輸出 def forward(self,x,h_state): #前向過程,獲取 rnn網路輸出r_put(注意這裡r_out並不是最後輸出,最後要經過全連線層) 和 記憶體情況h_state r_out,h_state=self.rnn(x,h_state) outs=[]#獲取所有時間點下得到的預測值 for time_step in range(r_out.size(1)): #將記憶rnn層的輸出傳到全連線層來得到最終輸出。 這樣每個輸入對應一個輸出,所以會有長度為10的輸出 outs.append(self.out(r_out[:,time_step,:])) return torch.stack(outs,dim=1),h_state #將10個數 通過stack方式壓縮在一起 rnn=RNN() print('RNN的網路體系結構為:',rnn)
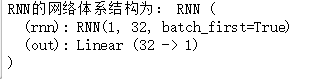
建立資料集及網路訓練
以sin曲線為特徵,以cos曲線為標籤進行網路的訓練
#定義優化器和 損失函式 optimizer=torch.optim.Adam(rnn.parameters(),lr=LR) loss_fun=nn.MSELoss() h_state=None #記錄的隱藏層狀態,記住這就是記憶體,初始時候為空,之後每次後面的都會使用到前面的記憶,自動生成全0的 #這樣加入記憶資訊後,每次都會在之前的記憶矩陣基礎上再進行新的訓練,初始是全0的形式。 #啟動訓練,這裡假定訓練的批次為100次 plt.ion() #可以設定持續不斷的繪圖,但是在這裡看還是間斷的,這是jupyter的問題 for step in range(100): #我們以一個π為一個時間步 定義資料, start,end=step*np.pi,(step+1)*np.pi steps=np.linspace(start,end,10,dtype=np.float32) #注意這裡的10並不是間隔為10,而是將數按範圍分成10等分了 x_np=np.sin(steps) y_np=np.cos(steps) #將numpy型別轉成torch型別 *****當需要 求梯度時,一個 op 的兩個輸入都必須是要 Variable,輸入的一定要variable包下 x=Variable(torch.from_numpy(x_np[np.newaxis,:,np.newaxis]))#增加兩個維度,是三維的資料。 y=Variable(torch.from_numpy(y_np[np.newaxis,:,np.newaxis])) #將每個時間步上的10個值 輸入到rnn獲得結果 這裡rnn會自動執行forward前向過程. 這裡輸入時10個,輸出也是10個,傳遞的是一個長度為32的記憶體 predition,h_state=rnn(x,h_state) #更新新的中間狀態 h_state=Variable(h_state.data) #擦,這點一定要從新包裝 loss=loss_fun(predition,y) #print('loss:',loss) optimizer.zero_grad() loss.backward() optimizer.step() # plotting 畫圖,這裡先平展了 flatten,這樣就是得到一個數組,更加直接 plt.plot(steps, y_np.flatten(), 'r-') plt.plot(steps, predition.data.numpy().flatten(), 'b-') #plt.draw(); plt.pause(0.05) plt.ioff() #關閉互動模式 plt.show()

