用線性迴歸模型預測房價
阿新 • • 發佈:2018-12-22
本文使用sklearn 中自帶的波士頓房價資料集來訓練模型,然後利用模型來預測房價。這份收據中共收集了13個特徵。
1.輸入特徵
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_boston
boston = load_boston()
X = boston.data
y = boston.target
X.shape
輸出為:“(506,13)”共有506個樣本 13個特徵。
print(X[0]) 輸出結果為: array([ 6.32000000e-03, 1.80000000e+01, 2.31000000e+00, 0.00000000e+00, 5.38000000e-01, 6.57500000e+00, 6.52000000e+01, 4.09000000e+00, 1.00000000e+00, 2.96000000e+02, 1.53000000e+01, 3.96900000e+02, 4.98000000e+00])
可以通過boston.feature_names 來檢視這些特徵的標籤
array(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD',
'TAX', 'PTRATIO', 'B', 'LSTAT'],
dtype='|S7')
2.模型訓練
LinearRegression 類實現了線性迴歸演算法。在訓練之前先把資料集分為兩份。
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=3)
訓練模型並測試模型準確性
import time from sklearn.linear_model import LinearRegression model = LinearRegression() start = time.clock() model.fit(X_train, y_train) train_score = model.score(X_train, y_train) cv_score = model.score(X_test, y_test) print('elaspe: {0:.6f}; train_score: {1:0.6f}; cv_score: {2:.6f}'.format(time.clock()-start, train_score, cv_score))
統計了模型的訓練時間,統計模型對訓練樣本的準確性得分(即對訓練樣本的擬合好壞程度)train_score,還統計了模型對測試樣本的得分 cv_score
執行結果如下:
elaspe: 0.002447; train_score: 0.723941; cv_score: 0.794958
從結果可以看出模型擬合效果一般。
3.模型優化
模型優化的方式
1.觀察特徵的變化範圍從級別到,先將資料進行歸一化的處理,可以加快演算法的收斂速度。
2.增加多項式特徵
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
def polynomial_model(degree=1):
polynomial_features = PolynomialFeatures(degree=degree,
include_bias=False)
linear_regression = LinearRegression(normalize=True)
pipeline = Pipeline([("polynomial_features", polynomial_features),
("linear_regression", linear_regression)])
return pipeline
接著我們使用二階多項式來你和資料:
model = polynomial_model(degree=2)
start = time.clock()
model.fit(X_train, y_train)
train_score = model.score(X_train, y_train)
cv_score = model.score(X_test, y_test)
print('elaspe: {0:.6f}; train_score: {1:0.6f}; cv_score: {2:.6f}'.format(time.clock()-start, train_score, cv_score))
輸出結果是:
elaspe: 0.016412; train_score: 0.930547; cv_score: 0.860465
訓練樣本分數和測試樣本分數都提高了,模型得到了優化。
把多項式特徵改為三階檢視效果。
執行結果為 :
elaspe: 0.133220; train_score: 1.000000; cv_score: -105.517016
針對訓練樣本的分數達到了1 ,而對測試樣本的分數卻是負數,產生了過擬合。
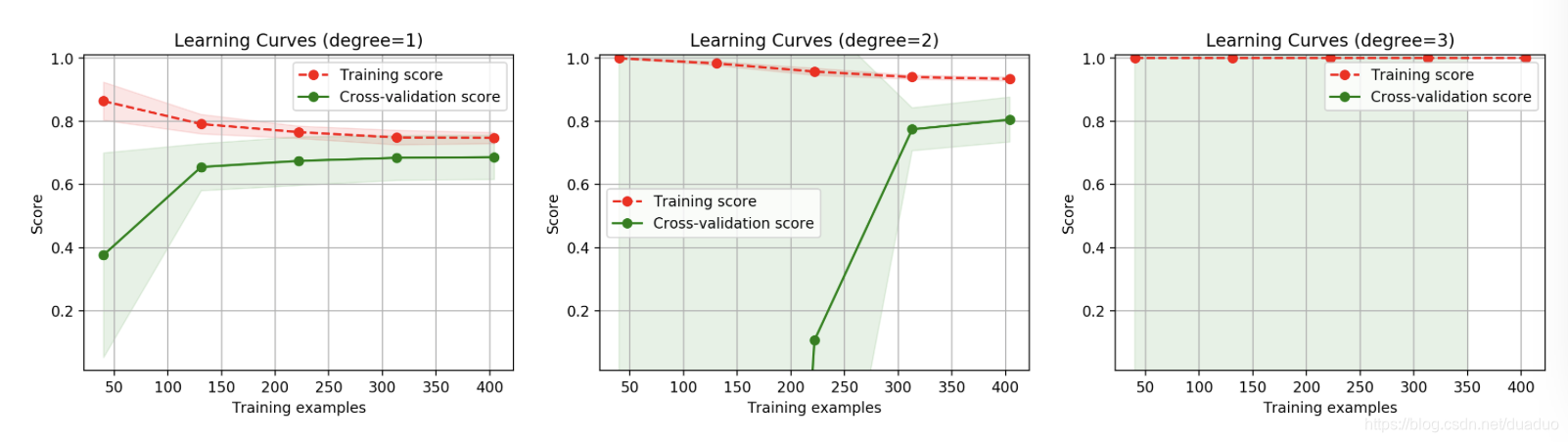
4.學習曲線
通過畫出學習曲線,來對模型的狀態及優化的方向直觀的觀察。
from common.utils import plot_learning_curve
from sklearn.model_selection import ShuffleSplit
cv = ShuffleSplit(n_splits=10, test_size=0.2, random_state=0)
plt.figure(figsize=(18, 4), dpi=200)
title = 'Learning Curves (degree={0})'
degrees = [1, 2, 3]
start = time.clock()
plt.figure(figsize=(18, 4), dpi=200)
for i in range(len(degrees)):
plt.subplot(1, 3, i + 1)
plot_learning_curve(plt, polynomial_model(degrees[i]), title.format(degrees[i]), X, y, ylim=(0.01, 1.01), cv=cv)
print('elaspe: {0:.6f}'.format(time.clock()-start))