
Noise-aware training噪聲感知訓練
Noise-aware training噪聲感知訓練
看論文的時候看到這種提高魯棒性的方法,查了一下資料,比較有限,在這裡做個記錄。
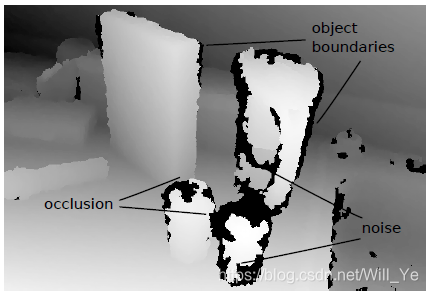
Noise-aware training噪聲感知訓練著眼於如何識別以及減少工作時的噪聲,這裡說的工作時也就是如處理影象深度資訊的時候一樣,在一些物體的邊、角位置會有很多黑色的塊狀遮擋,這些都是噪點,如下圖所示,缺失了這部分的深度資訊。這種方法特別適合用在建築或工業環境中,大部分的室內環境都挺適合的。
下面說一下大致的方法:
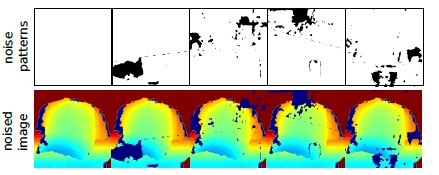
通過對噪音的深入觀察,資料通常顯示一種特徵模式並出現在物體邊界或物體表面。具體來講,我們從一個經典的噪聲模式資料集中取樣 這些噪聲模式發生在通過Kinect記錄的典型室內場景。為了取樣噪聲模式,我們使用RGB-D SLAM資料集,首先,我們提取33000個大小為256×256的隨機噪聲,這些噪聲來自不同位置的不同的序列(sequences)並把他們分成五組,根據缺失的深度資訊讀取它們包含的數量。這些噪聲斑(noise patches)是二維二進位制掩碼形式,我們從兩個不同的組中隨機抽取一對噪聲斑,對其進行隨機新增或減少,並選擇性地顛倒以產生最終的噪聲遮掩模式(noise mask pattern)。我們重複這一過程直到我們收集到K=50,000個噪聲模式。
產生的噪聲模式示例以及其在訓練示例中的應用如下圖所示
利用人為製造的噪聲模式對深度網路進行訓練,然後將等式
中的目標最小化,其中每個深度樣本
被隨機替換為一個概率為50%的有噪變體(a noised variant)。以下是它的表示形式:
上式中,
指的是 哈馬達乘積Hadamard product,
指的是 伯努利分佈Bernoulli
distribution and
指的是 離散均勻分佈discrete uniform distribution.
這個哈馬達乘積其實就是兩個m×n的矩陣,對應的元素相乘,重新組成一個m×n的矩陣。
伯努利分佈就是0-1分佈,按概率p來決定取值是1還是0
離散均勻分佈就是隨機變數有n個,它們的發生概率相等且等於
具體的應用例子可以看一下這篇論文: Multimodal Deep Learning for Robust RGB-D Object Recognition