
《三》深入理解Pod對象
- 最小部署單元
- 一組容器的集合
- 一個Pod中的容器共享網絡命名空間
- Pod是短暫的
Infrastructure Container:基礎容器
? 維護整個Pod網絡空間
InitContainers:初始化容器
? 先於業務容器開始執行
Containers:業務容器
? 並行啟動
鏡像拉取策略(imagePullPolicy)
- IfNotPresent:默認值,鏡像在宿主機上不存在時才拉取
- Always:每次創建 Pod 都會重新拉取一次鏡像
- Never: Pod 永遠不會主動拉取這個鏡像\
apiVersion: v1 kind: Pod metadata: name: foo namespace: awesomeapps spec: containers: - name: foo image: janedoe/awesomeapp:v1 imagePullPolicy: IfNotPresent
資源限制
默認情況下pod運行沒有任何CPU和內存的限制。這意味著系統中的pod可以盡可能多的消耗CPU和內存在pod執行的節點。
基於多種原因用戶可能希望對系統中的單個pod的資源使用量進行限制。
requests:容器運行是,最低資源需求,也就是說最少需要多少資源容器才能正常運行
limits:總的資源的限制,也就是說一個pod裏的容器最多使用多少資源
說明:
1、以下有2個容器(db、wp)
2、cpu:‘250m’ :表示使用了1核的百分之25;500m 就是使用1核的50%
3、cpu: 0.1 :表示0.1=100m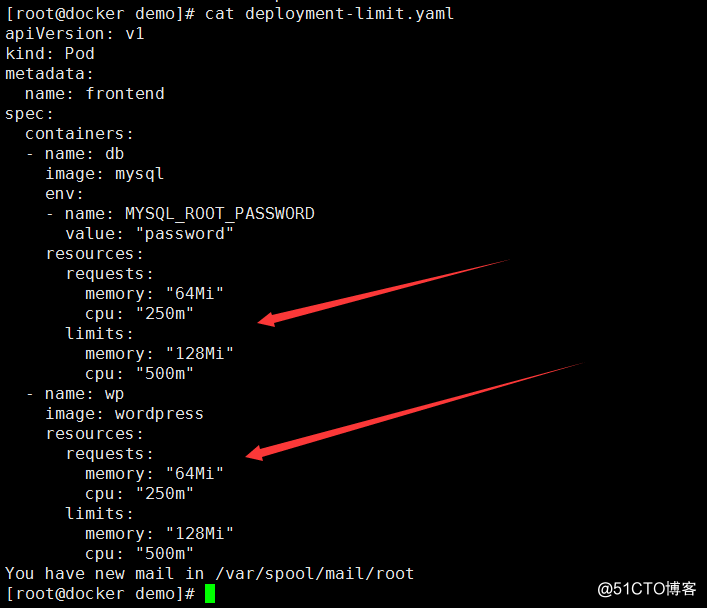
查看限制的屬性:
查出分配的節點的IP
[root@docker demo]# kubectl describe pods frontend
查看限制的屬性:
kubectl describe nodes 192.168.1.23
總結:
1、設置最大的limit 的配置
2、設置1核的cpu就是 cpu:1;cpu最大限制2核
重啟策略(restartPolicy)
- Always:當容器終止退出後,總是重啟容器,默認策略。比如 web服務器,持久性的服務
- OnFailure:當容器異常退出(退出狀態碼非0)時,才重啟容器。
- Never::當容器異常終止退出,從不重啟容器。

驗證: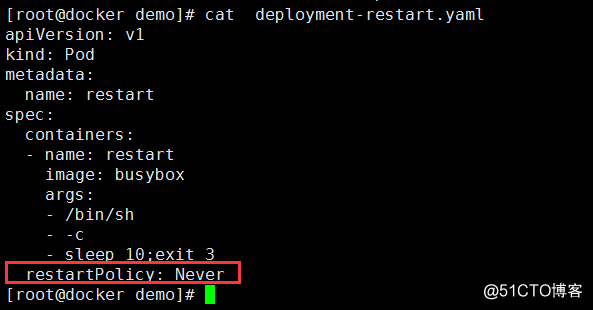
查看:
健康檢查(Probe)
參考文檔:https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-probes/
在實際生產環境中,想要使得開發的應用程序完全沒有bug,在任何時候都運行正常,幾乎 是不可能的任務。因此,我們需要一套管理系統,來對用戶的應用程序執行周期性的健康檢查和修復操作。這套管理系統必須運行在應用程序之外,這一點非常重要一一如果它是應用程序的一部分,極有可能會和應用程序一起崩潰。因此,在Kubernetes中,系統和應用程序的健康檢查是由Kubelet來完成的。1、進程級健康檢查
最簡單的健康檢查是進程級的健康檢查,即檢驗容器進程是否存活。這類健康檢查的監控粒 度是在Kubernetes集群中運行的單一容器。Kubelet會定期通過Docker Daemon獲取所有Docker進程的運行情況,如果發現某個Docker容器未正常運行,則重新啟動該容器進程。目前,進程級的健康檢查都是默認啟用的。
2.業務級健康檢查
在很多實際場景下,僅僅使用進程級健康檢查還遠遠不夠。有時,從Docker的角度來看,容器進程依舊在運行;但是如果從應用程序的角度來看,代碼處於死鎖狀態,即容器永遠都無法正常響應用戶的業務
為了解決以上問題,Kubernetes引人了一個在容器內執行的活性探針(liveness probe)的概念,以支持用戶自己實現應用業務級的健康檢查。這些檢查項由Kubelet代為執行,以確保用戶的應用程序正確運轉,至於什麽樣的狀態才算“正確”,則由用戶自己定義。Kubernetes支持3種類型的應用健康檢查動作,分別為HTTP Get、Container Exec和TCP Socket。個人感覺exec的方式還是最通用的,因為不是每個服務都有http服務,但每個服務都可以在自己內部定義健康檢查的job,定期執行,然後將檢查結果保存到一個特定的文件中,外部探針就不斷的查看這個健康文件就OK了。Probe有以下兩種類型
livenessProbe
如果檢查失敗,將殺死容器,根據Pod的restartPolicy來操作。
readinessProbe
如果檢查失敗,Kubernetes會把Pod從service endpoints中剔除。
Probe支持以下三種檢查方
httpGet
發送HTTP請求,返回200-400範圍狀態碼為成功,比如200成功,400不成功。
exec
執行Shell命令返回狀態碼是0為成功。
tcpSocket
發起TCP Socket建立成功。
initialDelaySeconds
initialDelaySeconds: 5
第一次使用probe時,需要等待5秒
periodSeconds
periodSeconds: 5
每隔5秒執行一個活性探針
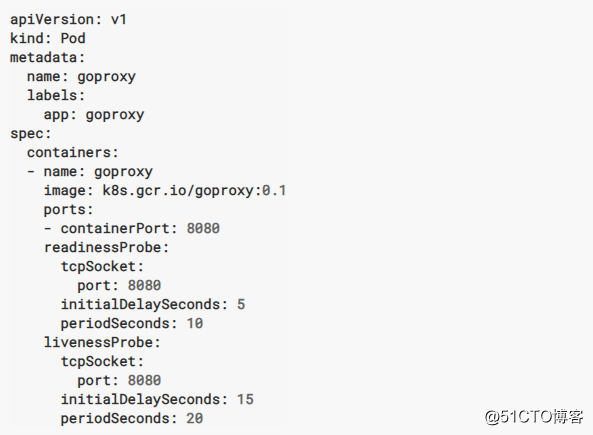
2.1 Container Exec
當/tmp/healthy 這個被刪除了,再次 cat /tmp/healthy 不存在,狀態碼非0,就執行livenessProbe 這個規則
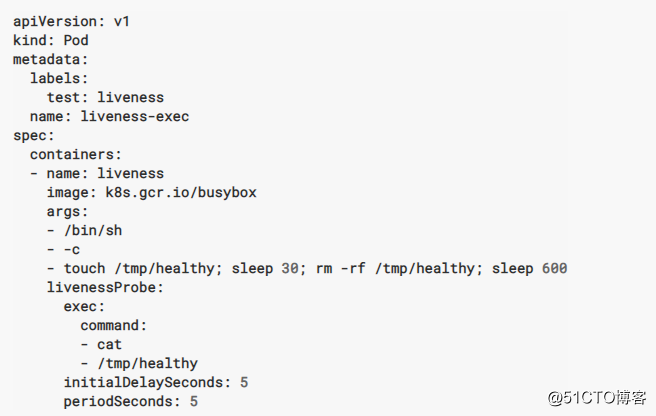
2.2 Container HTTP
說明:大於或等於200且小於400的任何代碼表示成功。任何其他代碼都指示失敗。
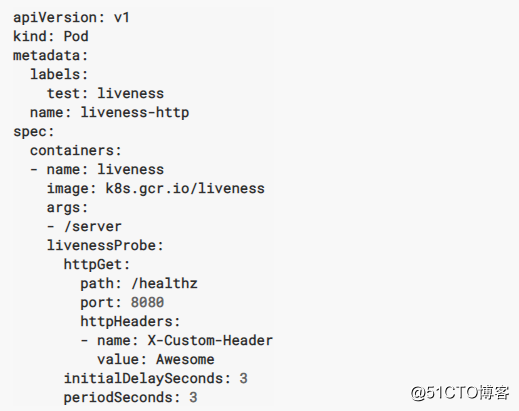
2.3 Container TCP
通過此配置,kubelet將嘗試打開指定端口上的容器的套接字。如果可以建立連接,則認為容器是健康的,如果不能,則認為它是失敗的。
調度約束
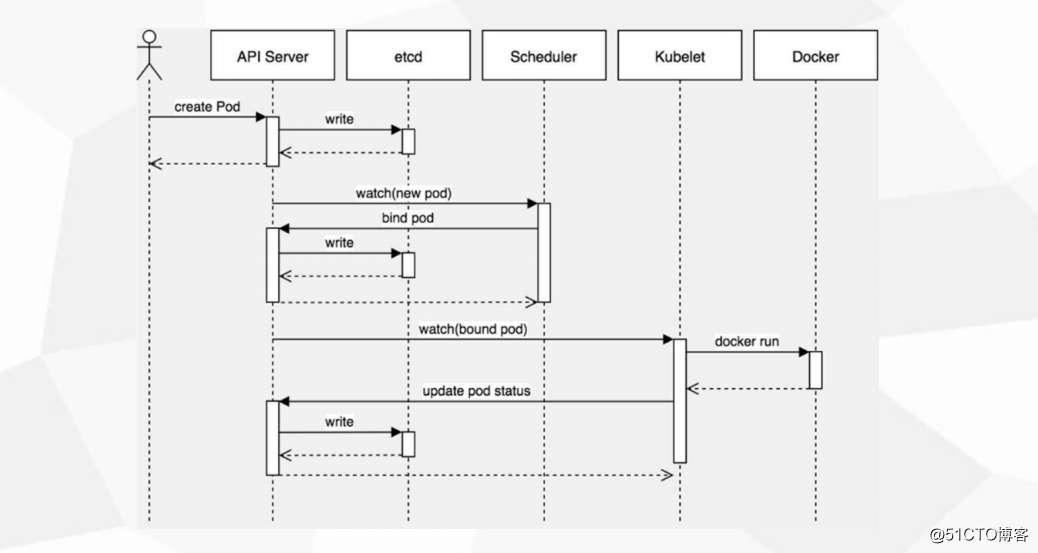
說明
用戶創建一個pod,apiServer收到請求後,會將這個狀態(pod屬性)寫入到etcd中,apiServer通過watch 將新的pod 通知給Scheduler(調度器),Scheduler根據自身的調度算法將pod分配到哪個node上,這些的配置信息會存在etcd中,node上的kubelet 通過watch 綁定pod,並啟動docker,再更新pod狀態(運行,還是停止)etcd中,所以kubelet 展示給用戶
apiServer:相當於管家
etcd:相當於賬本
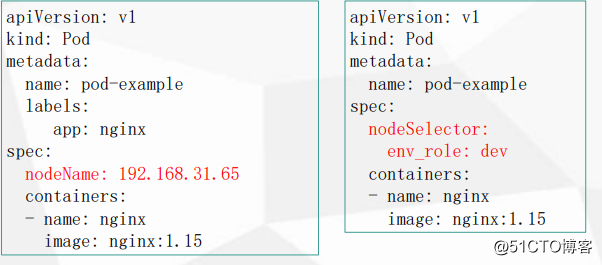
nodeName用於將Pod調度到指定的Node名稱上
nodeSelector用於將Pod調度到匹配Label的Node上
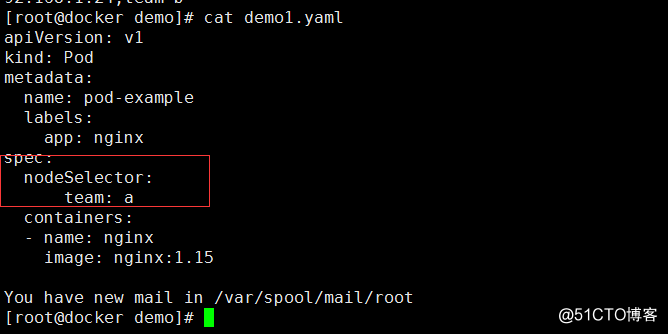
新建label標簽
kubectl label nodes 192.168.1.23 team=a
kubectl label nodes 192.168.1.24 team=b
查看:
kubectl get nodes --show-labels

通過 kubectl describe pods pod-example 查看調度器到哪個節點上
故障排查

解決:
查看日誌
kubectl describe TYPE/NAME
kubectl logs
kubectl exec -it POD
總結
1、pod三個分類
2、鏡像拉取策略哪個關鍵字
3、資源限制哪2個字段
4、重啟策略哪3個策略
5、健康檢查哪2個類型 哪3個檢查方法
《三》深入理解Pod對象