
MD5演算法原理介紹與C++實現
MD5演算法原理介紹與C++實現
原始碼傳送門:https://github.com/dick20/Web-Security/tree/master/MD5
一. 演算法原理概述
The MD5 message-digest algorithm is a widely used hash function producing a 128-bit hash value. Although MD5 was initially designed to be used as a cryptographic hash function, it has been found to suffer from extensive vulnerabilities. ——Wikipedia
- MD5 使用 little-endian (小端模式),輸入任意不定長度資訊,以512-bit 進行分組,生成四個32-bit 資料,最後聯合輸出固定128-bit 的資訊摘要。
- MD5 演算法的基本過程為:填充、分塊、緩衝區初始化、迴圈壓縮、得出結果。
MD5的基本流程圖如下
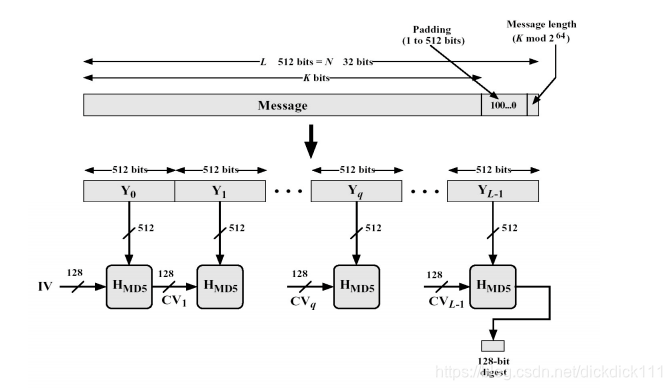
二. 總體結構
1.填充
在長度為 K bits 的原始訊息資料尾部填充長度為 P bits 的標識100…0,1 P 512 (即至少要填充1個bit),使得填充後的訊息位數為:K + P 448 (mod 512).
- 注意到當 K 448 (mod 512) 時,需要 P= 512.
再向上述填充好的訊息尾部附加 K 值的低64位 (即 K mod 264),最後得到一個長度位數為 K + P + 6 0 (mod 512) 的訊息。
2.分塊
- 把填充後的訊息結果分割為 L 個 512-bit 分組: , , …, 。
- 分組結果也可表示成 N 個32-bit 字 , , …, ,N = L*16。
3.緩衝區初始化
初始化一個128-bit 的 MD 緩衝區,記為 ,表示成4個32-bit暫存器 (A, B, C, D); = IV。迭代在 MD 緩衝區進行,最後一步的128-bit 輸出即為演算法結果。
- 暫存器 (A, B, C, D) 置16進位制初值作為初始向量 IV,並採用小端儲存 (little-endian) 的儲存結構:
- A = 0x67452301
- B = 0xEFCDAB89
- C = 0x98BADCFE
- D = 0x10325476
4.迴圈壓縮
以512-bit 訊息分組為單位,每一分組 Yq (q = 0, 1, …, L-1) 經過4個迴圈的壓縮演算法,表示為:
- = IV
- = ( , )
- 輸出結果:MD = .
三. 模組分解
a. MD5 壓縮函式 HMD5——輪函式
HMD5 從 CV 輸入128位,從訊息分組輸入512位,完成4輪迴圈後,輸出128位,用於下一輪輸入的 CV 值。
每輪迴圈分別固定不同的生成函式 F, G, H, I,結合指定的 T 表元素 T[] 和訊息分組的不同部分 X[] 做16次迭代運算,生成下一輪迴圈的輸入。
4輪迴圈總共有64次迭代運算。
4輪迴圈中使用的生成函式(輪函式) g 是一個32位非線性邏輯函式,在相應各輪
的定義如下:
| 輪次 | Function g | g(b,c,d) |
|---|---|---|
| 1 | F(b, c, d) | (b c) (~b d) |
| 2 | G(b, c, d) | ( ) ( ~d) |
| 3 | H(b, c, d) | b c d |
| 4 | I(b, c, d) | c (b ~d) |
b. MD5 壓縮函式 HMD5——迭代運算
- 每輪迴圈中的一次迭代運算邏輯
(1) 對 A 迭代:a b + ((a + g(b, c, d) + X[k] + T[i]) <<<s)
(2) 緩衝區 (A, B, C, D) 作迴圈輪換:(B, C, D, A) (A, B, C, D) - 說明:
- a, b, c, d : MD 緩衝區 (A, B, C, D) 的當前值。
- g : 輪函式 (F, G, H, I 中的一個)。
- <<<s : 將32位輸入迴圈左移 (CLS) s 位。
- X[k] : 當前處理訊息分組的第 k 個 (k = 0…15) 32位字,即
。 - T[i] : T 表的第 i 個元素,32位字;T 表總共有64個元素,也
稱為加法常數。 - +: 模 232 加法
c. MD5 壓縮函式 HMD5——各輪迴圈的 X[k]
各輪迴圈中第 i 次迭代 (i = 1…16) 使用的 X[k] 的確定:
設 j = i -1:
- 第1輪迭代:k = j.
- 順序使用 X[0, 1, 2, 3, 4, 5, 6, 7, 8, 9,10,11,12,13,14,15]
- 第2輪迭代:k = (1 + 5j) mod 16
- 順序使用 X[1, 6,11, 0, 5,10,15, 4, 9,14, 3, 8,13, 2, 7,12]
- 第3輪迭代:k = (5 + 3j) mod 16.
- 順序使用 X[5, 8,11,14, 1, 4, 7,10,13, 0, 3, 6, 9,12,15, 2]
- 第4輪迭代:k = 7j mod 16.
- 順序使用 X[0, 7,14, 5,12, 3,10, 1, 8,15, 6,13 , 4,11, 2, 9]
d. MD5 壓縮函式 HMD5——T表的生成
T[i] = int($ 2^{32} *|sin(i)|$)
- int 取整函式,sin 正弦函式,以 i 作為弧度輸入
各次迭代運算採用的 T 值:
- T[ 1… 4] = { 0xd76aa478, 0xe8c7b756, 0x242070db, 0xc1bdceee }
- T[ 5… 8] = { 0xf57c0faf, 0x4787c62a, 0xa8304613, 0xfd469501 }
- T[ 9…12] = { 0x698098d8, 0x8b44f7af, 0xffff5bb1, 0x895cd7be }
- T[13…16] = { 0x6b901122, 0xfd987193, 0xa679438e, 0x49b40821 }
- T[17…20] = { 0xf61e2562, 0xc040b340, 0x265e5a51, 0xe9b6c7aa }
- T[21…24] = { 0xd62f105d, 0x02441453, 0xd8a1e681, 0xe7d3fbc8 }
- T[25…28] = { 0x21e1cde6, 0xc33707d6, 0xf4d50d87, 0x455a14ed }
- T[29…32] = { 0xa9e3e905, 0xfcefa3f8, 0x676f02d9, 0x8d2a4c8a }
- T[33…36] = { 0xfffa3942, 0x8771f681, 0x6d9d6122, 0xfde5380c }
- T[37…40] = { 0xa4beea44, 0x4bdecfa9, 0xf6bb4b60, 0xbebfbc70 }
- T[41…44] = { 0x289b7ec6, 0xeaa127fa, 0xd4ef3085, 0x04881d05 }
- T[45…48] = { 0xd9d4d039, 0xe6db99e5, 0x1fa27cf8, 0xc4ac5665 }
- T[49…52] = { 0xf4292244, 0x432aff97, 0xab9423a7, 0xfc93a039 }
- T[53…56] = { 0x655b59c3, 0x8f0ccc92, 0xffeff47d, 0x85845dd1 }
- T[57…60] = { 0x6fa87e4f, 0xfe2ce6e0, 0xa3014314, 0x4e0811a1 }
- T[61…64] = { 0xf7537e82, 0xbd3af235, 0x2ad7d2bb, 0xeb86d391
e. MD5 壓縮函式 HMD5——左迴圈移位的 s 值
各次迭代運算採用的左迴圈移位的 s 值:
- s[ 1…16] = { 7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22 }
- s[17…32] = { 5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20 }
- s[33…48] = { 4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23 }
- s[49…64] = { 6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21 }
四. 資料結構
我的MD5演算法使用了C++類的設計來實現,主要使用陣列來表示迴圈移位表,unsigned int與unsigned char來表示不同的位數,char為8位,int為32位,在不同的表示函式中各有作用,故需要對其進行轉換。
unsigned int state[4]; // 四個暫存器,MD緩衝區,共128位
unsigned int count[2]; // 統計長度,僅保留前64位
unsigned char buffer[512]; // 輸入
unsigned char digest[128]; // 輸出
表示state狀態時,我使用的是16進製表達64位,這樣較簡便
// 初始化獲取IV
state[0] = 0x67452301;
state[1] = 0xefcdab89;
state[2] = 0x98badcfe;
state[3] = 0x10325476;
關於S表,則直接用二維陣列
// 左迴圈移位表
int s[4][4] = {{7,12,17,22},{5,9,14,20},{4,11,16,23},{6,10,15,21}};
對於填充的內容,是1000···000,最多512位,最少要有一位,這是根據填充長度來決定的,使用我直接要預設填充長度為512位。
unsigned char padding[64] =
{0x80, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0};
表示輪函式,則直接根據T表來進行書寫。例如下面
H_F(a, b, c, d, x[0], s[0][0], 0xd76aa478);
H_F(d, a, b, c, x[1], s[0][1], 0xe8c7b756);
H_F(c, d, a, b, x[2], s[0][2], 0x242070db);
···
關於int與char的轉換,是這次演算法實現比較關鍵的部分,因為關於使用byte還是bit取決於函式的需要。以下第一個函式是int轉為char,將1個int轉為4個char,這裡使用位運算+移位的方法,不斷取8位轉化為char。第二個函式是char轉int,也像之前類似,不過是要將4個char轉為1個int,這裡用到的是移位+或運算,這樣就可以得到1個32位int型別。
void my_md5::int_to_char(unsigned char *output, const unsigned int *input, int length){
for (int i = 0, j = 0; i < length; ++i)
{
output[j] = input[i] & 0xff;
output[j+1] = (input[i] >> 8) & 0xff;
output[j+2] = (input[i] >> 16) & 0xff;
output[j+3] = (input[i] >> 24) & 0xff;
j += 4;
}
}
void my_md5::char_to_int(unsigned int *output, const unsigned char *input, int length){
for (int i = 0, j = 0; i < length; i += 4)
{
output[j] = input[i] | (input[i+1] << 8) | (input[i+2] << 16) | (input[i+3] << 24);
j++;
}
}
五. 原始碼
1.MD5類設計
class my_md5
{
public:
my_md5(string& str);
my_md5();
void update(const unsigned char* input_str, int str_length);
// 將128位結果,轉化為16個byte輸出
void show_result();
// 對輸入的字串進行MD5加密
void decode_string(string& str);
~my_md5();
private:
unsigned int state[4]; // 四個暫存器,MD緩衝區,共128位
unsigned int count[2]; // 統計長度,僅保留前64位
unsigned char buffer[512]; // 輸入
unsigned char digest[128]; // 輸出
bool is_padding;
char result[33]; // 32位的輸出結果
// 私有輔助函式,用以變換
// 對於其中一個區塊做變換
void transform(unsigned char block[64]);
// 填充函式,新增長度
void padding();
// 以下兩個函式用以將32位的unsigned int與8位的unsigned char互相轉換輸出
void int_to_char(unsigned char *output, const unsigned int *input, int length);
void char_to_int(unsigned int *output, const unsigned char *input, int length);
// 左移函式
unsigned int shift_left(unsigned int num, int pos);
// 輪函式
unsigned int F(unsigned int b, unsigned int c, unsigned int d);
unsigned int G(unsigned int b, unsigned int c, unsigned int d);
unsigned int H(unsigned int b, unsigned int c, unsigned int d);
unsigned int I(unsigned
相關推薦
MD5演算法原理介紹與C++實現
MD5演算法原理介紹與C++實現
原始碼傳送門:https://github.com/dick20/Web-Security/tree/master/MD5
一. 演算法原理概述
The MD5 message-digest algorithm is a wid
機器學習系列文章:Apriori關聯規則分析演算法原理分析與程式碼實現
1.關聯規則淺談
關聯規則(Association Rules)是反映一個事物與其他事物之間的相互依存性和關聯性,如果兩個或多個事物之間存在一定的關聯關係,那麼,其中一個事物就能通過其他事物預測到。關聯規則是資料探勘的一個重要技術,用於從大量資料中挖掘出有價值的資料
textRank演算法原理介紹與摘要提取
TextRankTextRank 公式在 PageRank 公式的基礎上,為圖中的邊引入了權值的概念:wijwij 就是是為圖中節點 ViVi 到 VjVj 的邊的權值 。dd 依然為阻尼係數,代表從圖中某一節點指向其他任意節點的概率,一般取值為0.85。In(Vi)In(V
歸併排序演算法原理分析與程式碼實現
歸併排序是建立在歸併操作上的一種有效的排序演算法。該演算法是採用分治法(Divide and Conquer)的一個非常典型的應用,歸併排序將兩個已排序的表合併成一個表。
歸併排序基本原理
第五篇:樸素貝葉斯分類演算法原理分析與程式碼實現
1 #====================================
2 # 輸入:
3 # 空
4 # 輸出:
5 # postingList: 文件列表
6 # classVec: 分類標籤列表
7 #=
加密演算法簡要介紹與JAVA實現
【1】MD5是什麼
MD5即Message-Digest Algorithm 5(資訊-摘要演算法5),用於確保資訊傳輸完整一致。是計算機廣泛使用的雜湊演算法之一(又譯摘要演算法、雜湊演算法),主流程式語言普遍已有MD5實現。將資料(如漢字)運算為另一固定長度
MD5演算法原理與實現
由於各種原因,可能存在諸多不足,歡迎斧正!
一、MD5概念
MD5,全名Message Digest Algorithm 5 ,中文名為訊息摘要演算法第五版,為電腦保安領域廣泛使用的一種雜湊函式,用以提供訊息的完整性保護。上面這段話話引用自百度百科,我的理解MD5是
資料結構與演算法——普通樹的定義與C++實現
用樹的第一個兒子和下一個兄弟表示法來表示一個樹。
樹的節點結構為:
struct TreeNode{
TYPE element;//該節點的元素
TreeNode *firstChild;//指向該節點的第一個孩子
TreeNo
資料結構與演算法——B樹的C++實現
It is recommended to refer following posts as prerequisite of this post.
B-Tree is a type of a multi-way search tree. So, if you are not familiar with
k-d樹+bbf演算法的介紹與實現
最近還是一直在研究SIFT演算法,而SIFT特徵點匹配是一個比較經典的問題,使用暴力匹配的話確實可以得到結果,但是執行速度較慢。我的計算機處理是i5的二代系列,匹配兩張各檢測有2000+個SIFT特徵點的影象,通過正反匹配(即取影象1與影象2的匹配結果餘影象2和影象1的匹配
【無監督學習】DBSCAN聚類演算法原理介紹,以及程式碼實現
前言:無監督學習想快一點複習完,就轉入有監督學習 聚類演算法主要包括哪些演算法?主要包括:K-m
speex降噪演算法流程介紹與演算法原理
一、speex降噪流程介紹
本文對speex去噪演算法步驟做一些簡要整理和介紹,以提供給對該演算法感興趣的讀者參考。
1)preprocess_analysis()包括兩部分,主要是加窗交疊傅立葉(fft)變換等常用的訊號處理演算法。
1.1)預處理
C++智慧指標原理分析與簡單實現
一個簡單智慧指標實現的思路如下:
智慧指標,簡單來講是使用引用計數的方法,來跟蹤監控指標。當引用計數為0時就delete 所跟蹤的目標指標,釋放記憶體
智慧指標將一個指標封裝到一個類中,當呼叫
一致性雜湊演算法與C++實現
一. 演算法解決問題
一致性雜湊演算法在1997年由麻省理工學院提出的一種分散式雜湊(DHT)實現演算法,設計目標是為了解決因特網中的熱點(Hot spot)問題,初衷和CARP十分類似。一致性雜湊修正了CARP使用的簡 單雜湊演算法帶來的問題,使得分散式雜湊
邏輯迴歸原理介紹與案例python程式碼實現
邏輯迴歸是用於分類的演算法。平常的線性迴歸方程為f(x)=wx+b,此時f(x)的取值可以是任意的,要讓預測的值可以分類,例如分類到class1是預測值為1,分類到class2時預測值為0。這時我們就要用到分類函式。下面來介紹一個分類函式sigmoid:其中z=wx+bf(z
MD5加密演算法原理及其Go語言實現
MD5訊息摘要演演算法(英語:MD5 Message-Digest Algorithm),一種被廣泛使用的密碼雜湊函式,可以產生出一個128位元(16位元組)的雜湊值(hash value),用於確保資訊傳輸完整一致。
go 呼叫 md5 方法
新建 m
K-近鄰演算法介紹與程式碼實現
宣告:如需轉載請先聯絡我。
最近學習了k近鄰演算法,在這裡進行了總結。
KNN介紹
k近鄰法(k-nearest neighbors)是由Cover和Hart於1968年提出的,它是懶惰學習(lazy learning)的著名代表。它的工作機制比較簡單:
給定一個測試樣本
計算它到訓練樣本的距離
取
推薦模型DeepCrossing: 原理介紹與TensorFlow2.0實現
DeepCrossing是在AutoRec之後,微軟完整的將深度學習應用在推薦系統的模型。其應用場景是搜尋推薦廣告中,解決了特徵工程,稀疏向量稠密化,多層神經網路的優化擬合等問題。所使用的特徵在論文中描述為兩個大類**數值型(文中couting feature)和類別型。如下圖**

space original 註意 libs 波紋 輸出 uil iostream 3.5 轉自:https://www.cnblogs.com/dyufei/p/8205121.html
一. 主要函數介紹
1) 圖像大小變換 cvResize ()
原型:
void