
推薦模型NeuralCF:原理介紹與TensorFlow2.0實現
阿新 • • 發佈:2021-03-27
### 1. 簡介
NCF是協同過濾在神經網路上的實現——**神經網路協同過濾**。由新加坡國立大學與2017年提出。
我們知道,在協同過濾的基礎上發展來的矩陣分解取得了巨大的成就,但是矩陣分解得到低維隱向量求**內積是線性的**,而神經網路模型能帶來**非線性的效果,非線性可以更好地捕捉使用者和物品空間的互動特徵**。因此可以極大地提高協同過濾的效果。
另外,NCF處理的是隱式反饋資料,而不是顯式反饋,這具有更大的意義,在實際生產環境中隱式反饋資料更容易得到。
本篇論文展示了NCF的架構原理,以及實驗過程和效果。
### 2. 網路架構和原理
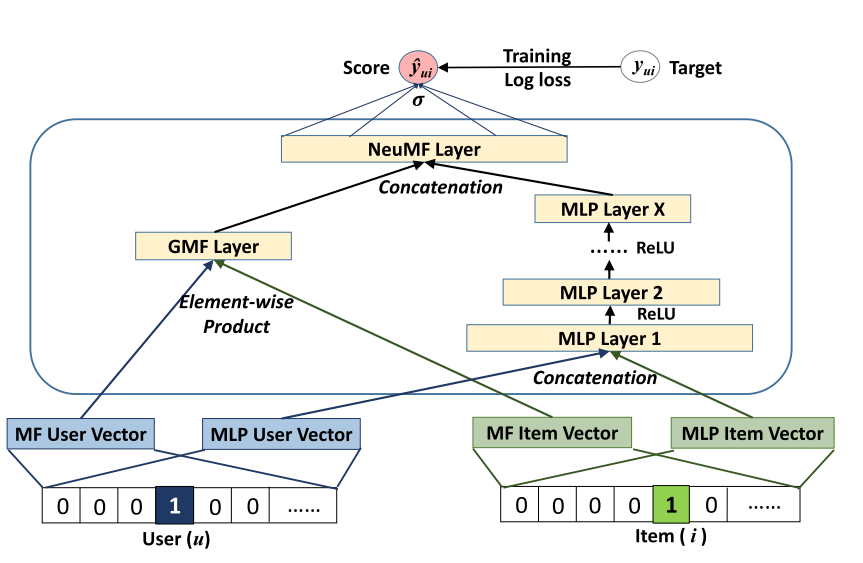
#### 2.1 輸入
由於這篇文章的主要目的是協同過濾,因此輸入為user和item的id,把他們進行onehot編碼,然後使用單層神經網路進行降維即Embedding化。**作為通用框架,其輸入應該不限制與id類資訊,可以是上下文環境,可以是基於內容的特徵,基於鄰居的特徵等輔助資訊。**
*為啥圖中使用兩組user和item的向量?一組走向GMF一組走向MLP?——後續分析*
#### 2.2 MLP部分
可以發現MLP部分為多層感知機的堆疊,每一層的輸出就作為下一層的輸入,文中描述**最後一層Layer X表示模型的容量能力,所以越大容量就越大。**
這部分可以捕獲使用者-物品的互動非線性關係,增強模型的表達能力。
每層的非線性通過ReLu(符合生物學特徵;能帶來稀疏性;符合稀疏資料,比tanh效果好一點)來啟用,可以防止sigmoid帶來的梯度消失問題
#### 2.3 GMF部分
NCF其實是MF的一個通用化框架,去掉MLP部分,如果新增一層element-product(上圖左側),就是使用者-物品隱向量的內積。同時NeuMF Layer僅僅使用線性啟用函式,則最終的結果 就是MF的一個輸出。如果啟用函式是一般的函式,那麼MF可以被稱為GMF,Generalized Matrix Factorization廣義矩陣分解。
#### 2.4目標函式
如果是矩陣分解模型,常處理顯式反饋資料,這樣可以將目標函式定義為**平方誤差損失(MSE)**,然後進行迴歸預測:
$$
L_{sqr}=\sum_{(u,i)\in y\cup y^-}w_{ui}(y_{ui}-\hat{y}_{ui})^2
$$
**隱式反饋資料,MSE不好用,因此隱式反饋資料的標記不是分值而是使用者是否觀測過物品,即1 or 0.**其中,1不代表喜歡,0也不代表不喜歡,僅僅是否有互動行為。
因此,預測分數就可以表示為使用者和物品是否相關,表徵相關的數學定義為概率,因此要限制網路輸出為`[0,1]`,則使用概率函式如,`sigmoid函式。`目的是求得最後一層輸出的概率最大,即使用似然估計的方式來進行推導:
$$
p(y,y^-|P,Q,\Theta_f)=\prod_{(u,i)\in{y}}\hat{y}_{ui}\prod_{(u,j)\in{y^-}}(1-\hat{y}_{uj})
$$
**連乘無法光滑求導,且容易導致數值下溢**,因此兩邊取對數,得到對數損失取負數可以最小化 損失函式,
$$
L=-\sum_{(u,i)\in{y}}log\hat{y}_{ui}-\sum_{(u,j)\in{y^-}}log(1-\hat{y}_{uj})=-\sum_{(u,i)\in{y}\cup{y}^-}y_{ui}log \hat{y}_{ui}+(1-y_{ui})log(1-\hat{y}_{ui})
$$
#### 2.5 GMF和MLP的結合
GMF,它應用了一個線性核心來模擬潛在的特徵互動;MLP,使用非線性核心從資料中學習互動函式。接下來的問題是:我們如何能夠在NCF框架下融合GMF和MLP,使他們能夠相互強化,以更好地對複雜的使用者-專案互動建模?一個直接的解決方法是讓GMF和MLP共享相同的嵌入層(Embedding Layer),然後再結合它們分別對相互作用的函式輸出。這種方式和著名的神經網路張量(NTN,Neural Tensor Network)有點相似。然而,**共享GMF和MLP的嵌入層可能會限制融合模型的效能。例如,它意味著,GMF和MLP必須使用的大小相同的嵌入;對於資料集,兩個模型的最佳嵌入尺寸差異很大,使得這種解決方案可能無法獲得最佳的組合**。為了使得融合模型具有更大的靈活性,我們允許GMF和MLP學習獨立的嵌入,並結合兩種模型通過連線他們最後的隱層輸出。
黑體字部分解釋了輸入部分使用兩組Embedding的作用。
### 3. 程式碼實現
使用TensorFlow2.0和Keras API 構造各個模組層,通過繼承**Layer和Model**的方式來實現。
**1. 輸入資料**
為了簡化模型輸入過程中的引數,使用一個`namedtuple`定義稀疏向量的關係,如下
```python
from collections import namedtuple
# 使用具名元組定義特徵標記:由名字 和 域組成,類似字典但是不可更改,輕量便捷
SparseFeat = namedtuple('SparseFeat', ['name', 'vocabulary_size', 'embedding_dim'])
```
**2. 定義Embedding層**
與[上篇Deep Crossing](https://www.cnblogs.com/sxzhou/p/14532111.html)使用ReLu啟用函式自定義單層神經網路作為Embedding不同的是,使用TF自帶的Embedding模組。
好處是:自定義的Embedding需要自己對類別變數進行onehot後才能輸入,而自帶Embedding只需要定義好輸入輸入的格式,就能自動實現降維效果,簡單方便。
```python
class SingleEmb(keras.layers.Layer):
def __init__(self, emb_type, sparse_feature_column):
super().__init__()
# 取出sparse columns
self.sparse_feature_column = sparse_feature_column
self.embedding_layer = keras.layers.Embedding(sparse_feature_column.vocabulary_size,
sparse_feature_column.embedding_dim,
name=emb_type + "_" + sparse_feature_column.name)
def call(self, inputs):
return self.embedding_layer(inputs)
```
**3. 定義NCF整個網路**
```python
class NearalCF(keras.models.Model):
def __init__(self, sparse_feature_dict, MLP_layers_units):
super().__init__()
self.sparse_feature_dict = sparse_feature_dict
self.MLP_layers_units = MLP_layers_units
self.GML_emb_user = SingleEmb('GML', sparse_feature_dict['user_id'])
self.GML_emb_item = SingleEmb('GML', sparse_feature_dict['item_id'])
self.MLP_emb_user = SingleEmb('MLP', sparse_feature_dict['user_id'])
self.MLP_emb_item = SingleEmb('MLP', sparse_feature_dict['item_id'])
self.MLP_layers = []
for units in MLP_layers_units:
self.MLP_layers.append(keras.layers.Dense(units, activation='relu')) # input_shape=自己猜
self.NeuMF_layer = keras.layers.Dense(1, activation='sigmoid')
def call(self, X):
#輸入X為n行兩列的資料,第一列為user,第二列為item
GML_user = keras.layers.Flatten()(self.GML_emb_user(X[:,0]))
GML_item = keras.layers.Flatten()( self.GML_emb_item(X[:,1]))
GML_out = tf.multiply(GML_user, GML_item)
MLP_user = keras.layers.Flatten()(self.MLP_emb_user(X[:,0]))
MLP_item = keras.layers.Flatten()(self.MLP_emb_item(X[:,1]))
MLP_out = tf.concat([MLP_user, MLP_item],axis=1)
for layer in self.MLP_layers:
MLP_out = layer(MLP_out)
# emb的型別為int64,而dnn之後的型別為float32,否則報錯
GML_out = tf.cast(GML_out, tf.float32)
MLP_out = tf.cast(MLP_out, tf.float32)
concat_out = tf.concat([GML_out, MLP_out], axis=1)
return self.NeuMF_layer(concat_out)
```
**3. 模型驗證**
* *資料處理*
按照論文正負樣本標記為1一個觀測樣本,4個未觀測樣本,所以需要訓練測試集的處理
```python
# 資料處理
# train是字典形式,不然不太容易判斷是否包含u,i對
def get_data_instances(train, num_negatives, num_items):
user_input, item_input, labels = [],[],[]
for (u, i) in train.keys():
# positive instance
user_input.append(u)
item_input.append(i)
labels.append(1)
# negative instances
for t in range(num_negatives):
j = np.random.randint(num_items)
while train.__contains__((u, j)): # python3沒有has_key方法
j = np.random.randint(num_items)
user_input.append(u)
item_input.append(j)
labels.append(0)
return user_input, item_input, labels
# 這個字典,當資料量較大時,可以使用scipy.sparse 的dok_matrix:sparse.dok_matrix
def get_data_dict(data, lst=['userId', 'movieId']):
d = dict()
for idx, row in data[lst].iterrows():
d[(row[0], row[1])] = 1
return d
```
得到資料(可使用movielen資料)
```python
train, test = train_test_split(data, test_size=0.1,random_state=13)
train_dict, test_dict = get_data_dict(train), get_data_dict(test)
train_set, test_set = get_data_instances(train_dict, 4, train['movieId'].max()), get_data_instances(test_dict, 4, test['movieId'].max())
```
* *模型驗證*
```python
# 這裡沒特意設定驗證集,因此直接使用array來餵給模型
BATCH = 128
X = np.array([train_set[0], train_set[1]]).T # 根據模型的輸入為兩列,因此轉置
# 模型驗證
feature_columns_dict = {'user_id': SparseFeat('user_id', data.userId.nunique(), 8),
'item_id': SparseFeat('item_id', data.movieId.nunique(), 8)}
# 模型
model = NearalCF(feature_columns_dict, [16, 8, 4])
model.compile(loss=keras.losses.binary_crossentropy,
optimizer=keras.optimizers.Adam(0.001),
metrics=['acc'])
model.fit(X,
np.array(train_set[2]),
batch_size=BATCH,
epochs=5, verbose=2, validation_split=0.1)
```
out:
```
Train on 408384 samples, validate on 45376 samples
Epoch 5/5
408384/408384 - 10s - loss: 1708.5975 - acc: 0.8515 - val_loss: 277.9610 - val_acc: 0.8635
```
```python
X_test = np.array([test_set[0], test_set[1]]).T
loss, acc = model.evaluate(X_test, np.array(test_set[2]),batch_size=BATCH, verbose=0)
print(loss, acc) # 276.6405882021682 0.86309004
```
**4. 說明**
* `tf.data.Dataset`的資料處理方式已經在前面文章提到了,這裡換種思路和方式,在劃分資料集的時候不劃分驗證集,而是使用array的形式輸入後,在fit階段劃分。如果是Dataset的格式則不能進行fit階段劃分,詳情見官網fit的函式說明。
* 文章中所計算的評估指標是HR@10和NDCG@10,並對BPR,ALS等經典的傳統方法進行了比較發現最終的NCF的效果是最好的;
* 文章中高斯分佈初始化引數,推薦使用的是pre-training的GMF和MLP模型,預訓練過程優化方法為Adam方法,在合併為NCF過程後,由於未儲存引數之外的動量資訊,所以使用SGD方法優化;
* 在合併為NCF時,還有一個可調節超引數是GML_out和MLP_out的係數$\alpha$,pre-training時為0.5,本篇部落格直接使用了0.5且沒有使用預訓練方式,僅僅展示了使用tf構造NCF模型的過程。
* MLP的Layer X越大模型的容量越大,越容易導致過擬合,至於使用多少 視實驗情況而定。文章中使用了`[8, 16, 32, 64]`來測試。
* 與DeepCrossing和AutoRec的深層一樣,越深效果越好。
### 4. 小結
本篇文章介紹了**神經協同過濾**的網路架構和程式碼實踐,並對文章實驗中的細節部分加以說明。
NCF模型混合了MLP和GML二者的特性,具有更強的特徵組合以及非線性表達的能力。
要注意的是模型結構不是越複雜越好,要防止過擬合,這部分並沒有使用Dropout和引數初始化的正則化,因為模型相對簡單。
NCF模型的侷限性在於協同過濾思想中只用使用者-物品的id資訊,儘管可以新增輔助資訊,這些需要後續的研究人員進行擴充套件,同時文章中說損失是基於pointwise的損失 可能也可以嘗試pairwise的