
推薦模型DeepCrossing: 原理介紹與TensorFlow2.0實現
阿新 • • 發佈:2021-03-14
DeepCrossing是在AutoRec之後,微軟完整的將深度學習應用在推薦系統的模型。其應用場景是搜尋推薦廣告中,解決了特徵工程,稀疏向量稠密化,多層神經網路的優化擬合等問題。所使用的特徵在論文中描述為兩個大類**數值型(文中couting feature)和類別型。如下圖**
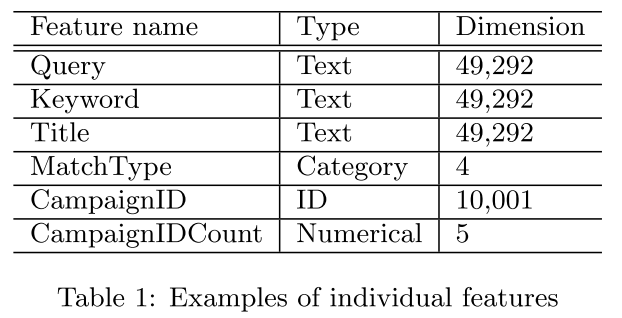
對於數值型特徵可以直接拼接在Embedding向量之後,類別多的特徵需要經過Embedding過程。要多說一句,**數值的統計特徵包括了過去廣告點選率,這個在以後實際應用中設計特徵可以考慮。**
其優化目標就是廣告的點選率,即CTR,click through rate。其效果可以看論文的實現對比部分。這裡簡單介紹,
1. 與傳統模型DSSM進行對比;
2. 與線上生產環境的模型進行對比;
3. counting feature的重要性對比。
### 2. 演算法架構
網路架構解決的問題是:
* 離散特徵過於稀疏的高維災難問題;
* 特徵交叉自動組合問題;
* 輸出層中如何優化目標的設計問題。
#### 網路架構圖
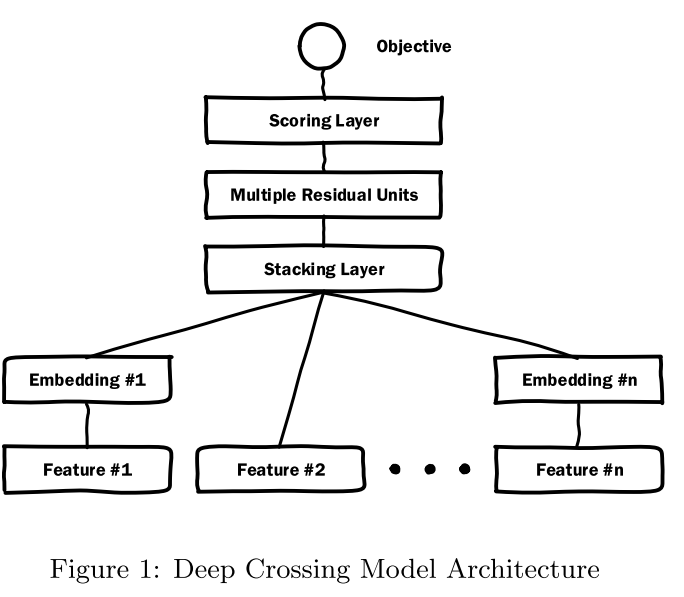
總共包含**Embedding,Stacking,Multiple ResidualUnits和Scoring 層**。
下面根據網路結構圖分別說明各個模組的作用。
#### Embedding層
本層主要作用是**降維**。使用的是一個單層神經網路,具有如下形式,
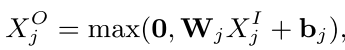
針對每個類別的特徵都有一個Embedding操作,但是如果由於**高維基數特徵太大了,對於目標相關部分排序較低的進行衍生構造。也能降低Embedding部分的引數數量提高訓練速度**例如,`CampaignID`十分巨大,但對於點選率排序後10000以外的使用衍生特徵來處理,最後一個編號為10000,且新增衍生為將所有ID對應的歷史點選率組合成10001維的稠密矩陣,各個元素分別為對應ID的歷史CTR,最後一個元素為剩餘ID的平均CTR。通過降維引入衍生特徵的方式,可以有效的減少高基數特徵帶來的引數量劇增問題。
其中,每個特徵的維度壓縮到**256維**,如果小於256維則直接連線到Stacking層。
#### Stacking層
主要是將Embedding部分的各個特徵的向量進行拼接,小於256維度或者數值型特徵不需要Embedding的直接拼接(如`Feature #2`)。
得到$X^O=[X^O_0, X^O_1,...,X^O_k]$的拼接向量。
#### Residual Layers
首先是殘差單元結構為:
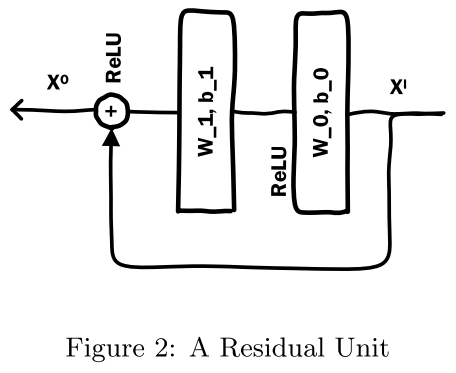
這個殘差模組與ResNet的不同是沒有使用卷積操作,而是ReLu與線性部分的前向傳播加(element-wise add)上輸入再經過ReLu得到輸出。
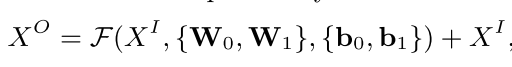
**作者通過各種型別各種大小的實驗發現,DeepCrossing具有很好的魯棒性,推測可能是因為殘差結構能起到類似於正則的效果,殘差結構能更敏感的捕獲輸入輸出之間的資訊差 ,引入特徵的交叉和非線性。**
殘差網路解決的問題:
* 網路深度增加後,過擬合,通過殘差網路的短路操作,起到正則化的作用,減少過擬合;
* 網路深度增加後,梯度消失,所以使用ReLu啟用函式,且短路操作相當於將上上層的梯度傳遞到下層,收斂更快。
原結構使用了五個殘差塊,每個殘差塊的維度是512,512,256,128,64。
#### Scoring Layer
計算得分,即目標函式(objective function)的應用層。
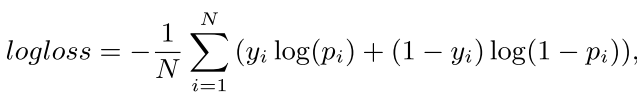
二分類使用Sigmoid函式,多分類使用softmax函式。
### 3. 程式碼實現
基於TensorFlow2.0 和Keras API來實現模型結構。
根據上節每個模組,需要分別實現各個模型的結構,然後組合在一個即可。(原始論文的部分使用的CNTK實現且GPU加速,獲得了效率的顯著提高)
**導包**
```python
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from sklearn.model_selection import train_test_split
import gc
```
**Embedding模組**
這裡自己實現,不使用tf自帶的embedding。
```python
class EmbeddingBlock(keras.layers.Layer):
def __init__(self, emb_dim, input_shapes):
super(EmbeddingBlock, self).__init__()
self.input_shapes = input_shapes
self.listlayer = []
for shape in self.input_shapes:
self.listlayer.append(keras.layers.Dense(emb_dim, input_shape=(shape, ), activation='relu'))
def call(self, X):
stacking = []
last_col = 0
for idx, shape in enumerate(self.input_shapes): # 離散值的onehot維度部分
stacking.append(self.listlayer[idx](X[:, last_col:last_col+shape]))
last_col += shape
stacking.append(X[:, last_col:]) # 連續值
X = tf.concat(stacking, axis=1)
return X
```
這裡主要是將輸入X的前一部分作為需要embedding的部分,後部分作為不需要embedding的部分,然後並行運算,並最後連線在一起。
**定義殘差層**
這裡分為兩個模組分別定義,沒有使用函式,而是直接繼承Keras的API。
```python
class Residual(keras.models.Model):
def __init__(self,hidden_units=None, feature_dim=None) -> None:
super(Residual, self).__init__()
self.relu_layer = keras.layers.Dense(units=hidden_units, input_shape=(feature_dim,), activation='relu')
self.linear_layer = keras.layers.Dense(units=feature_dim, input_shape=(hidden_units,)) # 為了後續相加,要回歸原來的維度
def call(self, X):
X1 = self.relu_layer(X)
X2 = self.linear_layer(X1)
y = keras.activations.relu(tf.add(X, X2)) # or tf.nn.relu, X+X2
return y
class ResidualLayer(keras.layers.Layer):
def __init__(self, units_list=None, feature_dim=None) -> None:
super(ResidualLayer, self).__init__()
self.listlayer = []
for unit in units_list:
self.listlayer.append(Residual(unit, feature_dim))
def call(self, X):
for layer in self.listlayer:
X = layer(X)
return X
```
**串聯整個模型DeepCrossing**
```python
class DeepCrossing(keras.models.Model):
def __init__(self, emb_dim, emb_shapes, residual_units, feature_dims) -> None:
super().__init__()
self.emb = EmbeddingBlock(emb_dim=emb_dim, input_shapes=emb_shapes)
self.stacking_dim = emb_dim*len(emb_shapes) + feature_dims - np.array(emb_shapes).sum()
self.residual_layer = ResidualLayer(residual_units, self.stacking_dim)
self.score_layer = keras.layers.Dense(units=1, input_shape=(self.stacking_dim,), activation='sigmoid')
def call(self, X):
X = self.emb(X)
X = self.residual_layer(X)
X = self.score_layer(X)
return X
```
### 4. 資料驗證
**說個小插曲,使用的資料是MovieLens,在train_test_split的時候會有一個報錯 大概是MemoryError的問題,因為使用的列比較多。後來就抽取了一千條資料來驗證模型。估計使用迭代器和tf.data的生成器會比較好操作。**
**合併資料**
```python
rating = pd.read_csv('./ratings.dat', sep='::', names=['UserID', 'MovieID', 'Rating', 'Timestamp'])
user = pd.read_csv('./users.dat', sep='::', names=['UserID', 'Gender', 'Age', 'Occupation', 'ZipCode'])
movie = pd.read_csv('./movies.dat', sep='::', names=['MovieID', 'Title', 'Genres'])
data = pd.merge(left=rating, right=user, how='inner', on='UserID')
data = data.merge(movie, on='MovieID')
```
**構造標籤**
為了保證正負樣本相對平衡,契合評分層的二分類模型,這裡直接將3分以上的認為是正樣本(也可以定義為多分類 使用softmax層作為評分層)。
`data['label'] = (data['Rating'] > 3).astype(np.int)`
**處理資料**
把電影名字的時間抽取出來
```python
data['Year'] = data['Title'].apply(lambda x: x[-5:-1]).astype(int)
data['Title'] = data['Title'].apply(lambda x: x[:-7])
```
為了方便,不使用Title作為特徵(否則使用Token然後Embedding處理也是很好的)。
統計各個特徵數量,以便確定誰要Embedding層:
```python
tmp = data.copy()
for col in ['Gender', 'Occupation', 'ZipCode', 'Title', 'Genres']:
print(col, tmp[col].unique().shape[0])
=============================================
Gender 2
Occupation 21
ZipCode 3439
Title 3664
Genres 301
```
oenhot處理併合並:
```python
dummy_col = ['ZipCode', 'Genres', 'Gender', 'Occupation']
tmp1 = pd.get_dummies(tmp[dummy_col],
prefix=dummy_col,
columns=dummy_col)
resDF = pd.concat([tmp1, tmp[[ 'Age', 'Year','Timestamp','UserID', 'MovieID', 'label']] ], axis=1)
```
構造Dataset
```python
X = resDF.iloc[:1000,:-3]
y = resDF.iloc[:1000, -1]
num_or_size_splits = [int(y.shape[0]*0.9), int(y.shape[0]*0.1 + 0.5)]
num_or_size_splits # [900, 100]
X = tf.constant(X.values, dtype=tf.float32)
y = tf.constant(y.to_list(), dtype=tf.float32)
X_train, X_test = tf.split(X, num_or_size_splits, axis=0)
y_train, y_test = tf.split(y, num_or_size_splits, axis=0)
BATCH = 128
train_ds = tf.data.Dataset.from_tensor_slices((X_train, y_train)).batch(BATCH).shuffle(2).repeat()
test_ds = tf.data.Dataset.from_tensor_slices((X_test, y_test)).batch(32)
```
**訓練模型**
```python
net = DeepCrossing(emb_dim=128,
emb_shapes=[3439, 301],
residual_units=[256, 128, 64],
feature_dims=len(resDF.columns)-3)
net.compile(loss='binary_crossentropy',
optimizer=keras.optimizers.Adam(lr=0.01),
metrics=['accuracy'])
net.fit(train_ds, epochs=5, steps_per_epoch=X.shape[0]//BATCH)
```
```
Train for 7 steps
Epoch 1/5
7/7 [==============================] - 5s 690ms/step - loss: 160474554.2098 - accuracy: 0.6192
Epoch 2/5
7/7 [==============================] - 0s 7ms/step - loss: 30519627.1429 - accuracy: 0.7679
Epoch 3/5
7/7 [==============================] - 0s 8ms/step - loss: 6237030.3564 - accuracy: 0.8692
Epoch 4/5
7/7 [==============================] - 0s 7ms/step - loss: 6711226.7366 - accuracy: 0.7461
Epoch 5/5
7/7 [==============================] - 0s 7ms/step - loss: 3462408.0007 - accuracy: 0.7345
```
測試集驗證:
```python
loss, acc = net.evaluate(test_ds)
print('loss: ', loss, ' acc: ', acc)
=================================
loss: 1159263.28125 acc: 0.93
```
### 4. 小結
Deep Crossing模型沒有引入現代流行的注意力機制,序列模型的特殊結構,但是相比FM,FFM模型只具備二階特徵交叉能力來說,這模型可以更深層次的交叉,且獨立特徵之外,沒有人工設計的組合