
損失函式loss改進解析
題圖依然來自Coco!上篇地址:
YaqiLYU:人臉識別的LOSS(上)
Feature Normalization
- Liu Y, Li H, Wang X. Rethinking feature discrimination and polymerization for large-scale recognition [C]// NIPS workshop, 2017.
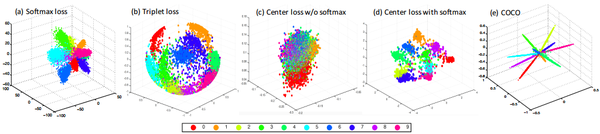
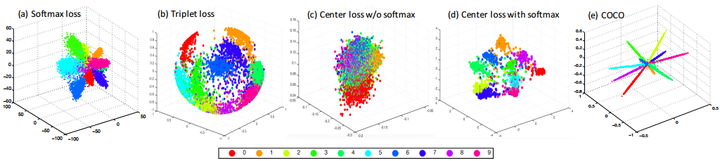
COCO(congenerous cosine) loss: sciencefans/coco_loss

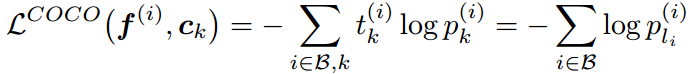
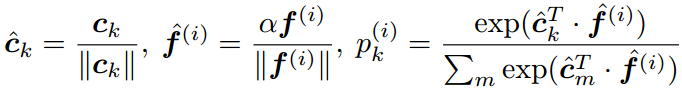

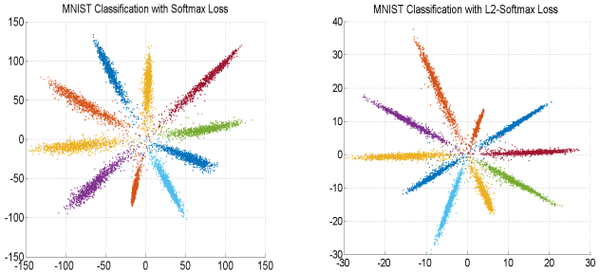
half MS-1M訓練集,用coco loss訓練Inception ResNet,在LFW上達到99.86%,接近滿分,但要注意,同樣的訓練集和CNN,Softmax loss訓練的結果是99.75%。
- Ranjan R, Castillo C D, Chellappa R. L2-constrained softmax loss for discriminative face verification [J]. arXiv:1703.09507, 2017.

L2-Softmax: 在Softmax的w*x基礎上,將特徵向量x做歸一化,並乘尺度因子進行放大:
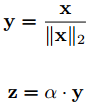
尺度因子 可以是固定值,也可以自適應訓練,建議用固定值
。可以MS-Celeb-1M的子集3.7M影象作為訓練集,用L2-Softmax訓練ResNeXt-101在LFW上達到了99.78%,與center loss聯合使用也有提升。
- Wang F, Xiang X, Cheng J, et al. NormFace: L2 Hypersphere Embedding for Face Verification [C]// ACM MM, 2017.
NormFace: happynear/NormFace,歸一化了特徵,同樣加了尺度因子s,但這裡推薦用自動學習的方法:
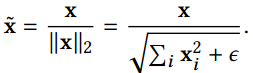
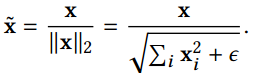

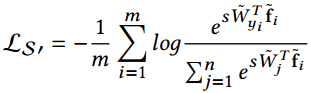
歸一化後的softmax, contrastive 和center loss都用不同程度的提升,0.49M的CASIA-WebFace訓練集28層ResNet,歸一化前後,softmax從98.28%提升到99.16%,center loss從99.03%提升到了99.17%。
特徵歸一化的重要性
- 從最新方法來看,權值W和特徵f(或x)歸一化已經成為了標配,而且都給歸一化特徵乘以尺度因子s進行放大,目前主流都採用固定尺度因子s的方法(看來自適應訓練沒那麼重要);
- 權值和特徵歸一化使得CNN更加集中在優化夾角上,得到的深度人臉特徵更加分離;
- 特徵歸一化後,特徵向量都固定對映到半徑為1的超球上,便於理解和優化;但這樣也會壓縮特徵表達的空間;乘尺度因子s,相當於將超球的半徑放大到s,超球變大,特徵表達的空間也更大(簡單理解:半徑越大球的表面積越大);
- 特徵歸一化後,人臉識別計算特徵向量相似度,L2距離和cos距離意義等價,計算量也相同,我們再也不用糾結到底用L2距離還會用cos距離:
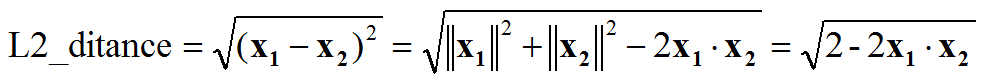
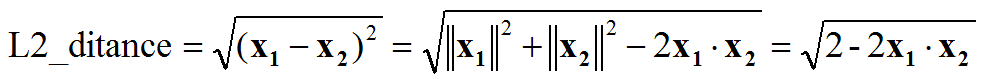

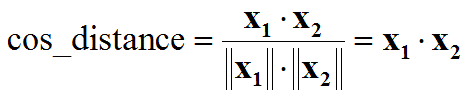
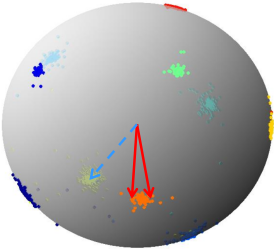
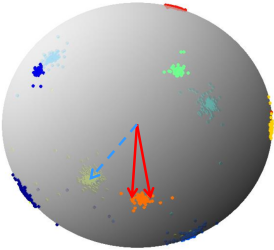
- 為什麼僅特徵歸一化無法收斂,而必須乘固定尺度因子呢?以四分類為例分析。
- 僅特徵歸一化時,輸出
等價於
,理想情況下,優後
是0,x2=x3=x4都輸出0,此時啟用值為{1, 0, 0, 0},指數函式非線性放大後輸出為{e, 1, 1, 1},歸一化後置信度是{47.54%, 17.49%, 17.49%, 17.49%},遠遠達不到收斂的要求,所以僅歸一化是不能訓練的。
- 歸一化後乘尺度因子s,這裡以s=60為例,輸出
,理想情況下,優後
Additive Margin Loss
- Wang F, Liu W, Liu H, et al. Additive Margin Softmax for Face Verification [C]// ICLR 2018 (Workshop) .


AM-Softmax:happynear/AMSoftmax,在SphereFace的基礎上,乘性margin改成了加性margin,即 變成了
,在權值W歸一化的基礎上對特徵f也做了歸一化,採用固定尺度因子s=30,相比SphereFace效能有提升,最重要的是訓練難度大幅降低,不需要退火優化。此外,論文還做了訓練集CASIA-WebFace與測試集LFW和MegaFace的重疊identity清理,LFW從Center Loss和SphereFace清理的3對增加到17對,實驗證明影響較大。AM-Softmax的特點是小訓練集小網路,僅20層CNN,在清理後CASIA-WebFace上訓練,LFW達到了98.98%,在MegaFace上較SphereFace提升明顯,有原始碼的好文推薦!
- Wang H, Wang Y, Zhou Z, et al. CosFace: Large Margin Cosine Loss for Deep Face Recognition [C]// CVPR, 2018.
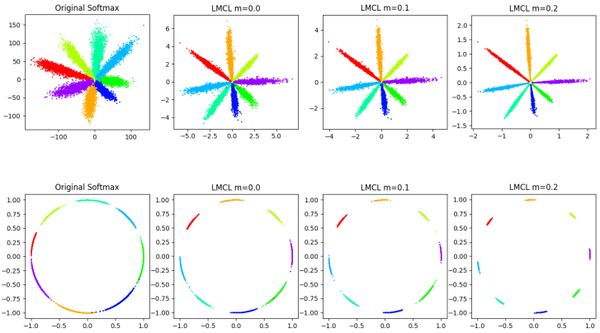
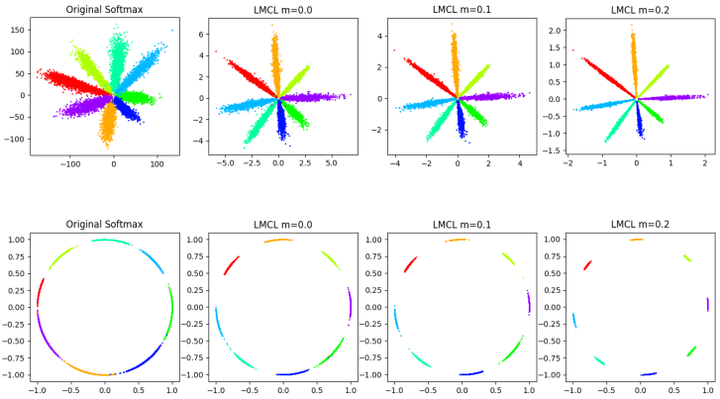
CosFace:與AM-Softmax完全一樣,同樣的加性margin,同樣的特徵歸一化,工作完成比AM-Softmax早。兩個訓練集沒有提重疊身份清理的問題,0.49M小訓練集CASIA-Webface,5M騰訊自己收集的大訓練集,訓練64層CNN,LFW上99.73%,MegaFace上大小訓練集都是SOTA。對比AM-Softmax的結果,CosFace大網路和大訓練集的效能提升非常明顯,沒有原始碼。
- Jiankang Deng, Jia Guo, Stefanos Zafeiriou. ArcFace: Additive Angular Margin Loss for Deep Face Recognition [J]. arXiv:1801.07698. (Submitted to IJCV)
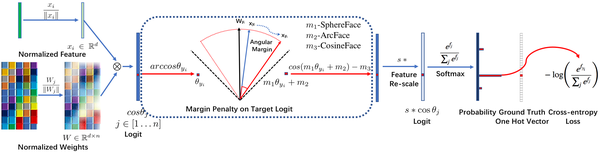
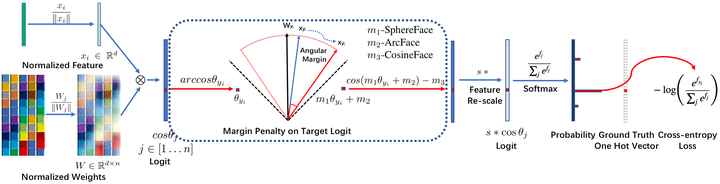
ArcFace: deepinsight/insightface,這個不是虹軟的!這個不是虹軟的!這個不是虹軟的!僅僅是演算法與虹軟的人臉識別SDK重名了,沒有一點關係。論文叫ArcFace,程式碼叫insightface,在SphereFace的基礎上,同樣改用加性margin但形式略有區別, 變成了
,同樣也做了特徵歸一化,固定因子s=64。ArcFace的特點是大訓練集加大網路,也做了細緻的訓練集和測試集清理,訓練集MS-Celeb-1M從100k-10M清理到85k-3.8M,測試集MegaFace演算法加人工清理後識別率提高了15%,大網路是100層CNN,在LFW上做到了99.83%,在MegaFace上large也是SOTA,目前是榜單第一名,論文篇幅較長,實驗細緻,強力推薦好文!
強力推薦insightface人臉識別project,基於mxnet訓練速度快,包含所有sota的backbone和loss方便上手 InsightFace - 使用篇, 如何一鍵刷分LFW 99.80%, MegaFace 98% ,為了用這套環境,我已經轉mxnet了 -_-!
不同margin的對比
目前人臉識別演算法以large margin為主,這裡提出並討論兩個問題:
問題一:large margin為什麼能work?
- L-Softmax重構了Softmax,輸出x變成
,SphereFace歸一化權值W,變成
;最新AM-Softmax和ArcFace繼續歸一化特徵乘尺度因子,變成
。所以這裡我們簡化問題,預設歸一化權值W和特徵f,即
,僅考慮
這一項變動對分類任務的影響。
- 還是討論四分類問題,輸出
。原始Softmax在輸出x = {5, 1, 1, 1}時就接近收斂,訓練停止,此時改用large margin softmax,第一列的
、
或
,會使輸出減小,其他列保持不變,此時輸出可能變成了x = {4, 1, 1, 1},網路又可以繼續訓練了。
- 這一過程與“從hardmax的
到softmax的
非線性放大了輸出,減小訓練難度,使分類問題更容易收斂”正好相反,從
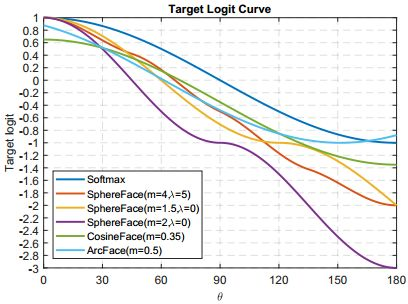
- 不同loss的曲線對比,下圖來自ArcFace,所有loss都是單調遞減的。對比Softmax的
問題二:Large Margin到底優化了什麼?
前面提到large margin顯式約束了類間分離,看視覺化結果好像也是這樣,但其實這種說法是不對的。
- large margin優化的核心——夾角
- 具體來看
、
或
,都減小了輸出啟用值,如果要達到目標置信度100%,就需要優化出比Softmax更小的夾角
- 對特定類別來說,假如有1000張影象,經CNN特徵對映後得到1000個特徵向量,而權值向量W是每個類別只有一個,large margin loss要求這1000個特徵向量和這1個權值向量的夾角非常小,也就是說,優化讓1000個特徵向量都向權值向量W的方向靠攏。
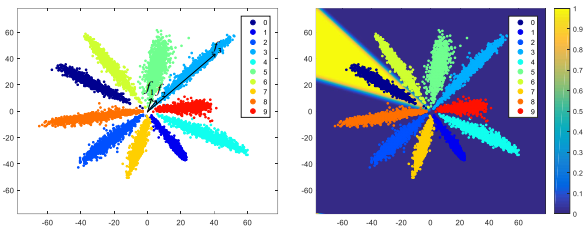
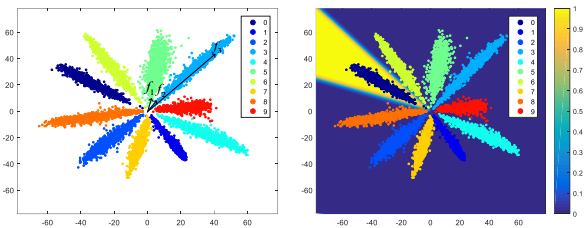
- 下圖是SphereFace(m=4)在MNIST上跑出來的特徵對映,不同顏色代表不同類別,每個類別的中心白線就是這個類別的權值向量視覺化的結果,與前面的分析完全一致。結論就是:large magin是顯式的類內夾角約束,目標是讓同一類的所有特徵向量都拉向該類別的權值向量。

人臉識別的SOTA
影響演算法效能的因素:
- 訓練集:一般訓練集類別數越多,影象數量越多,訓練效果越好。此外訓練集的收集和標註質量,不同類別的樣本數量是否均衡,都對訓練有影響。
- CNN:一般CNN的容量越大,訓練效果越好。CNN的模型容量參考ImageNet上的分類效能,與引數數量和執行速度並不是正比關係。
- LOSS:這部分才是前面介紹的loss相關影響,特別注意,對比某個loss的效能提升,要綜合考慮訓練集和CNN,不能簡單的看LFW上的識別率。
最常用的兩個人臉識別測試庫,和以上推薦演算法的效能比較,結果來自論文:
- LFW:LFW Face Database : Main,錯誤列表:LFW Face Database : Main,使用最多的必跑測試庫,從2015年FaceNet的99.63%開始就接近飽和了,目前所有演算法都在99%以上,比較意義不大。特別舉兩個用Softmax loss訓練的例子:COCO中half MS-1M訓練Inception ResNet是99.75%,ArcFace中MS1M訓練ResNet100是99.7%。
- MegaFace: MegaFace,目前最大也最具挑戰性的測試集,但由於這個資料集質量較差,非常容易作弊,建議以有開原始碼的演算法,自行訓練的結果為準。問題討論: iBUG_DeepInsight · Issue #49 · deepinsight/insightface。
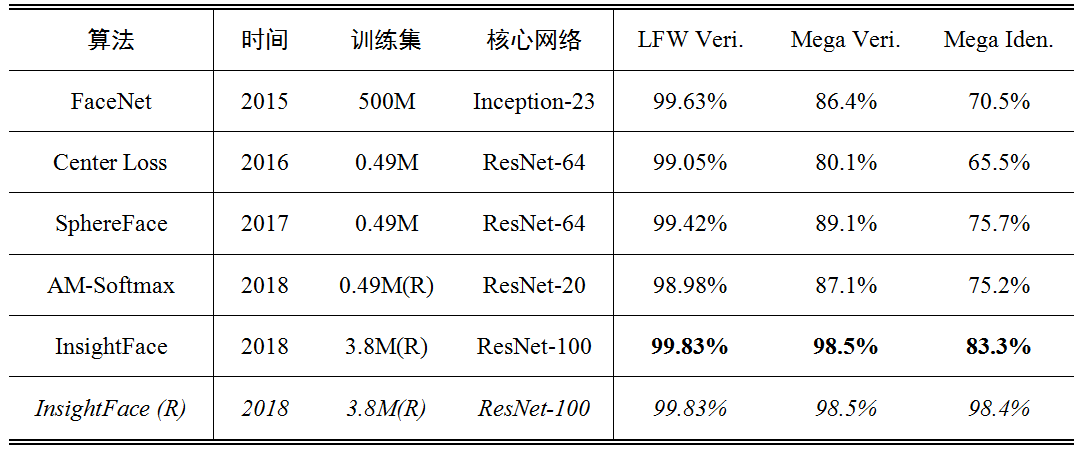
上表中AM-Softmax和InsightFace都做了更細緻的訓練集重疊清洗,最後一行代表InsightFace對測試集也做了清洗的結果。