
損失函式loss大大總結
最大間隔損失主要引入了夾角cos值進行距離的度量。假設bias為0的情況下,就可以得出如上的公式。
其中fai(seita)需要滿足下面的條件。
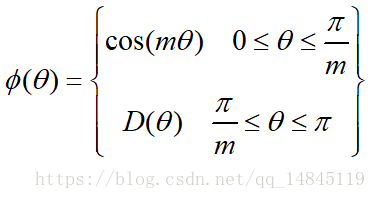
為了進行距離的度量,在cos夾角中引入了引數m。該m為一個正整數,可以起到控制類間間隔的作用。M越大,類間間隔越大。當m=1時,等價於傳統交叉熵損失。基本原理如下面公式

論文中提供的滿足該條件的公式如下
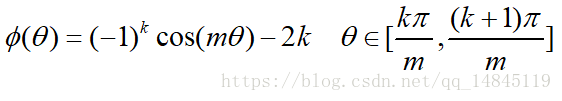
中心損失center loss:
中心損失主要主要用於減少類內距離,雖然只是減少了累內距離,效果上卻可以表現出累內距離小了,類間距離就可以增大的效果。該損失不可以直接使用,需要配合傳統的softmax loss一起使用。可以起到比單純softmax loss更好的分類效果。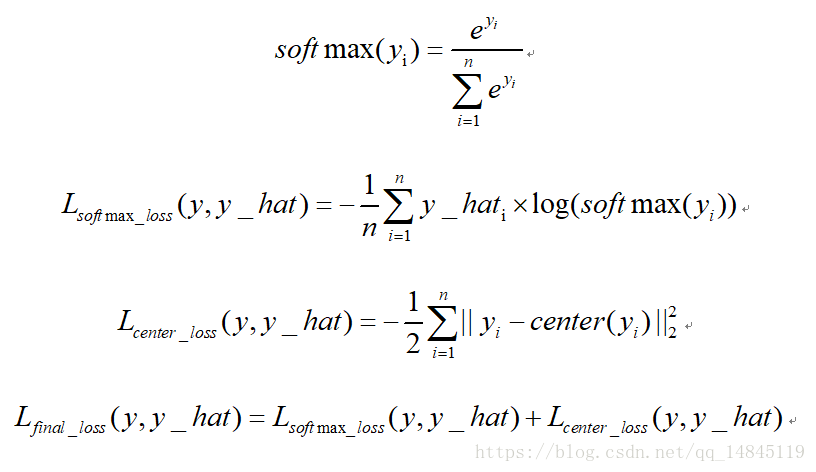
迴歸任務loss:
均方誤差mean squareerror(MSE)和L2範數:
MSE表示了預測值與目標值之間差值的平方和然後求平均
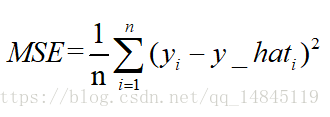
L2損失表示了預測值與目標值之間差值的平方和然後開更方,L2表示的是歐幾里得距離。
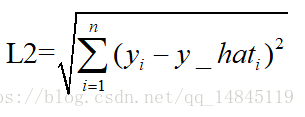
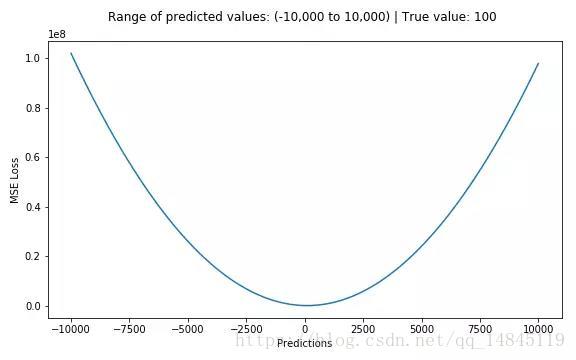
MSE和L2的曲線走勢都一樣。區別在於一個是求的平均np.mean(),一個是求的更方np.sqrt()
相關推薦
損失函式loss大大總結
最大間隔損失主要引入了夾角cos值進行距離的度量。假設bias為0的情況下,就可以得出如上的公式。其中fai(seita)需要滿足下面的條件。為了進行距離的度量,在cos夾角中引入了引數m。該m為一個正整數,可以起到控制類間間隔的作用。M越大,類間間隔越大。當m=1時,等價於傳統交叉熵損失。基本原理如下面公式
損失函式 loss function 總結(轉)
目標函式,或稱損失函式,是網路中的效能函式,也是編譯一個模型必須的兩個引數之一。由於損失函式種類眾多,下面以keras官網手冊的為例。 在官方keras.io裡面,有如下資料: mean_squared_error或mse mean_absolute_err
損失函式loss大總結
目標函式objectives 目標函式,或稱損失函式,是編譯一個模型必須的兩個引數之一: model.compile(loss='mean_squared_error', optimizer='sgd') 可以通過傳遞預定義目標函式名字指定目標函式,也可以傳遞一個Th
損失函式loss改進解析
題圖依然來自Coco!上篇地址: YaqiLYU:人臉識別的LOSS(上) zhuanlan.zhihu.com Feature Normalization Liu Y, Li H, Wang X. Rethinking feature discri
關於機器學習中的損失函式loss function
深度學習的目標是訓練出一個模型,用這個模型去進行一系列的預測。於是我們將訓練過程涉及的過程抽象成數學函式,首先,需要定義一個網路結構,相當於定義一種線性非線性函式,接著,設定一個優化目標,也就是定義一種損失函式。
損失函式(Loss function)和代價函式(成本函式)(Cost function)的區別與聯絡
1.損失函式(Loss function)是定義在單個訓練樣本上的,也就是就算一個樣本的誤差,比如我們想要分類,就是預測的類別和實際類別的區別,是一個樣本的哦,用L表示 2.代價函式(Cost function)是定義在整個訓練集上面的,也就是所有樣本的誤差的總和的平均,也
損失函式總結
1. 前言 在機器學習中,不同的問題對應了不同的損失函式,不同的損失函式也直接會影響到收斂的快慢和結果的好壞,下面就從不同的損失函式的角度進行一下梳理。 2. 0-1損失函式 0-1損失是指,預測值和目標值不相等為1,否則為0 3. log對數損失函式 邏輯迴歸的損失函式就是對數損失函式,在邏輯迴歸
pytorch系列12 --pytorch自定義損失函式custom loss function
本文主要內容: nn.Module 和 nn.Functional 區別和聯絡 自定義損失函式 1. 關於nn.Module與nn.Functional的區別: https://discuss.pytorch.org/t/whats-the-differe
深度學習基礎--loss與啟用函式--感知損失(Perceptual Loss)
感知損失(Perceptual Loss) 常用於GAN網路生成。 Perceptual Loss的出現證明了一個訓練好的CNN網路的feature map可以很好的作為影象生成中的損失函式的輔助工具。 GAN可以利用監督學習來強化生成網路的效果。其效果的原因雖然還不具可解釋
深度學習基礎--loss與啟用函式--合頁損失函式、摺頁損失函式;Hinge Loss;Multiclass SVM Loss
合頁損失函式、摺頁損失函式;Hinge Loss;Multiclass SVM Loss Hinge Loss是一種目標函式(或者說損失函式)的名稱,有的時候又叫做max-margin objective。用於分類模型以尋找距離每個樣本的距離最大的決策邊界,即最大化樣本和邊界之間的邊
深度學習基礎--loss與啟用函式--sigmiod與softmax;對數損失函式與交叉熵代價函式
sigmiod與softmax sigmiod就是邏輯迴歸(解決二分類問題);softmax是多分類問題的邏輯迴歸 雖然邏輯迴歸能夠用於分類,不過其本質還是線性迴歸。它僅線上性迴歸的基礎上,在特徵到結果的對映中加入了一層sigmoid函式(非線性)對映,即先把特徵線性求和,然後使
線性支援向量機-合頁損失函式(Hinge Loss)
線性支援向量機學習有另一種解釋,那就是最小化以下目標函式: ∑ i
【調參之損失函式】train loss 和 test loss 一直不下降
正常情況: train loss 不斷下降,test loss不斷下降,說明網路仍在學習; 異常情況: train loss 不斷下降,test loss趨於不變,說明網路過擬合; train loss 趨於不變,test loss不斷下降,說明資料集100%有問題; train los
CS231n 卷積神經網路與計算機視覺 6 資料預處理 權重初始化 規則化 損失函式 等常用方法總結
1 資料處理 首先註明我們要處理的資料是矩陣X,其shape為[N x D] (N =number of data, D =dimensionality). 1.1 Mean subtraction 去均值 去均值是一種常用的資料處理方式.它是將各個特徵值減去其均
損失函式的總結與比較
https://www.cnblogs.com/shixiangwan/p/7953591.html 損失函式(loss function)是用來估量你模型的預測值f(x)與真實值Y的不一致程度,它是一個非負實值函式,通常使用L(Y, f(x))來表示,損失函式越小,模型的魯棒
COCO loss (人臉識別損失函式)
2017年nips的一篇做分類和識別的工作,其中在人臉識別任務上也做了實驗,Rethinking Feature Discrimination and Polymerization for Large-scale Recognition.Yu Liu, Hongyang Li, Xiao
faster rcnn中損失函式(二)—— Smoooh L1 Loss的講解
1. 使用Smoooh L1 Loss的原因 對於邊框的預測是一個迴歸問題。通常可以選擇平方損失函式(L2損失)f(x)=x^2。但這個損失對於比較大的誤差的懲罰很高。 我們可以採用稍微緩和一點絕對損失函式(L1損失)f(x)=|x|,它是隨著誤差線性增長,而不是平方增長
機器學習中的損失函式總結
損失函式(loss function)是用來估量你模型的預測值f(x)與真實值Y的不一致程度,它是一個非負實值函式,通常使用L(Y, f(x))來表示,損失函式越小,模型的魯棒性就越好。損失函式是經驗風險函式的核心部分,也是結構風險函式重要組成部分。模型的結構風險函式包括
機器學習基礎(四十二)—— 常用損失函式的設計(multiclass SVM loss & hinge loss)
損失函式,又叫代價函式(成本函式,cost function),是應用優化演算法解決問題的關鍵。 1. 0-1 損失函式 誤分類的概率為: P(Y≠f(X))=1−P(Y=f(X)) 我們不妨記 m≜fθ(x)⋅y(其中 y∈{−1,1}。對於二分類
常用損失函式(Loss Function)
【深度學習】一文讀懂機器學習常用損失函式(Loss Function) 最近太忙已經好久沒有寫部落格了,今天整理分享一篇關於損失函式的文章吧,以前對損失函式的理解不夠深入,沒有真正理解每個損失函式的特點以及應用範圍,如果文中有任何錯誤,請各位朋友指教,謝謝~ 損失函式(lo