
Storm入門介紹一
概述
離線計算是什麼?
批量獲取資料,批量傳輸資料,週期性批量計算資料,資料展示。(形象的比喻:電梯載客,一波一波的來)
代表技術:Sqoop 批量匯入資料,HDFS 批量儲存資料 ,MapRduce Hive 批量計算資料,azkaban 任務排程。
日常業務:hivesql , 排程平臺 ,Hadoop叢集運維 ,資料清洗 ,元資料管理 ,資料稽查 ,資料倉庫模型架構
流式計算是什麼?
資料實時產生,資料實時傳說,資料實時計算,資料實時顯示。(形象的比喻:商場自動扶梯,來一個上一個)
代表技術:Flume實時獲取資料、Kafka/metaq實時資料儲存、Storm/JStorm實時計算、Redis實時結果快取
總結:將源源不斷產生的資料實時手機並實時計算,儘可能快的得到計算結果,用來支援決策。
離線計算與實時計算的區別
最大的區別:試試收集、實時計算、實時顯示
離線計算:一次計算很多條資料
實時計算:資料一條一條的計算
Storm是什麼?
storm是用來實時處理資料,特點:低延遲、高可用、分散式、可擴充套件、資料不丟失。提供簡單的介面,便於開發。
Storm的應用場景
Storm 處理資料的方式是基於資訊的流水線處理,因此特別適合無狀態計算,也就是計算單元的依賴的資料全部在接受的資訊中可以找到,並且最好一個數據流不依賴另一個數據流。
因此,常常用於
-日誌分析,從海量日誌分析出特定的資料,並將分析的結果存入外部儲存器用於輔助決策。
-管道系統,將一個數據從一個系統傳出到另外一個系統,比如從資料庫同步到Hadoop
-訊息轉化器,將接受到的訊息按照某種格式進行轉化,儲存到另外一個系統如訊息中介軟體
-統計分析器,從日誌或訊息中,提煉某個欄位,然後做 count 或 sum計算,最終將統計值存入外部儲存器。
案例一:一淘-實時分析系統
一淘-實時分析系統:實時分析使用者的屬性,並反饋給搜尋引擎。最初,使用者屬性分析是通過每天在雲梯上定時執行的MR job來完成的。為了滿足實時性的要求,希望能夠實時分析使用者的行為日誌,將最新的使用者屬性反饋給搜尋引擎,能夠為使用者展現最貼近其當前需求的結果。
案例二:攜程-網路效能監控
攜程-網站效能監控:實時分析系統監控攜程網的網站效能。利用HTML5獲得可用的指標,並記錄日誌。Storm叢集實時分析日誌和入庫。使用DRPC聚合成報表,通過歷史資料對比等判斷規則,觸發預警事件。
案例三:遊戲實時運營
一個遊戲新版本上線,有一個實時分析系統,收集遊戲中的資料,運營或者開發者可以在上線後幾秒鐘得到持續不斷更新的遊戲監控報告和分析結果,然後馬上針對遊戲的引數 和平衡性進行調整。這樣就能夠大大縮短遊戲迭代週期,加強遊戲的生命力。
案例四:實時計算在騰訊中的運用
實時計算在騰訊的運用:精準推薦(廣點通廣告推薦、新聞推薦、視訊推薦、遊戲道具推薦);實時分析(微信運營資料門戶、效果統計、訂單畫像分析);實時監控(實時監控平臺、遊戲內介面呼叫)
案例五:實時計算在阿里的運用
為了更加精準投放廣告,阿里媽媽後臺計算引擎需要維護每個使用者的興趣點(理想狀態是,你對什麼感興趣,就向你投放哪類廣告)。使用者興趣主要基於使用者的歷史行為、使用者的實時查詢、使用者的實時點選、使用者的地理資訊而得,其中實時查詢、實時點選等使用者行為都是實時資料。考慮到系統的實時性,阿里媽媽使用Storm維護使用者興趣資料,並在此基礎上進行受眾定向的廣告投放。
Storm架構
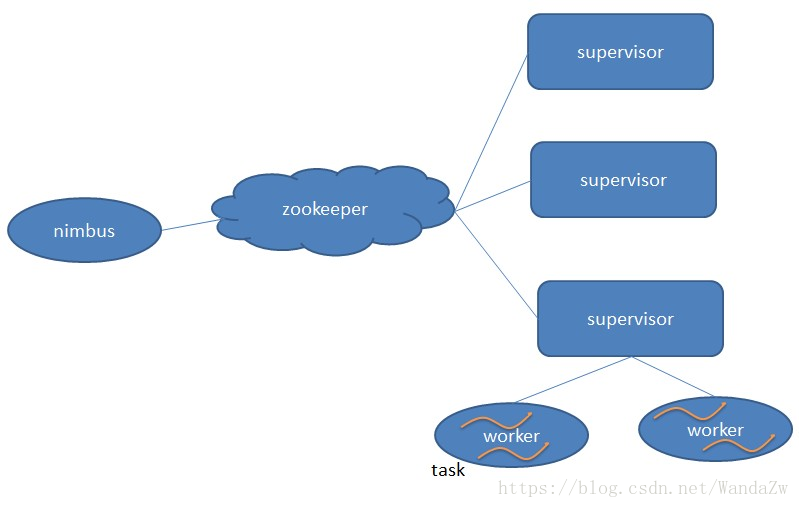
Nimbus: 負責資源分配和任務排程。
Supervisor:負責接受nimbus分配的任務,啟動和停止屬於自己管理的worker程序。
Worker:執行具體處理元件邏輯的程序。
Task:worker中每一個 spout/blot的縣城成為一個task ,在storm0.8之後,task不再於物理執行緒對應,同一個spout/bolt的task可能共享一個物理執行緒,該執行緒成為 executor.
Storm程式設計模型
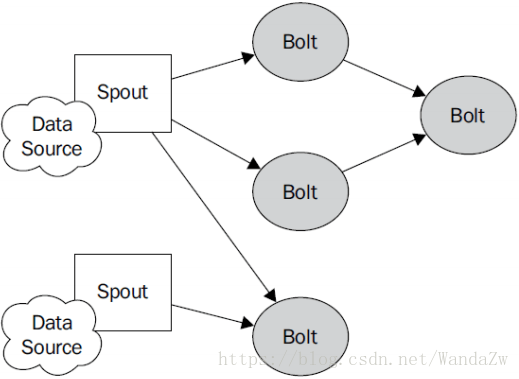
Topology:Storm中執行的一個實時應用程式,因為各個元件間的訊息流動形成邏輯上的一個拓撲結構。
Spout:在一個topology中產生源資料流的元件。通常情況下spout會從外部資料來源中讀取資料,然後轉換為topology內部的源資料。Spout是一個主動的角色,其介面中有個nextTuple()函式,storm框架會不停地呼叫此函式,使用者只要在其中生成源資料即可。
Bolt:在一個topology中接受資料然後執行處理的元件。Bolt可以執行過濾、函式操作、合併、寫資料庫等任何操作。Bolt是一個被動的角色,其介面中有個execute(Tuple input)函式,在接受到訊息後會呼叫此函式,使用者可以在其中執行自己想要的操作。
Tuple:一次訊息傳遞的基本單元。本來應該是一個key-value的map,但是由於各個元件間傳遞的tuple的欄位名稱已經事先定義好,所以tuple中只要按序填入各個value就行了,所以就是一個value list.
Stream:源源不斷傳遞的tuple就組成了stream。
Stream grouping
Stream grouping:即訊息的partition方法。
Stream Grouping定義了一個流在Bolt任務間該如何被切分。這裡有Storm提供的6個Stream Grouping型別:
1. 隨機分組(Shuffle grouping):隨機分發tuple到Bolt的任務,保證每個任務獲得相等數量的tuple。
2. 欄位分組(Fields grouping):根據指定欄位分割資料流,並分組。例如,根據“user-id”欄位,相同“user-id”的元組總是分發到同一個任務,不同“user-id”的元組可能分發到不同的任務。
3. 全部分組(All grouping):tuple被複制到bolt的所有任務。這種型別需要謹慎使用。
4. 全域性分組(Global grouping):全部流都分配到bolt的同一個任務。明確地說,是分配給ID最小的那個task。
5. 無分組(None grouping):你不需要關心流是如何分組。目前,無分組等效於隨機分組。但最終,Storm將把無分組的Bolts放到Bolts或Spouts訂閱它們的同一執行緒去執行(如果可能)。
6. 直接分組(Direct grouping):這是一個特別的分組型別。元組生產者決定tuple由哪個元組處理者任務接收。
流式計算整體結構

flume用來獲取資料
Kafka用來臨時儲存資料
Strom用來計算資料
Redis是個記憶體資料庫,用來儲存資料
Storm在綜合專案中
