
win7+cpu+caffe+fcn+vgg16+訓練voc2012資料集
一、 前言
這篇部落格的主要內容是基於caffe的框架,利用全卷積神經網路(FCN)訓練voc資料集。很多人剛接觸FCN的時候很著急的想要製作並訓練自己的資料集,我只想說路要一步一步走,先訓練網上的資料集,一方面可以熟悉FCN構造和引數,一方面可以測試一下你電腦的效能。由於我的電腦配置太低了,這裡我使用的是cpu,以後會補上使用gpu的方法,話不多說直接說步驟。
二、訓練步驟
-
前期工作 要想使用FCN訓練資料集,首先必須安裝caffe框架,如果你還沒安裝的話,可以參考我這篇部落格https://blog.csdn.net/weixin_42795611/article/details/83413951
-
安裝fcn 下載fcn原始碼 fcn原始碼 下載完成後,將其解壓進caffe-windows目錄下,如下圖所示(在這裡我將其重名為了fcn-master)。
 如果你想測試fcn程式碼是否可以使用的話,可以參考這篇部落格https://blog.csdn.net/nichengwuxiao/article/details/79155610,這裡就不在敘述了。
如果你想測試fcn程式碼是否可以使用的話,可以參考這篇部落格https://blog.csdn.net/nichengwuxiao/article/details/79155610,這裡就不在敘述了。 -
資料準備 benchmark資料集下載地址:benchmark資料集下載地址 VOC2012資料集下載地址:VOC2012資料集下載 benchmark資料集是用來存放訓練的資料,VOC2012資料集用來存放測試資料。
-
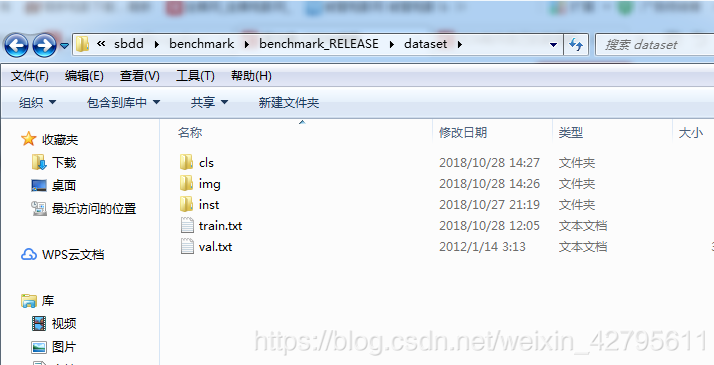
瞭解資料集 (1)進入fcn-master/data目錄,新建sbdd資料夾(如果沒有),將benchmark解壓到sbdd中,進入dataset資料夾,你講看到如圖所示五個檔案,cls是用來存放索引圖(標籤),img用來存放訓練資料(原訓練影象),train.txt用來存放訓練資料的名稱,val.txt用來存放驗證集的名稱。
 (2)進入將VOC資料集fcn-master/data/pascal目錄下,進入VOC2012目錄下,將看到如下圖所示幾個資料夾。JPEGImages用來存放測試資料(原測試影象),SegmentationClass用來存放索引圖(標籤)。
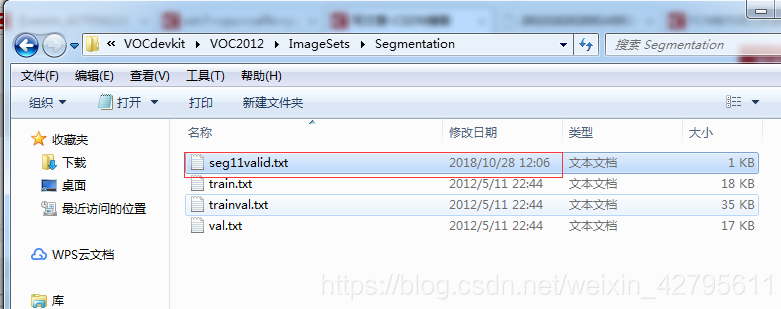
(2)進入將VOC資料集fcn-master/data/pascal目錄下,進入VOC2012目錄下,將看到如下圖所示幾個資料夾。JPEGImages用來存放測試資料(原測試影象),SegmentationClass用來存放索引圖(標籤)。 進入ImageSets\Segmentation目錄下,新建seg11valid.txt,將train.txt裡的內容複製到seg11valid.txt中,用來存放測試資料名稱,為什麼要新建一個資料夾,其實我也不太清楚,網上都是這麼操作的,那我也就這麼操作了,希望以後明白了可以補充下。
進入ImageSets\Segmentation目錄下,新建seg11valid.txt,將train.txt裡的內容複製到seg11valid.txt中,用來存放測試資料名稱,為什麼要新建一個資料夾,其實我也不太清楚,網上都是這麼操作的,那我也就這麼操作了,希望以後明白了可以補充下。
-
修改網路引數 (1)下載VGG16的預訓練模型和VGG_ILSVRC_16_layers_deploy.prototxt並放在FCN原始碼資料夾中的ilsvrc-nets資料夾下
 VGG16的預訓練模型 VGG_ILSVRC_16_layers_deploy.prototxt (2)進入fcn-master目錄下,將所有py檔案全部複製到voc-fcn32s(這裡用voc-fcn32s模型訓練資料),新建snapshot資料夾。這裡面所有的檔案我就不過多的介紹其作用了,今天就是想讓大家熟悉一下訓練流程,等我下一篇部落格訓練自己製作的資料集的時候在詳細介紹。
VGG16的預訓練模型 VGG_ILSVRC_16_layers_deploy.prototxt (2)進入fcn-master目錄下,將所有py檔案全部複製到voc-fcn32s(這裡用voc-fcn32s模型訓練資料),新建snapshot資料夾。這裡面所有的檔案我就不過多的介紹其作用了,今天就是想讓大家熟悉一下訓練流程,等我下一篇部落格訓練自己製作的資料集的時候在詳細介紹。 (3)開啟solve.py檔案
為了避免執行程式時候出現no module named caffe ,在程式碼中包含import caffe的py檔案的第一行加入
(3)開啟solve.py檔案
為了避免執行程式時候出現no module named caffe ,在程式碼中包含import caffe的py檔案的第一行加入
import sys sys.path.append('C:/caffe/caffe-master/python')其中,C:/caffe/caffe-master/python為你下載的caffe原始碼中python資料夾的路徑 (4)修改solve.py檔案
import caffe
import surgery, score
import numpy as np
import os
import sys
sys.path.append('C:/caffe/caffe-master/python')
try:
import setproctitle
setproctitle.setproctitle(os.path.basename(os.getcwd()))
except:
pass
#weights = '../ilsvrc-nets/vgg16-fcn.caffemodel'
vgg_weights = '../ilsvrc-nets/vgg16-fcn.caffemodel'
vgg_proto = '../ilsvrc-nets/VGG_ILSVRC_16_layers_deploy.prototxt'
weights = '../ilsvrc-nets/vgg16-fcn.caffemodel'
# init
#caffe.set_device(int(sys.argv[1])) #我的電腦沒有gpu,如果你電腦有gpu的話,這一行不用註釋
#caffe.set_mode_gpu() #我的電腦沒有gpu,如果你電腦有gpu的話,這一行不用註釋
#solver = caffe.SGDSolver('solver.prototxt')
#solver.net.copy_from(weights)
solver = caffe.SGDSolver('solver.prototxt')
vgg_net=caffe.Net(vgg_proto,vgg_weights,caffe.TRAIN)
surgery.transplant(solver.net,vgg_net)
del vgg_net
# surgeries
interp_layers = [k for k in solver.net.params.keys() if 'up' in k]
surgery.interp(solver.net, interp_layers)
# scoring
val = np.loadtxt('C:/caffe/caffe-master/fcn-master/data/pascal/VOCdevkit/VOC2012/ImageSets/Segmentation/seg11valid.txt', dtype=str) #根據你電腦自己的路徑修改
for _ in range(25):
solver.step(4000)
score.seg_tests(solver, False, val, layer='score')
(5)修改訓練,測試檔案引數 用vs2013開啟train.prototxt檔案,根據自己電腦的路徑程式碼修改為:
param_str: "{\'sbdd_dir\': \'C:/caffe/caffe-master/fcn-master/data/sbdd/benchmark/benchmark_RELEASE/dataset\', \'seed\': 1337, \'split\': \'train\', \'mean\': (104.00699, 116.66877, 122.67892)}"
用vs2013開啟val.prototxt檔案,根據自己電腦的路徑程式碼修改為:
param_str: "{\'voc_dir\': \'C:/caffe/caffe-master/fcn-master/data/pascal/VOCdevkit/VOC2012\', \'seed\': 1337, \'split\': \'seg11valid\', \'mean\': (104.00699, 116.66877, 122.67892)}"
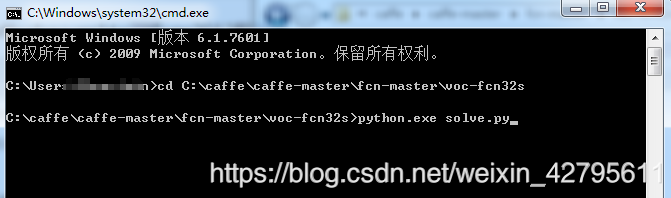
到此所有工作準備完成了,接下來開始訓練資料 (6)訓練資料 開啟cmd命令視窗,將目錄指定到voc-fcn32s路徑下,輸入
python.exe solve.py
如下圖所示:
 當你命令窗口出現如下圖所示時,
當你命令窗口出現如下圖所示時,
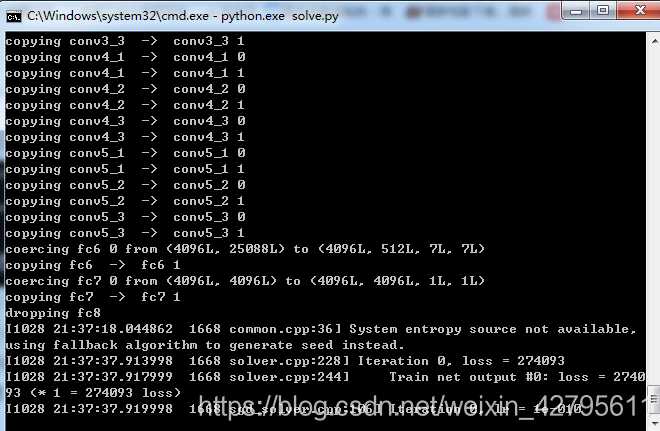 說明你的配置成功了,接下來就是漫長的等待了,由於我的電腦配置太差,跑了一天一夜沒有反應,嘿嘿,所有就沒有在繼續跑下去了
說明你的配置成功了,接下來就是漫長的等待了,由於我的電腦配置太差,跑了一天一夜沒有反應,嘿嘿,所有就沒有在繼續跑下去了
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import sys
sys.path.append('C:/caffe/caffe-master/python')
import caffe
# load image, switch to BGR, subtract mean, and make dims C x H x W for Caffe
im = Image.open('000030.jpg')
in_ = np.array(im, dtype=np.float32)
in_ = in_[:,:,::-1]
in_ -= np.array((104.00698793,116.66876762,122.67891434))
in_ = in_.transpose((2,0,1))
# load net
#net = caffe.Net('voc-fcn8s/deploy.prototxt', 'voc-fcn8s/fcn8s-heavy-pascal.caffemodel', caffe.TEST)
net = caffe.Net('voc-fcn32s/deploy.prototxt', 'voc-fcn32s/snapshot/train_iter_24000.caffemodel', caffe.TEST)
#net = caffe.Net('voc-fcn8s/deploy.prototxt', 'siftflow-fcn32s/train_iter_100000.caffemodel', caffe.TEST)
# shape for input (data blob is N x C x H x W), set data
net.blobs['data'].reshape(1, *in_.shape)
net.blobs['data'].data[...] = in_
# run net and take argmax for prediction
net.forward()
out = net.blobs['score'].data[0].argmax(axis=0)
#plt.imshow(out,cmap='gray');
plt.imshow(out);
plt.axis('off')
plt.savefig('000030_out32.png')
#plt.show()
三、總結
由於我也是剛開始接觸的深度學習,對於零基礎的人來說,要想製作並訓練自己的資料集真的是有一點的難度,還是那句話,路要一步一步的走。這篇部落格主要是介紹FCN資料集,以及熟悉整個訓練的流程,如果以上步驟你都成功的話,說明你已經真正開始踏入深度學習的路途中了,希望我們一起共同進步。如果有任何問題的話,歡迎一起討論。我的郵箱是[email protected]。下一篇部落格我將介紹如何製作自己的資料集。