
CS231n 影象分類筆記
1. 影象分類的任務,就是對於一個給定的影象,在一個固定的分類標籤集合中,預測它屬於的那個分類標籤(或者給出屬於一系列不同標籤的可能性)。
2. 影象是3維陣列,陣列元素是取值範圍從0到255的整數。陣列的尺寸是寬度x高度x3,其中這個3代表的是紅、綠和藍3個顏色通道。也就是是影象陣列包括了:寬度x高度x3這麼多個數字,我們的任務就是把這些上百萬的數字變成一個簡單的標籤,比如“貓”。
3. 資料驅動方法:影象分類不像簡單地排序數字列表那樣,它沒有明顯的硬編碼演算法識別貓或其他類。不再寫具體的分類規則來識別,而是在網上抓取大量貓等種類的圖片資料集,然後訓練機器來分類這些標記圖片,瞭解每個類的視覺外觀,機器會收集所有資料用某種方式總結,然後生成一個模型
4. 影象分類流程:影象分類就是輸入一個元素為畫素值的陣列,然後給它分配一個分類標籤。完整流程如下:
- 輸入:輸入是包含N個影象的集合,每個影象的標籤是K種分類標籤中的一種。這個集合稱為訓練集。
- 學習:這一步的任務是使用訓練集來學習每個類到底長什麼樣。一般該步驟叫做訓練分類器或者學習一個模型。
- 評價:讓分類器來預測它未曾見過的影象的分類標籤,並以此來評價分類器的質量。我們會把分類器預測的標籤和影象真正的分類標籤對比。毫無疑問,分類器預測的分類標籤和影象真正的分類標籤如果一致,那就是好事,這樣的情況越多越好。
5. 如何比較兩張圖片呢?
在本例中,就是需要比較32x32x3的畫素塊。最簡單的方法就是逐個畫素比較,最後將差異值全部加起來。換句話說,就是將兩張圖片先轉化為兩個向量和
,然後計算他們的L1距離 、L2距離。
1. L1距離(曼哈頓距離)
取畫素差絕對值之和,只對影象的每個畫素做對比,對應畫素相減取絕對值,再將這些差值相加就是距離。

distances=np.sum(np.abs(self.Xtr-X[i,:]),axis=1) #使用L1距離:計算每一畫素向量差的絕對值的和 axis=1,對列進行運算2. L2距離(歐幾里得距離)取畫素差平方之和的平方根。
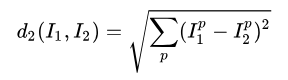
distances=np.sum(np.sqrt(self.Xtr-X[i,:]),axis=1) #使用L2距離:計算每一畫素向量差的平方的和 再求平凡根在L1方形或L2圓形上的點分別與原點是等距的,L1距離取決於你選擇的座標系統,所以如果轉動座標軸時將會改變點之間的L1距離,而對L2無影響。當輸入特徵向量,對於向量中一些特殊意義的值或許L1更適合。但若它只是某個空間中的通用向量,不知道他的含義,L2更自然一些。
6. 超引數(hyperparameter)
k-NN分類器需要設定k值,那麼選擇哪個k值最合適的呢? 我們可以選擇不同的距離函式,比如L1範數和L2範數等,那麼選哪個好? 還有不少選擇我們甚至連考慮都沒有考慮到(比如:點積)。所有這些選擇,被稱為超引數(hyperparameter)。
7. 決不能使用測試集來進行調優。
如果你使用測試集來調優,演算法實際部署後,效能可能會遠低於預期。這種情況,稱之為演算法對測試集過擬合。
如果使用測試集來調優,實際上就是把測試集當做訓練集,由測試集訓練出來的演算法再跑測試集,自然效能看起來會很好。
8. 不用測試集調優的方法? 驗證集(validation set)
其思路是:從訓練集中取出一部分資料用來調優,我們稱之為驗證集(validation set)。訓練集分成訓練集和驗證集。使用驗證集來對所有超引數調優。最後只在測試集上跑一次並報告結果。
9.交叉驗證
交叉驗證。有時候,訓練集數量較小(因此驗證集的數量更小),人們會使用一種被稱為交叉驗證的方法,這種方法更加複雜些。還是用剛才的例子,如果是交叉驗證集,我們就不是取1000個影象,而是將訓練集平均分成5份,其中4份用來訓練,1份用來驗證。然後我們迴圈著取其中4份來訓練,其中1份來驗證,最後取所有5次驗證結果的平均值作為演算法驗證結果。