
xgboost公式推導
基本構成
boosted tree作為有監督學習演算法有幾個重要部分:模型、引數、目標函式、優化演算法 模型
模型指給定輸入x如何去預測輸出y 引數
引數指我們需要學習的東西,線上性模型中,引數指我們的線性係數w 目標函式
目標函式:損失 + 正則,教我們如何去尋找一個比較好的引數
一般的目標函式包含下面兩項: 
Boosted Tree
基學習器:分類和迴歸樹(CART)
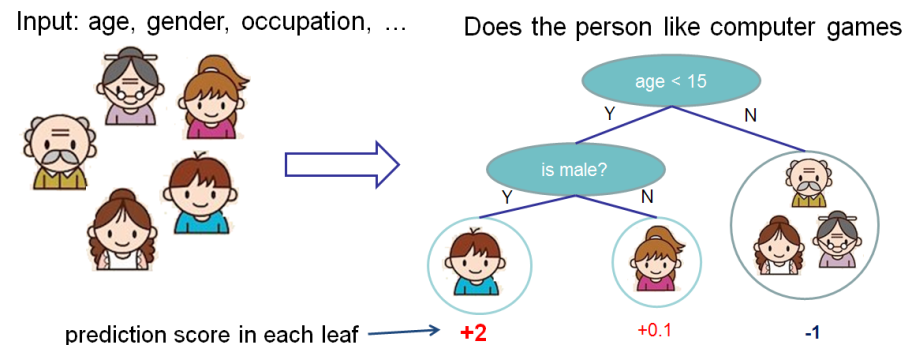
Tree Ensemble構成
一個CART往往過於簡單無法有效地預測,因此一個更加強力的模型叫做tree ensemble。 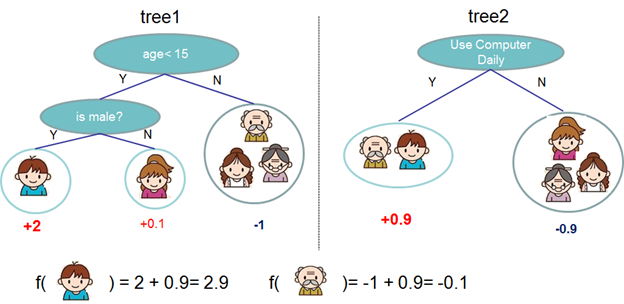
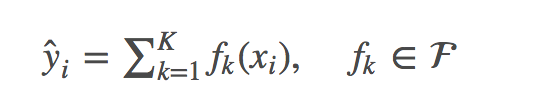
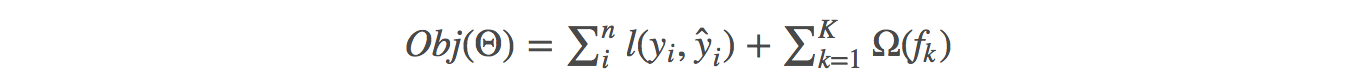
模型學習:additive training
第一部分是訓練誤差,第二部分是每棵樹的複雜度的和。
每一次保留原來的模型不變,加入一個新的函式f到我們的模型中。

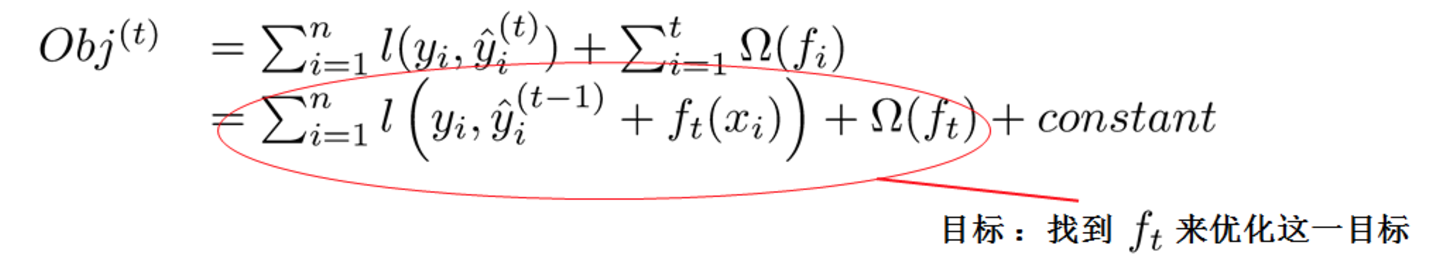 對於l是平方誤差時:
對於l是平方誤差時: 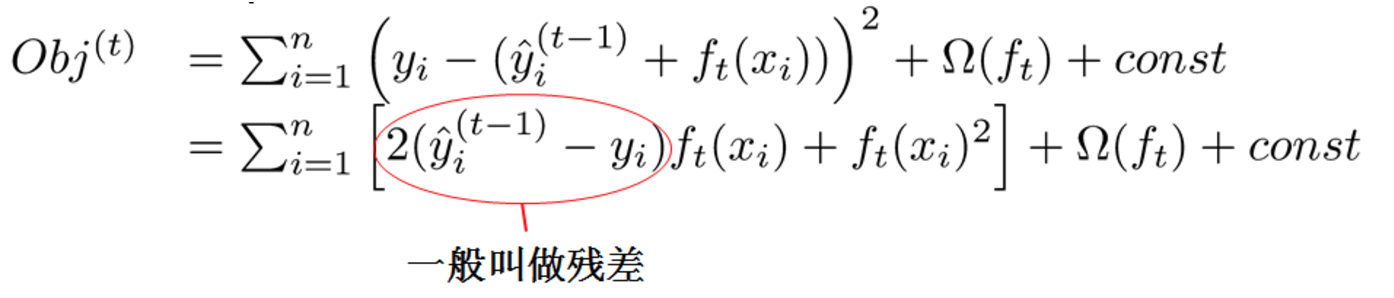 對於l不是平方誤差的情況:
採用如下的泰勒展開近似來定義一個近似的目標函式
對於l不是平方誤差的情況:
採用如下的泰勒展開近似來定義一個近似的目標函式  移除常數項(真實值與上一輪的預測值之差),目標函式只依賴於每個資料點的在誤差函式上的一階導數和二階導數
移除常數項(真實值與上一輪的預測值之差),目標函式只依賴於每個資料點的在誤差函式上的一階導數和二階導數 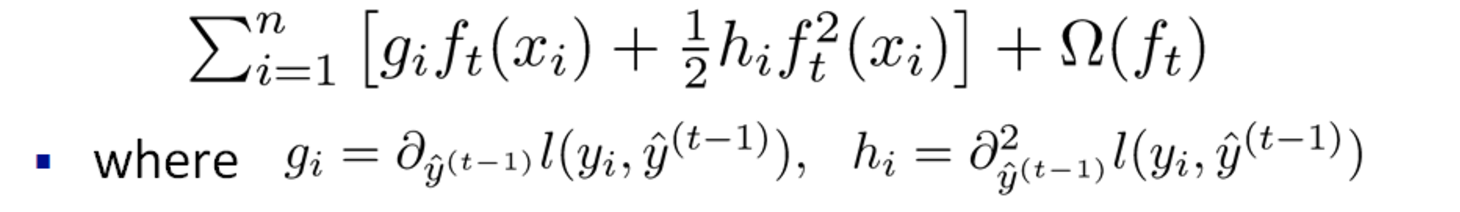
樹的複雜度
以上是目標函式中訓練誤差的部分,接下來定義樹的複雜度。
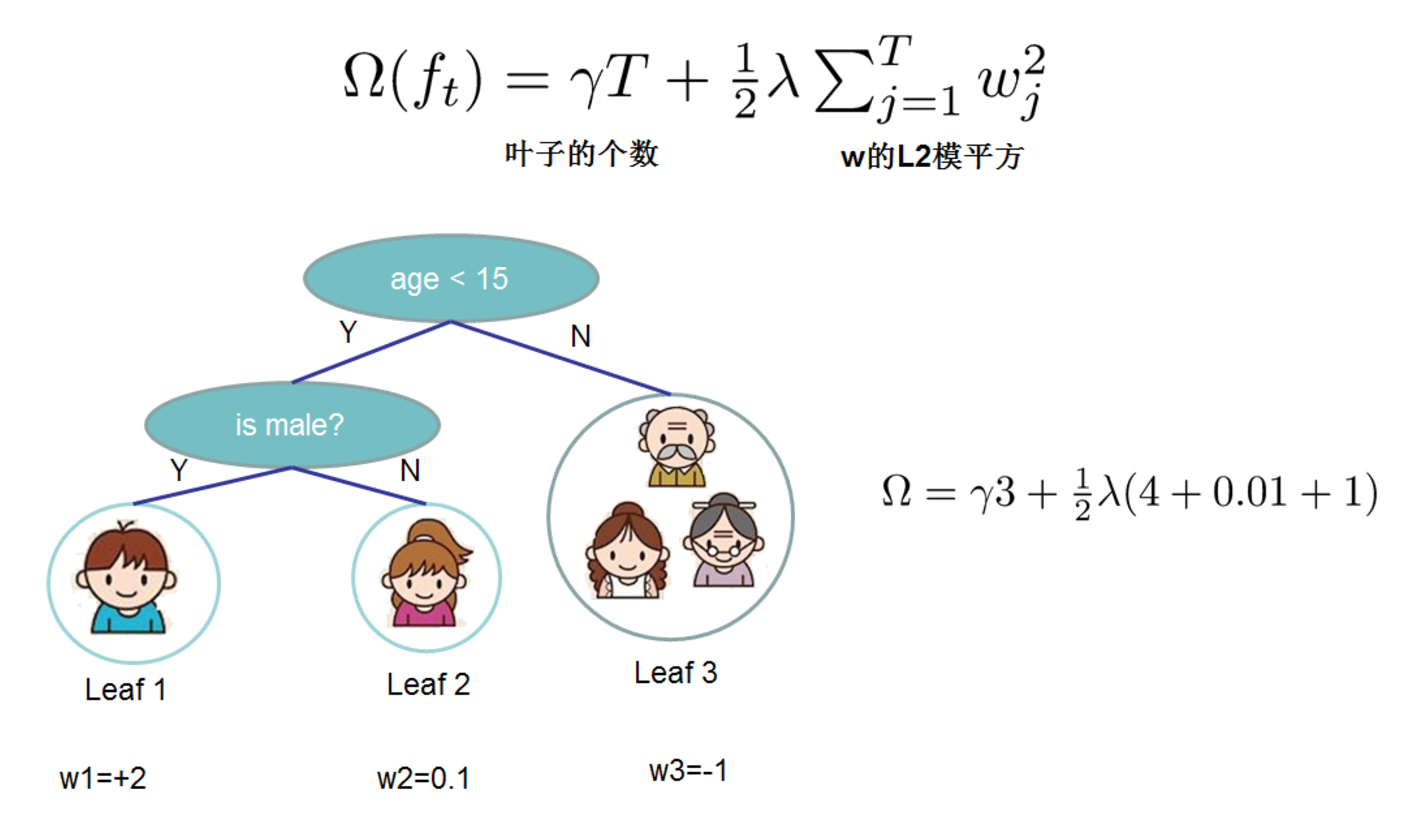
對於f的定義做一下細化,把樹拆分成結構函式q(輸入x輸出葉子節點索引)和葉子權重部分w(輸入葉子節點索引輸出葉子節點分數),結構函式q把輸入對映到葉子的索引號上面去,而w給定了每個索引號對應的葉子分數是什麼。
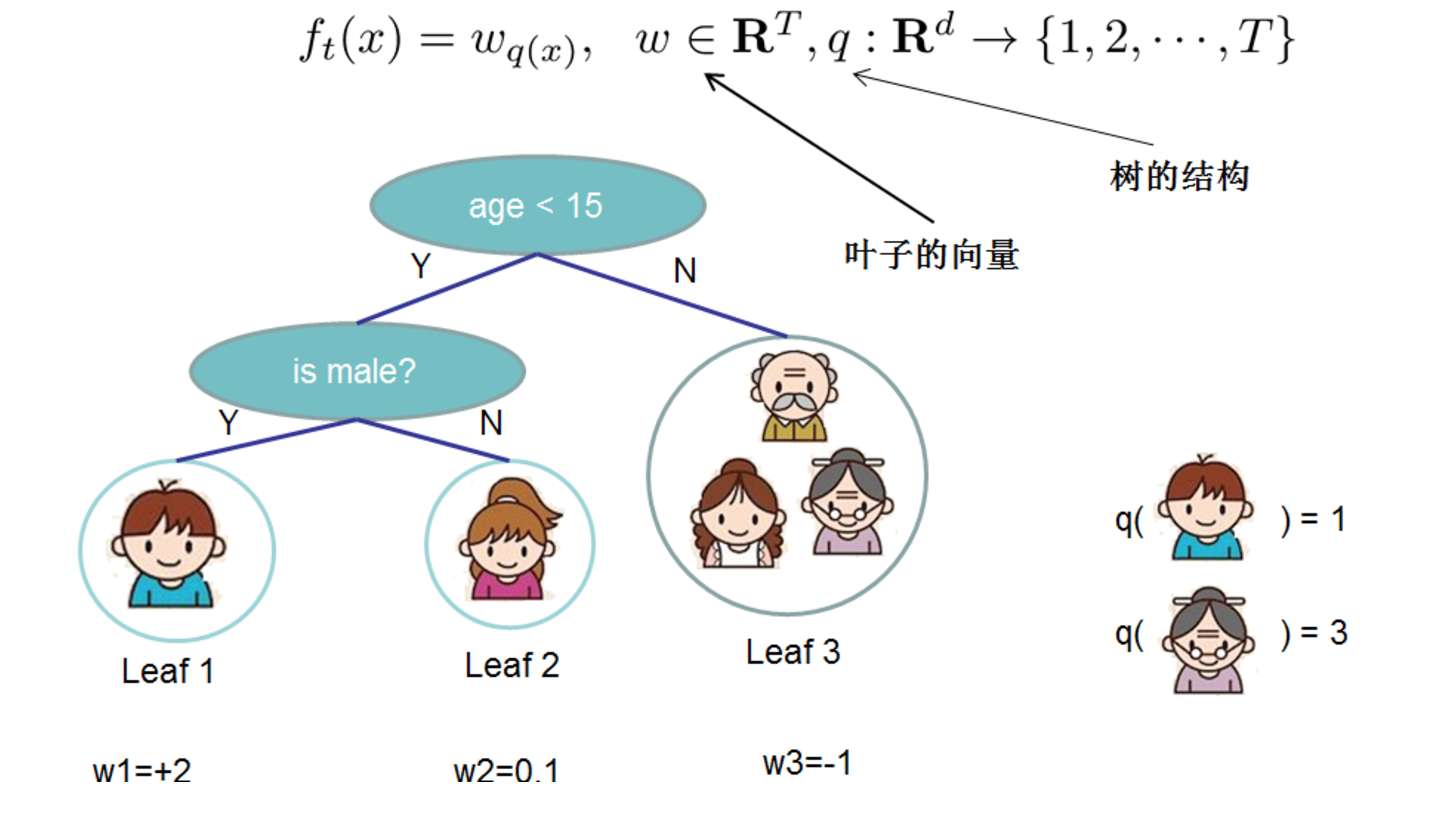
 目標函式改寫:
目標函式改寫: 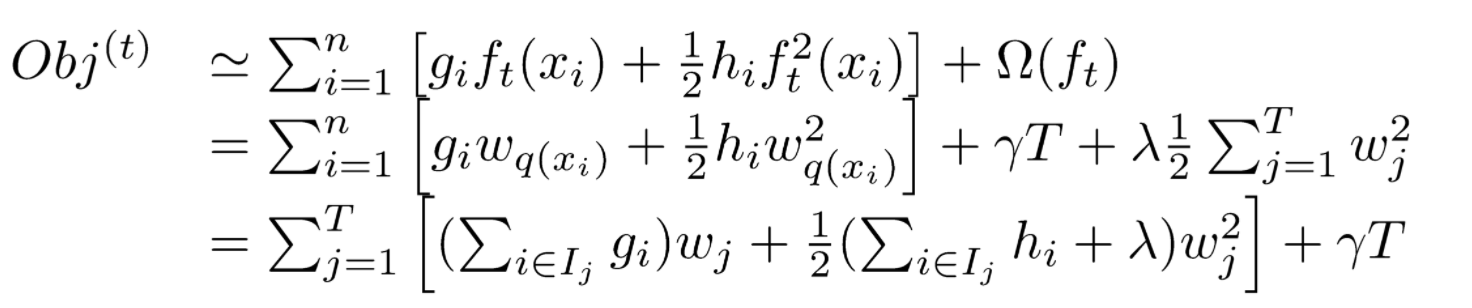 其中I被定義為每個葉子上面樣本集合Ij={i|q(xi)=ji} (每個葉子節點裡面樣本集合);
f(xi)等價於求出w(q(xi))的值(每一個樣本所在葉子索引的分數) ;T為葉子節點數量。
定義Gj(每個葉子節點裡面一階梯度的和)Hj(每個葉子節點裡面二階梯度的和):
其中I被定義為每個葉子上面樣本集合Ij={i|q(xi)=ji} (每個葉子節點裡面樣本集合);
f(xi)等價於求出w(q(xi))的值(每一個樣本所在葉子索引的分數) ;T為葉子節點數量。
定義Gj(每個葉子節點裡面一階梯度的和)Hj(每個葉子節點裡面二階梯度的和): 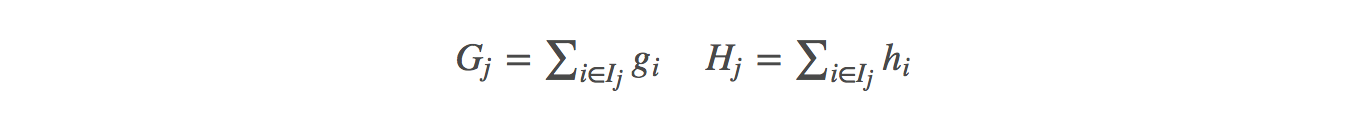 目標函式改寫:
目標函式改寫: 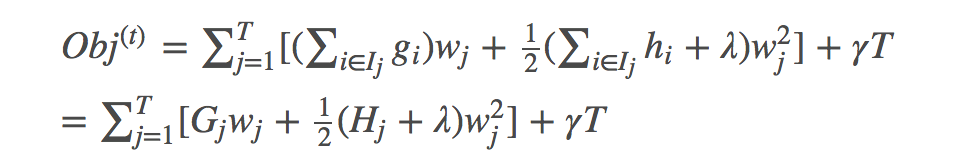 求偏導得出:
求偏導得出: 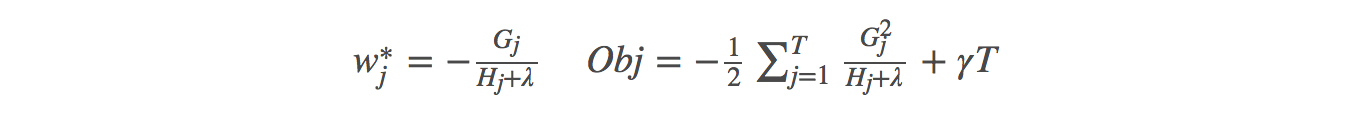 Obj代表了當我們指定一個樹的結構的時候,我們在目標上面最多減少多少,可叫做結構分數(structure score),Obj計算示例:
Obj代表了當我們指定一個樹的結構的時候,我們在目標上面最多減少多少,可叫做結構分數(structure score),Obj計算示例: 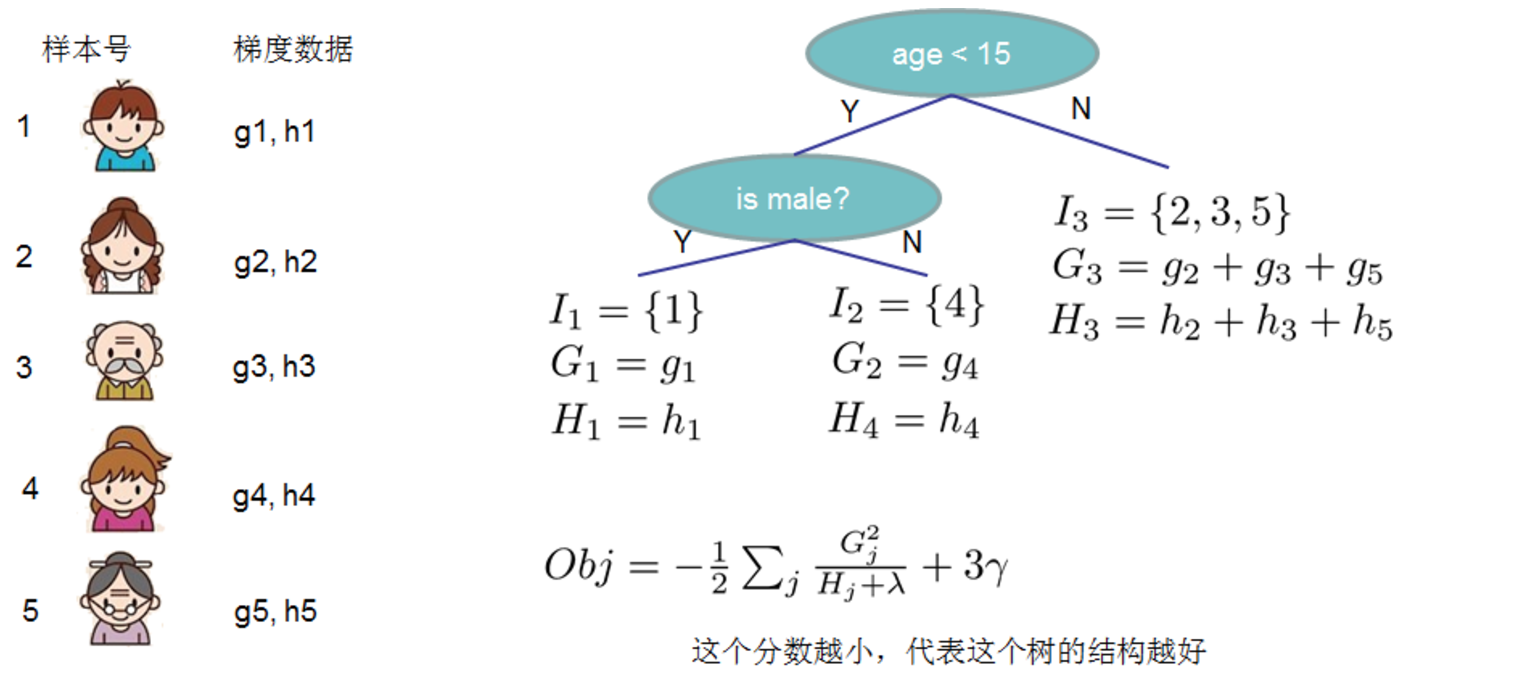
列舉所有不同樹結構的貪心法
exact greedy algorithm 貪心演算法獲取最優切分點
利用這個打分函式來尋找出一個最優結構的樹,加入到我們的模型中,再重複這樣的操作。
常用的方法是貪心法,每一次嘗試去對已有的葉子加入一個分割。對於一個具體的分割方案,計算增益: 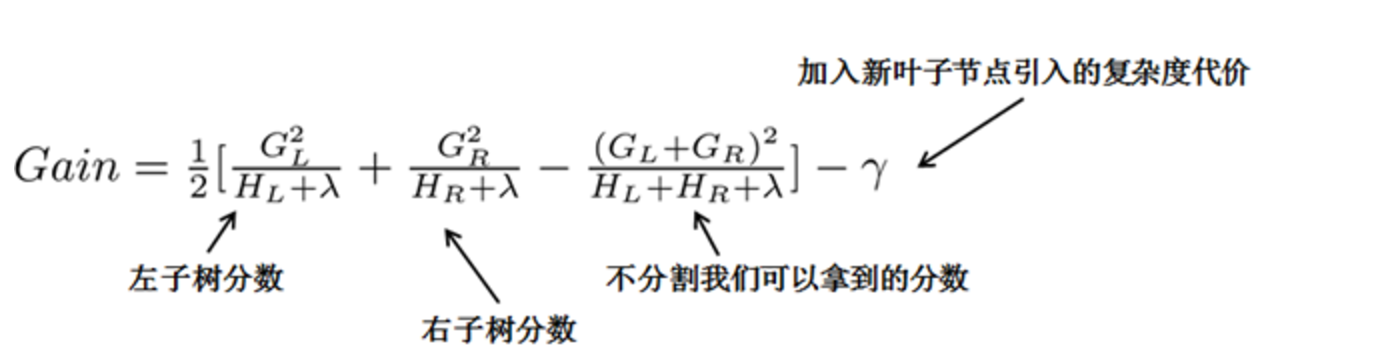
引入新葉子的懲罰項
優化這個目標對應了樹的剪枝, 當引入的分割帶來的增益小於一個閥值的時候,我們可以剪掉這個分割。 這樣根據推導引入了分裂節點的選取計算分數和葉子的懲罰項,替代了迴歸樹的基尼係數與剪枝操作。
當我們正式地推導目標的時候,像計算分數和剪枝這樣的策略都會自然地出現,而不再是一種因為heuristic(啟發式)而進行的操作了。
縮減與列抽樣
縮減,每一個樹生成結果乘以一個步長係數 防止過擬合 列取樣樣 類似隨機森林每個樹特徵抽樣 防止過擬合
劃分點查詢演算法
貪心演算法
演算法1 exact greedy algorithm—貪心演算法獲取最優切分點 



引數
自定義損失函式
- 損失函式舉例
- 針對Logistic loss求一階二階梯度
- 程式碼示例

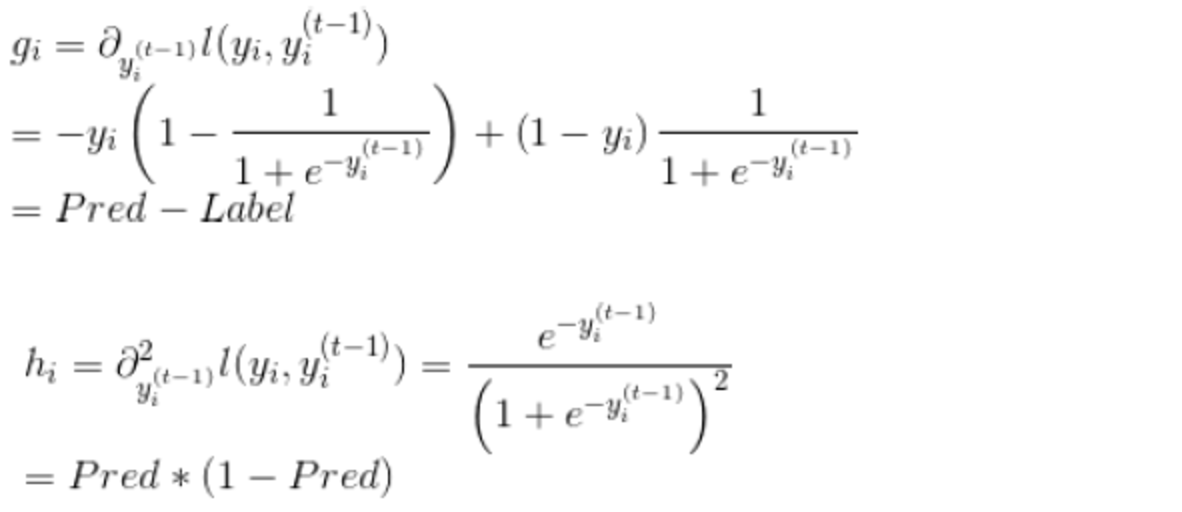
-
#!/usr/bin/python -
import numpy as np -
import xgboost as xgb -
### -
# 定製損失函式 -
print ('開始執行示例,使用自定義的目標函式') -
dtrain = xgb.DMatrix('../data/agaricus.txt.train') -
dtest = xgb.DMatrix('../data/agaricus.txt.test') -
param = {'max_depth': 2, 'eta': 1, 'silent': 1} -
watchlist = [(dtest, 'eval'), (dtrain, 'train')] -
num_round = 2 -
# 使用者定義目標函式,給出預測,返回梯度和二階梯度 -
def logregobj(preds, dtrain): -
labels = dtrain.get_label() -
preds = 1.0 / (1.0 + np.exp(-preds)) -
grad = preds - labels -
hess = preds * (1.0-preds) -
return grad, hess -
# 使用者定義的評估函式,返回一個對指標名稱和結果 -
# 當你做定製的損失函式,預設的預測價值可能使評價指標不正常工作,所以要自定義評估函式 -
def evalerror(preds, dtrain): -
labels = dtrain.get_label() -
return 'error', float(sum(labels != (preds > 0.0))) / len(labels) -
# 訓練定製的目標 -
bst = xgb.train(param, dtrain, num_round, watchlist, logregobj, evalerror)
Xgboost引數
官方 常用引數: 一般引數: booster[default=gbtree]選擇基分類器 gbtree、gblinear 樹或線性分類器 silent [default=0] 是否輸出詳細資訊 0不輸出 1輸出 nthread [default to maximum number of threads available if not set]執行緒數預設最大 Tree Booster引數: 1. eta [default=0.3]:shrinkage引數,用於更新葉子節點權重時,乘以該係數,避免步長過大。引數值越大,越可能無法收斂。把學習率 eta 設定的小一些,小學習率可以使得後面的學習更加仔細。 2. min_child_weight [default=1]:這個引數預設是 1,是每個葉子裡面 h 的和至少是多少,對正負樣本不均衡時的 0-1 分類而言,假設 h 在 0.01 附近,min_child_weight 為 1 意味著葉子節點中最少需要包含 100 個樣本。這個引數非常影響結果,控制葉子節點中二階導的和的最小值,該引數值越小,越容易 overfitting。 3. max_depth [default=6]: 每顆樹的最大深度,樹高越深,越容易過擬合。 4. gamma [default=0]:在樹的葉子節點上作進一步分割槽所需的最小損失減少。越大,演算法越保守。[0,∞] 5. max_delta_step [default=0]:這個引數在更新步驟中起作用,如果取0表示沒有約束,如果取正值則使得更新步驟更加保守。可以防止做太大的更新步子,使更新更加平緩。 通常,這個引數是不需要的,但它可能有助於邏輯迴歸時,類是非常不平衡。設定它的值為1-10可能有助於控制更新。 6. subsample [default=1]:樣本隨機取樣,較低的值使得演算法更加保守,防止過擬合,但是太小的值也會造成欠擬合。 7. colsample_bytree [default=1]:列取樣,對每棵樹的生成用的特徵進行列取樣.一般設定為: 0.5-1 8. lambda [default=1]:控制模型複雜度的權重值的L2正則化項引數,引數越大,模型越不容易過擬合。 9. alpha [default=0]:控制模型複雜程度的權重值的 L1 正則項引數,引數值越大,模型越不容易過擬合。 10. scale_pos_weight [default=1]如果取值大於0的話,在類別樣本不平衡的情況下有助於快速收斂。 11. tree_method[default=’auto’]可選 {‘auto’, ‘exact’, ‘approx’} 貪心演算法(小資料集)/近似演算法(大資料集) 學習任務引數: objective [ default=reg:linear ]定義最小化損失函式型別 最常用的值有: binary:logistic 二分類的邏輯迴歸,返回預測的概率(不是類別)。 multi:softmax 使用softmax的多分類器,返回預測的類別(不是概率)。 在這種情況下,你還需要多設一個引數:num_class(類別數目)。 multi:softprob 和multi:softmax引數一樣,但是返回的是每個資料屬於各個類別的概率。 seed [ default=0 ]隨機種子 eval_metric[根據目標objective預設] 對於有效資料的度量方法。 對於迴歸問題,預設值是rmse,對於分類問題,預設值是error。 典型值有: rmse 均方根誤差( ∑Ni=1ϵ2N‾‾‾‾‾‾‾√ ) mae 平均絕對誤差( ∑Ni=1|ϵ|N ) logloss 負對數似然函式值 error 二分類錯誤率(閾值為0.5) merror 多分類錯誤率 mlogloss 多分類logloss損失函式 auc 曲線下面積 命令列引數: num_round 迭代次數/樹的個數
GBDT與XGBoost區別
- 目標函式通過二階泰勒展開式做近似。傳統GBDT在優化時只用到一階導數資訊,xgboost則對代價函式進行了二階泰勒展開,同時用到了一階和二階導數。注:支援自定義代價函式,只要函式可一階和二階求導。
- 定義了樹的複雜度,即xgboost在代價函式里加入了正則項,用於控制模型的複雜度,正則項裡包含了樹的葉子節點個數、每個葉子節點上輸出的score的L2模的平方和。代替了剪枝。
- 分裂結點處通過結構打分和分割損失動態生長。結構分數代替了迴歸樹的誤差平方和。
- 分裂結點特徵分割點選取使用了近似演算法-可並行的近似直方圖演算法。樹節點在進行分裂時,我們需要計算每個特徵的每個分割點對應的增益,即用貪心法列舉所有可能的分割點。當資料無法一次載入記憶體或者在分散式情況下,貪心演算法效率就會變得很低,所以xgboost還提出了一種可並行的近似直方圖演算法,用於高效地生成候選的分割點。用於加速和減小記憶體消耗。
- 可以處理稀疏、缺失資料(節點分裂演算法能自動利用特徵的稀疏性),可以學習出它的分裂方向,加快稀疏計算速度。
- 列抽樣(column subsampling)[傳統GBDT沒有],Shrinkage(縮減),相當於學習速率(xgboost中的eta)[傳統GBDT也有]
- 支援並行化處理。xgboost的並行是在特徵粒度上的,在訓練之前,預先對特徵進行了排序,然後儲存為block結構,後面的迭代中重複地使用這個結構,大大減小計算量。在進行節點的分裂時,需要計算每個特徵的增益,最終選增益最大的那個特徵去做分裂,那麼各個特徵的增益計算就可以開多執行緒進行,即在不同的特徵屬性上採用多執行緒並行方式尋找最佳分割點。
- 傳統GBDT以CART作為基分類器,xgboost還支援線性分類器,這個時候xgboost相當於帶L1和L2正則化項的邏輯斯蒂迴歸(分類問題)或者線性迴歸(迴歸問題)。通過booster [default=gbtree]設定引數:gbtree: tree-based models/gblinear: linear models。