
深入瞭解HBASE架構
平和的心
Posts - 534 Articles - 0 Comments - 56
閱讀目錄
dd by zhj: 最近的工作需要跟HBase打交道,所以花時間把《HBase權威指南》粗略看了一遍,感覺不過癮,又從網上找了幾篇經典文章。
下面這篇就是很經典的文章,對HBase的架構進行了比較詳細的描述。我自己也進行了簡單的總結,簡單的說,HBase使用的是LSM(
Log-Structured Merge tree)--日誌結構的合併樹做為儲存方式,這種儲存方式是很多NoSQL資料庫都在使用的,它的主要特點是:
1. 寫:完全的記憶體操作,速度非常快。具體來說,是寫入WAL(write ahead log)日誌和MemStore記憶體,完成後給客戶端響應。
WAL相當於MySQL的binlog。當MemStore達到一定大小後,將其flush到磁碟。
2. 讀:將磁碟中的資料與MemStore中的資料進行合併後
與B+樹相比,LSM提高了寫入效能,而且讀取效能並沒有減低多少
HBase由三個部分,如下
1. HMaster
對Region進行負載均衡,分配到合適的HRegionServer
2. ZooKeeper
選舉HMaster,對HMaster,HRegionServer進行心跳檢測(貌似是這些機器節點向ZooKeeper上報心跳)
3. HRegionServer
資料庫的分片,HRegionServer上的組成部分如下
Region:HBase中的資料都是按row-key進行排序的,對這些按row-key排序的資料進行水平切分,每一片稱為一個Region,它有startkey和endkey,Region的大小可以配置,一臺RegionServer中可以放多個Region
CF:列族。一個列族中的所有列儲存在相同的HFile檔案中
HFile:HFile就是Hadoop磁碟檔案,一個列族中的資料儲存在一個或多個HFile中,這些HFile是對列族的資料進行水平切分後得到的。
MemStore:HFile在記憶體中的體現。當我們update/delete/create時,會先寫MemStore,寫完後就給客戶端response了,當Memstore達到一定大
小後,會將其寫入磁碟,儲存為一個新的HFile。HBase後臺會對多個HFile檔案進行merge,合併成一個大的HFile
一.Hbase 架構的元件
- Region Server:提供資料的讀寫服務,當客戶端訪問資料時,直接和Region Server通訊。
- HBase Master:Region的分配,.DDL操作(建立表,刪除表)
- Zookeeper:是HDFS的一部分,維護一個活躍的叢集狀態
Hadoop DataNode儲存著Region Server 管理的資料,所有的Hbase資料儲存在HDFS檔案系統中,Region Servers在HDFS DataNode中是可配置的,並使資料儲存靠近在它所需要的地方,就近服務,當王HBASE寫資料時時Local的,但是當一個region 被移動之後,Hbase的資料就不是Local的,除非做了壓縮(compaction)操作。NameNode維護物理資料塊的元資料資訊。
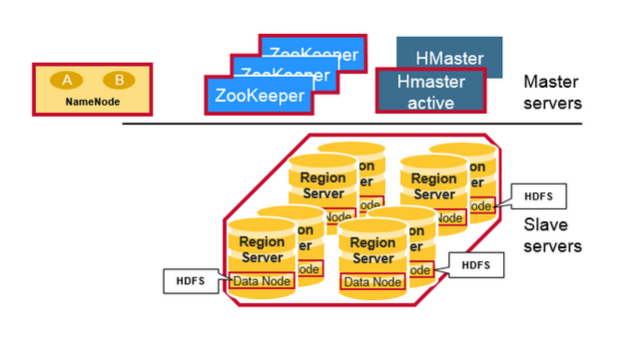
二.Regions
HBase Tables 通過行健的範圍(row key range)被水平切分成多個Region, 一個Region包含了所有的,在Region開始鍵和結束之內的行,Regions被分配到叢集的節點上,成為 Region Servers,提供資料的讀寫服務,一個region server可以服務1000 個Region。
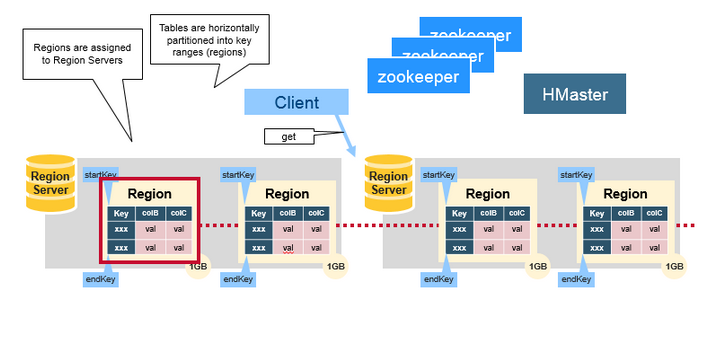
三.HBase HMaster
分配Region,DDL操作(建立表, 刪除表)
協調各個Reion Server :
-在啟動時分配Region、在恢復或是負載均衡時重新分配Region。
-監控所有叢集當中的Region Server例項,從ZooKeeper中監聽通知。
管理功能:
-提供建立、刪除、更新表的介面。
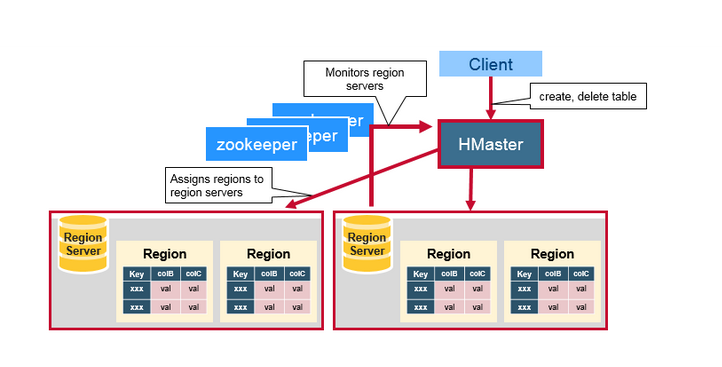
四.ZooKeeper:協調器
Hbase使用Zookeeper作為分散式協調服務,來維護叢集中的Server狀態,ZooKeeper維護著哪些Server是活躍或是可用的。提供Server 失敗時的通知。Zookeeper使用一致性機制來保證公共的共享狀態,注意,需要使用奇數的三臺或是五臺機器,保證一致。
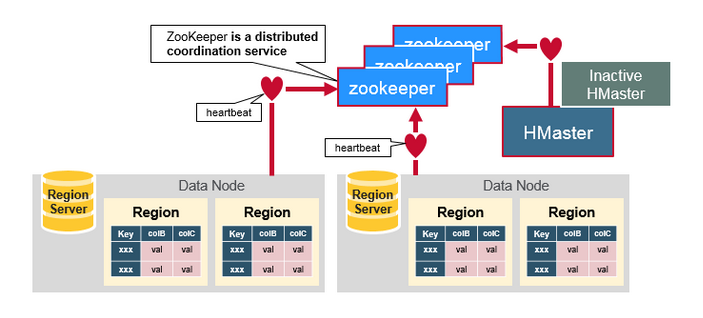
五、元件之間如何工作
Zookeeper一般在分散式系統中的成員之間協調共享的狀態資訊,Region Server和活躍的HMaster通過會話連線到Zookeeper,ZooKeeper維護短暫的階段,通過心跳機制用於活躍的會話。
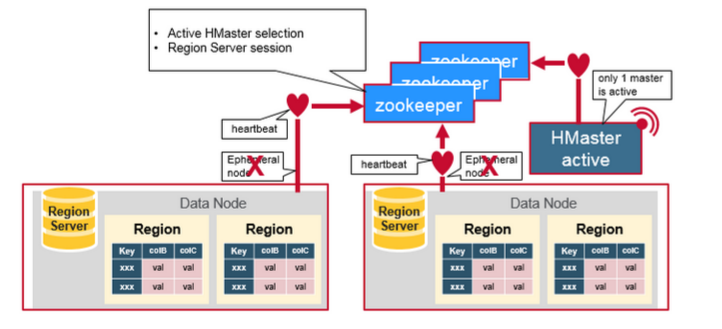
每個Region Server建立一個短暫的節點,HMaster監控這些節點發現可用的Region Server,同時HMaster 也監控這些節點的伺服器故障。HMaster 通過撞見一個臨時的節點,Zookeeper決定其中一個HMaster作為活躍的。活躍的HMaster 給ZooKeeper傳送心跳資訊,不活躍的HMaster在活躍的HMaster出現故障時,接受通知。
如果一個Region Server或是一個活躍的HMaster在傳送心跳資訊時失敗或是出現了故障,則會話過期,相應的臨時節點將被刪除,監聽器將因這些刪除的節點更新通知資訊,活躍的HMaster將監聽Region Server,並且將會恢復出現故障的Region Server,不活躍的HMaster 監聽活躍的HMaster故障,如果一個活躍的HMaster出現故障,則不活躍的HMaster將會變得活躍。
六 Hbase 的首次讀與寫
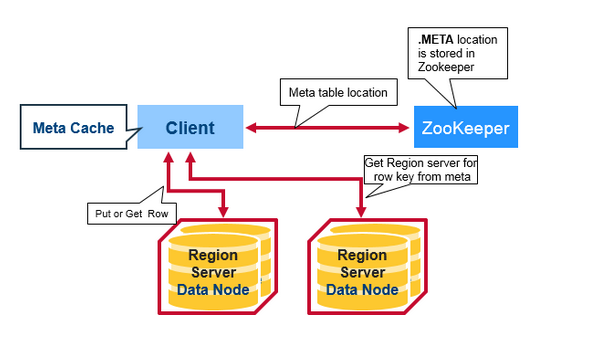
有一個特殊的Hbase 目錄表叫做Meta表,它擁有Region 在叢集中的位置資訊,ZooKeeper儲存著Meta表的位置。
如下就是客戶端首次讀寫Hbase 所發生的事情:
1.客戶端從Zookeeper的Meta表中獲取Region Server。
2.客戶端將查詢 .META.伺服器,獲取它想訪問的相對應的Region Server的行健。客戶端將快取這些資訊以及META 表的位置。
3.護額端將從相應的Region Server獲取行。
如果再次讀取,客戶端將使用快取來獲取META 的位置及之前的行健。這樣時間久了,客戶端不需要查詢META表,除非Region 移動所導致的丟失,這樣的話,則將會重新查詢更新快取。
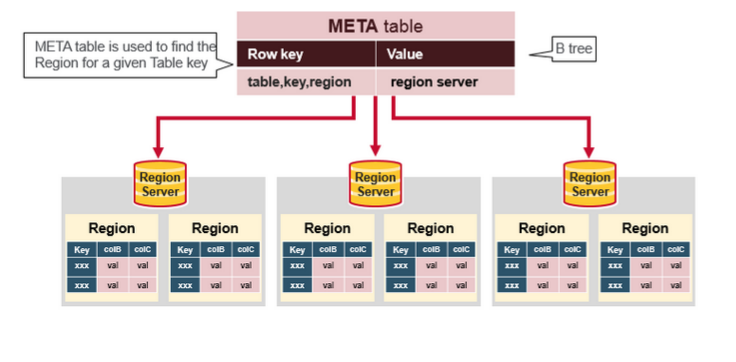
七 Hbase META表
META 表叢集中所有Region的列表
.META. 表像是一個B樹
.META. 表結構為:
- Key: region start key,region id
- Values: RegionServer
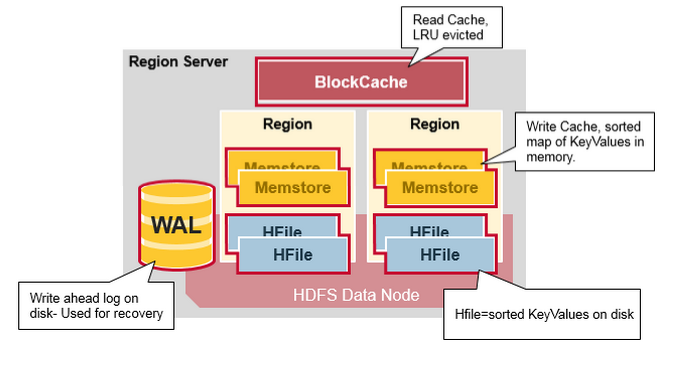
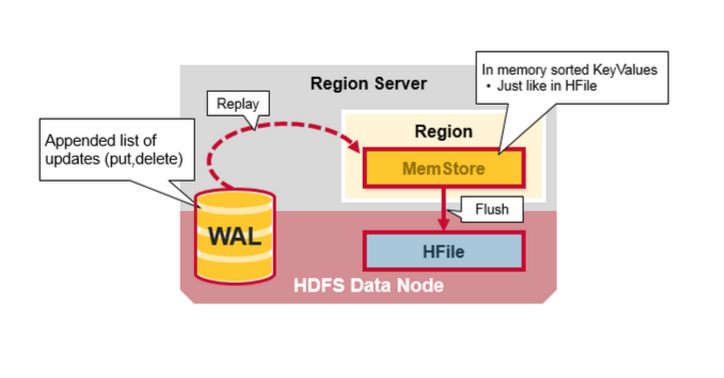
八 Region Server 的元件
Region Server 執行在HDFS DataNode上,並有如下元件:
WAL:Write Ahead Log 提前寫日誌是一個分散式檔案系統上的檔案,WAL儲存沒有持久化的新資料,用於故障恢復,類似Oracle 的Redo Log。
BlockCache:讀快取,它把頻繁讀取的資料放入記憶體中,採用LRU
MemStore:寫快取,儲存來沒有來得及寫入磁碟的新資料,每一個region的每一個列族有一個MemStore
Hfiles :儲存行,作為鍵值對,在硬碟上。
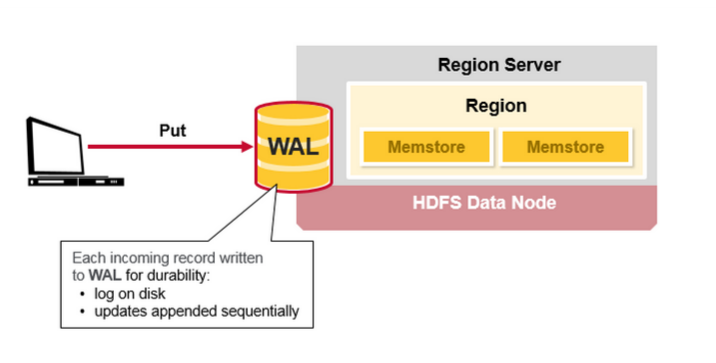
Hbase 寫步驟1:
當客戶端提交一個Put 請求,第一步是把資料寫入WAL:
-編輯到在磁碟上的WAL的檔案,新增到WAL檔案的末尾
-WAL用於宕機恢復
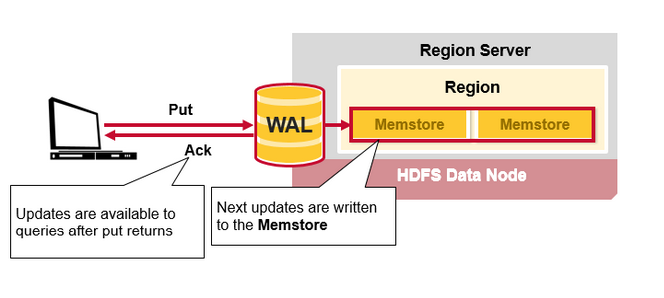
Hbase 寫步驟2
一旦資料寫入WAL,將會把它放到MemStore裡,然後將返回一個ACk給客戶端
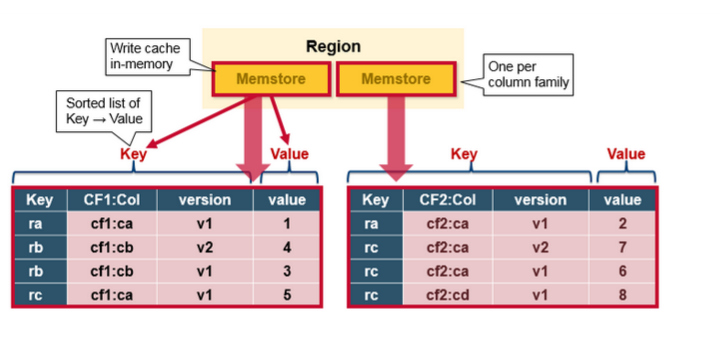
MemStore
MemStore 儲存以鍵值對的方式更新記憶體,和儲存在HFile是一樣的。每一個列族就有一個MemStore ,以每個列族順序的更新。
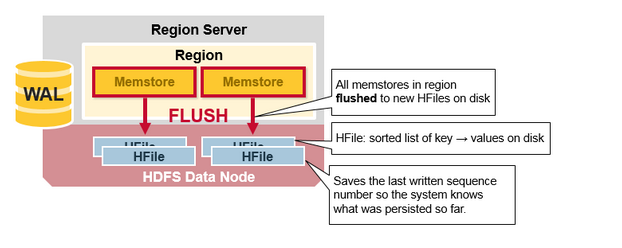
HBase Region 重新整理(Flush)
當MemStore 積累到足夠的資料,則整個排序後的集合被寫到HDFS的新的HFile中,每個列族使用多個HFiles,列族包含真實的單元格,或者是鍵值對的例項,隨著KeyValue鍵值對在MemStores中編輯排序後,作為檔案重新整理到磁碟上。
注意列族是有數量限制的,每一個列族有一個MemStore,當MemStore滿了,則進行重新整理。它也會保持最後一次寫的序列號,這讓系統知道直到現在都有什麼已經被持久化了。
最高的序列號作為一個meta field 儲存在HFile中,來顯示持久化在哪裡結束,在哪裡繼續。當一個region 啟動後,讀取序列號,最高的則作為新編輯的序列號。
HBase HFile
資料儲存在HFile,HFile 儲存鍵值,當MemStore 積累到足夠的資料,整個排序的鍵值集合會寫入到HDFS中新的HFile 中。這是一個順序的寫,非常快,能避免移動磁頭。
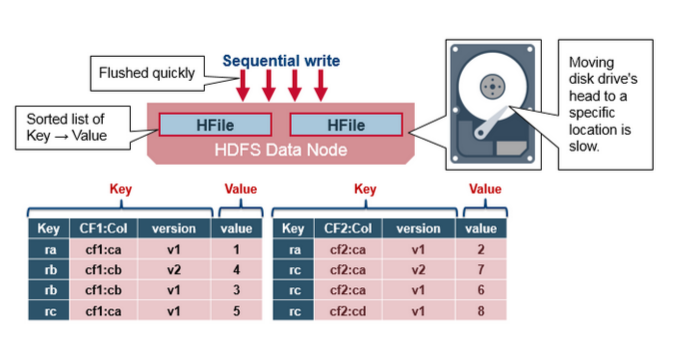
HFile 的結構
HFile 包含一個多層的索引,這樣不必讀取整個檔案就能查詢到資料,多層索引像一個B+樹。
- 鍵值對以升序儲存
- 在64K的塊中,索引通過行健指向鍵值對的資料。
- 每個塊有自己的葉子索引
- 每個塊的最後的鍵被放入到一箇中間索引中。
- 根索引指向中間索引。
trailer (追蹤器)指向 meta的塊,並在持久化到檔案的最後時被寫入。trailer 擁有 bloom過濾器的資訊以及時間範圍(time range)的資訊。Bloom 過濾器幫助跳過那些不含行健的檔案,時間範圍(time range)則跳過那些不包含在時間範圍內的檔案。
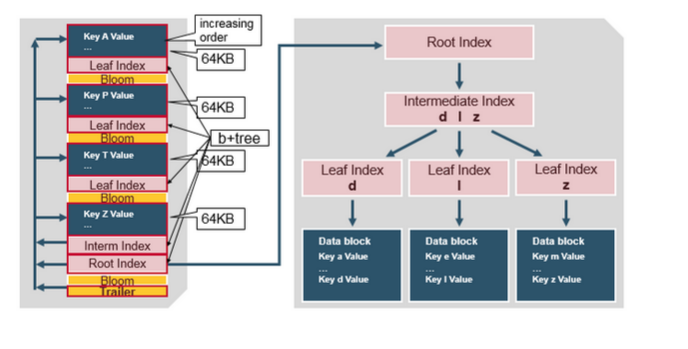
HFile Index
索引是在HFile 開啟並放入記憶體中時被載入的,這允許在單個磁碟上執行查詢。
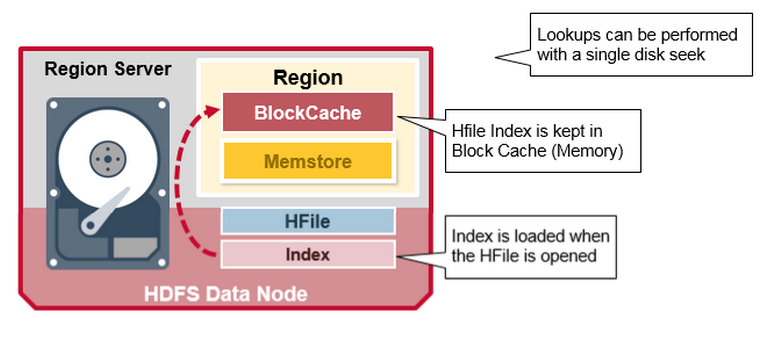
HBase 讀合併
一個行的鍵值單元格可以被儲存在很多地方,行單元格已經被儲存到HFile中、在MemStore最近被更新的單元格、在Block cache最佳被讀取的單元格,所以當你讀取一行資料時,系統怎麼能把相對應的單元格內容返回呢?一次讀把block cache, MemStore, and HFiles中的鍵值合併的步驟如下:
- 首先,掃描器(scanner )在讀快取的Block cache尋找行單元格,最近讀取的鍵值快取在Block cache中,當記憶體需要時剛使用過的(Least Recently Used )將會被丟棄。
- 接下來,掃描器(scanner)將在MemStore中查詢,以及在記憶體中最近被寫入的寫快取。
- 如果掃描器(scanner)在MemStore 和Block Cache沒有找到所有的資料,則HBase 將使用 Block Cache的索引以及bloom過濾器把含有目標的行單元格所在的HFiles 載入到記憶體中。
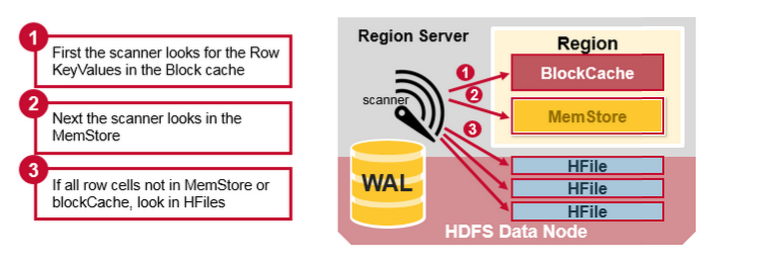
每個MemStore有許多HFiles 檔案,這樣對一個讀取操作來說,多個檔案將不得不被多次檢查,勢必會影響效能,這種現象叫做讀放大(read amplification)。
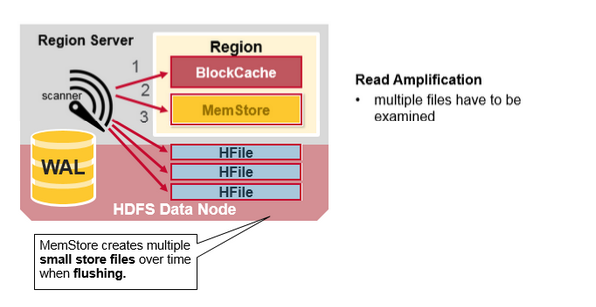
HBase 輔壓縮(minor compaction)
HBase將會自動把小HFiles 檔案重寫為大的HFiles 檔案,這個過程叫做minor compaction。
輔助壓縮減少檔案的數量,並執行合併排序。
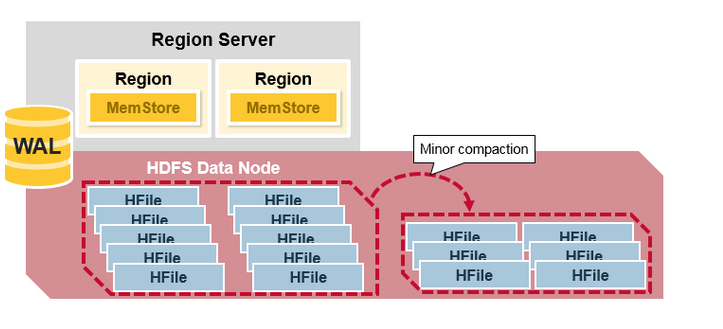
HBase 主壓縮(Major Compaction)
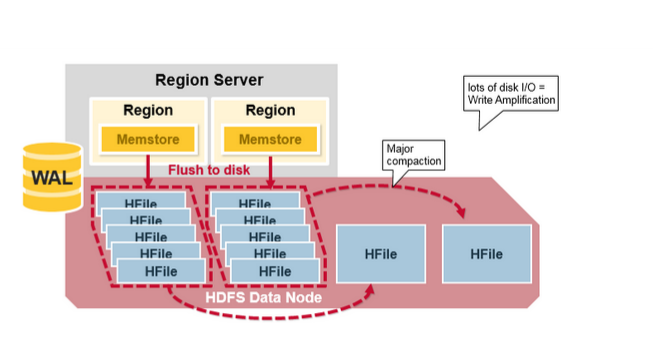
主壓縮將會合並和重寫一個region 的所有HFile 檔案,根據每個列族寫一個HFile 檔案,並在這個過程中,刪除deleted 和expired 的單元格,這將提高讀效能。
然而因為主壓縮重寫了所有的檔案,這個過程中將會導致大量的磁碟IO操作以及網路擁堵。我們把這個過程叫做寫放大(write amplification)。
Region = 臨近的鍵
- 一個表將被水平分割為一個或多個Region,一個Region包含相鄰的起始鍵和結束鍵之間的行的排序後的區域。
- 每個region預設1GB
- 一個region的表通過Region Server 向客戶端提供服務
- 一個region server可以服務1000 個region
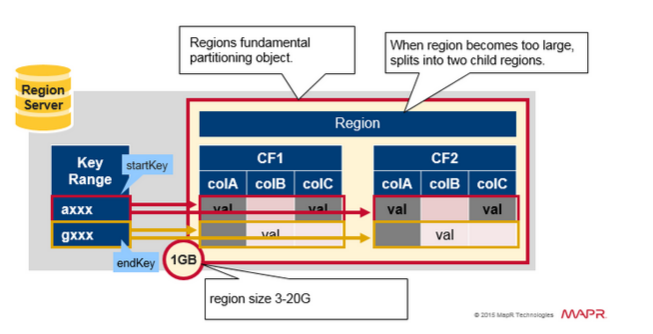
Region 分裂
初始時一個table在一個region 中,當一個region 變大之後,將會被分裂為2個子region,每個子Region 代表一半的原始Region,在一個相同的 Region server中並行開啟。
然後把分裂報告給HMaster。因為需要負載均衡的緣故,HMaster 可能會排程新的Region移動到其他的Server上。
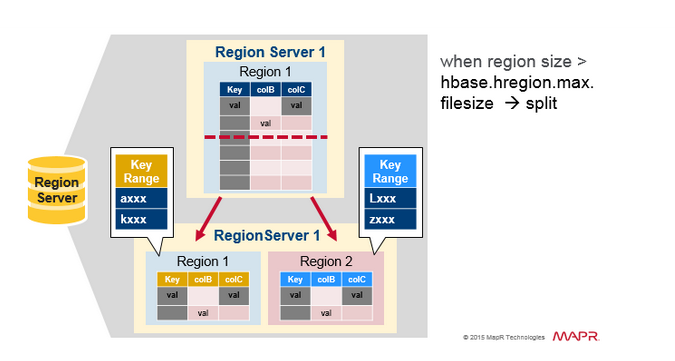
讀負載均衡(Read Load Balancing)
分裂一開始發生在相同的region server上,但是由於負載均衡的原因。HMaster 可能會排程新的Region被移動到其他的伺服器上。
導致的結果是新的Region Server 提供資料的服務需要讀取遠端的HDFS 節點。直到主壓縮把資料檔案移動到Regions server本地節點上,Hbase資料當寫入時是本地的,
但是當一個region 移動(諸如負載均衡或是恢復操作等),它將不會是本地的,直到做了主壓縮的操作(major compaction.)
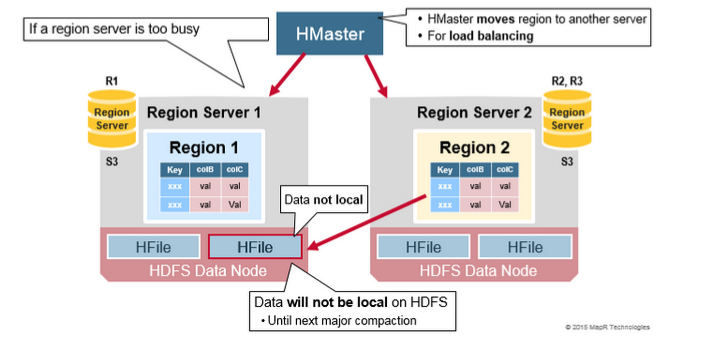
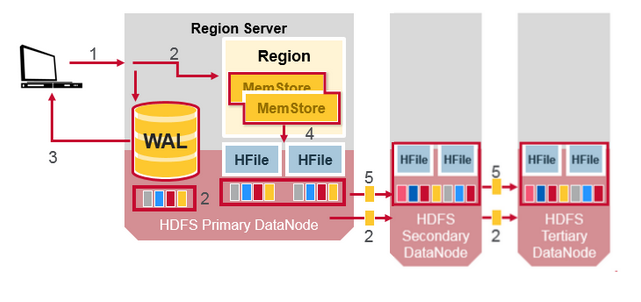
HDFS資料複製
所有的讀寫操作發生在主節點上,HDFS 複製WAL和HFile 塊,HFile複製是自動發生的,HBase 依賴HDFS提供資料的安全,
當資料寫入HDFS,本地化地寫入一個拷貝,然後複製到第二個節點,然後複製到第三個節點。
WAL 檔案和 HFile檔案通過磁碟和複製進行持久化,那麼HBase怎麼恢復還沒來得及進行持久化到HFile中的MemStore更新呢?
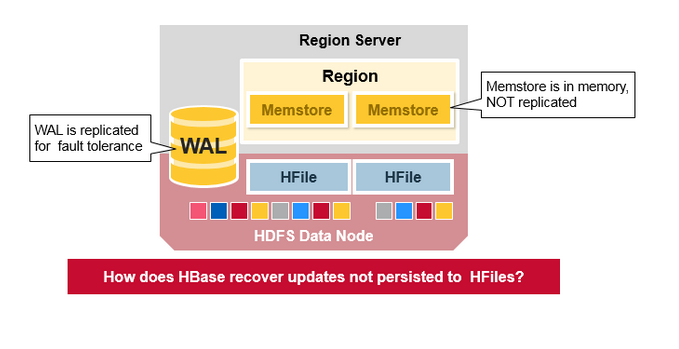
HBase 故障恢復
當一個RegionServer 掛掉了,壞掉的Region 不可用直到發現和恢復的步驟發生。Zookeeper 決定節點的失敗,然後失去region server的心跳。
然後HMaster 將會被通知Region Server已經掛掉了。
當HMaster檢查到region server已經掛掉後,HMaster 將會把故障Server上的Region重寫分配到活躍的Region servers上。
為了恢復宕掉的region server,memstore 將不會重新整理到磁碟上,HMaster 分裂屬於region server 的WAL 到單獨的檔案,
然後儲存到新的region servers的資料節點上,每個Region Server從單獨的分裂的WAL回放WAL。來重建壞掉的Region的MemStore。

資料恢復
WAL 檔案包含編輯列表,一個編輯代表一個單獨的put 、delete.Edits 是按時間的前後順序排列地寫入,為了持久化,增加的檔案將會Append到WAL 檔案的末尾。
當資料在記憶體中而沒有持久化到磁碟上時失敗了將會發生什麼?通過讀取WAL將WAL 檔案回放,
新增和排序包含的edits到當前的MemStore,最後MemStore 重新整理將改變寫入到HFile中。
九 HBase架構的優點
強一致模型:當寫操作返回時,所有的讀將看到一樣的結果
自動擴充套件:Regions 隨著資料變大將分裂;使用HDFS傳播和複製資料
內建的恢復機制:使用WAL
和Hadoop的整合:直接使用mapreduce
十 HBase架構的缺點
WAL回放較慢
故障恢復較慢
主壓縮導致IO瓶頸。
標籤: HBase


1
0
posted @ 2017-11-06 00:03 平和的心 Views(3166) Comments(0) Edit 收藏
註冊使用者登入後才能發表評論,請 登入 或 註冊,訪問網站首頁。
Search
My Tags
Post Categories
Post Archives
Gallery
Recent Comments
Top Posts
推薦排行榜
Copyright ©2018 平和的心