
Hierarchical Attention Networks for Document Classification 模型理解篇
Hierarchical Attention Networks for Document Classification 模型理解篇
本文借鑑了大神的部落格,連結:https://blog.csdn.net/liuchonge/article/details/73610734
最近看了HAN用在文字分類的這篇文章。提出的模型使用了分層的注意力機制,對應了文字在字詞和句子兩個層面的結構。也就是分別在字詞層面和句子層面使用注意力機制。這樣做的好處有兩個:1.模型可以給與不同主要性的字詞或者句子不同的關注度,最終的任務效果因此會更好。2.注意力機制的視覺化可以幫助我們更好的解釋模型。
模型結構
下面是這篇文章提出的模型結構:

我們結合這張圖對模型進行講解。
模型分為4部分:Word encoder, Word attention, sentence encoder 以及 sentence attention
在Word encoder部分,使用雙向的GRU對embedding後的句子進行編碼,得到編碼向量
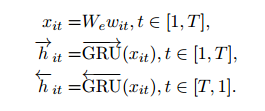
在Word attention部分,首先使用一個單層的MLP對編碼向量
得到一個隱層向量
,然後用這個隱層向量經過softmax得到權重alpha,最終一個句子的表示就是權重alpha與編碼向量
的和,也就是
,他的維度與編碼向量一致。另外,在進行softmax時使用的上下文向量
隨機初始化,並且在馴良過程中不斷改變。
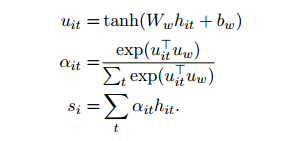
sentence encoder 和 sentence attention與上面提到的兩層本質一樣,只不過將單詞換成了句子,直接上公式,不多做解釋了。
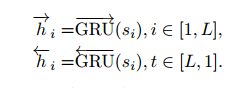
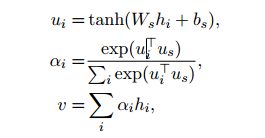
實驗結果分析
為了分析注意力機制模型的效果,文章選取了兩個單詞的例子,good和bad在影評句子中的所佔權重。如圖下圖所示

上圖是對於單詞“good”的權重分佈情況,其中(a)是總體的分佈情況,(b)-(f)分別是在由差評逐漸到好評的過度的過程中“good”的權重的變化情況。從圖中可以看出,隨著好評程度的不斷上升,“good”所獲得的權重越大,這說明,網路能夠自動的將“注意力”放在和好評更相關的詞彙上。

作者同樣對單詞“bad”做了測試,測試結果如上圖所示。顯示出了和前一張一樣的實驗結果,即網路會在差評的時候更加將“注意力”放在“bad”詞彙上。
視覺化
為了進一步說明的注意力機制的作用,同時方便模型解釋。作者對attention下的單詞和句子權重做了視覺化,如下圖

其中,藍色顏色越深說明單詞在句子中的權重越大,粉色顏色越深說明句子文字中的權重越大。可以看出,對整體語義貢更大的單詞或者句子有更高的權重。
好了,對這篇文章的模型介紹就到這裡。下一篇blog我們將對程式碼的實現進行講解。