
Hadoop小檔案處理
導讀
HDFS作為Hadoop生態系統的分散式檔案系統,設計是用來儲存海量資料,特別適合儲存TB、PB量級別的資料。但是隨著時間的推移或者處理程式的問題,HDFS上可能會存在大量的小檔案,進而消耗NameNode大量的記憶體,並且延長程式的執行時間。下面我就把對小檔案的處理經驗總結一下,供大家參考。
引言
先來了解一下Hadoop中何為小檔案:小檔案指的是那些檔案大小要比HDFS的塊大小(在Hadoop1.x的時候預設塊大小64MB,可以通過dfs.blocksize來設定;但是到了Hadoop 2.x的時候預設塊大小為128MB了,可以通過dfs.block.size設定)小的多的檔案。而HDFS的問題在於無法很有效的處理大量小檔案。在HDFS中,任何一個檔案、目錄和block,在HDFS中都會被表示為一個object儲存在Namenode的記憶體中,每一個object佔用150 bytes的記憶體空間。所以,如果有10million個檔案,每一個檔案對應一個block,那麼就將要消耗Namenode 3G的記憶體來儲存這些block的資訊。如果規模再大一些,那麼將會超出現階段計算機硬體所能滿足的極限。不僅如此,HDFS並不是為了有效的處理大量小檔案而存在的。它主要是為了流式的訪問大檔案而設計的。對小檔案的讀取通常會造成大量從Datanode到Datanode的seeks和hopping來retrieve檔案,而這樣是非常的低效的一種訪問方式。
一、概述
HDFS儲存特點:
(1)流式讀取方式,主要是針對一次寫入,多次讀出的使用模式。寫入的過程使用的是append的方式。
(2)設計目的是為了儲存超大檔案,主要是針對幾百MB,GB,TB,甚至PB的檔案。
(3)該分散式系統構建在普通PC機組成的叢集上,大大降低了構建成本,並遮蔽了系統故障,使得使用者可以專注於自身的操作運算。
(4)HDFS適用於高吞吐量,而不適合低時間延遲的訪問。如果同時存入1million的files,那麼HDFS 將花費幾個小時的時間。
(5)流式讀取的方式,不適合多使用者寫入,以及任意位置寫入。如果訪問小檔案,則必須從一個Datanode跳轉到另外一個Datanode,這樣大大降低了讀取效能。
二、HDFS檔案操作流程
HDFS體系結構
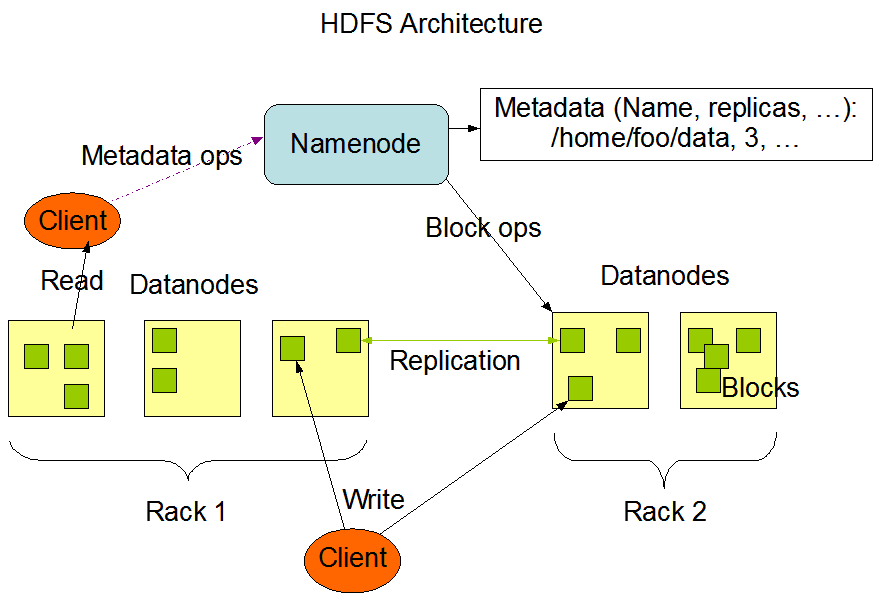
HDFS採用master/slave架構。一個HDFS叢集是由一個Namenode和一定數目的Datanodes組成。Namenode是一箇中心伺服器,負責管理檔案系統的名字空間(namespace)以及客戶端對檔案的訪問。叢集中的Datanode一般是一個節點一個,負責管理它所在節點上的儲存。HDFS暴露了檔案系統的名字空間,使用者能夠以檔案的形式在上面儲存資料。從內部看,一個檔案其實被分成一個或多個數據塊,這些塊儲存在一組Datanode上。Namenode執行檔案系統的名字空間操作,比如開啟、關閉、重新命名檔案或目錄。它也負責確定資料塊到具體Datanode節點的對映。Datanode負責處理檔案系統客戶端的讀寫請求。在Namenode的統一排程下進行資料塊的建立、刪除和複製。
HDFS檔案的讀取
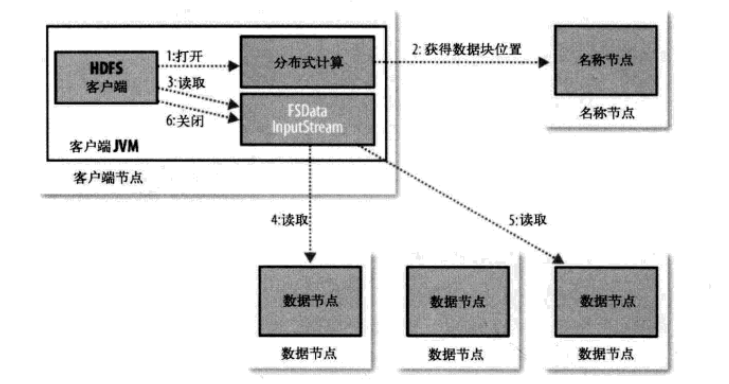
(1)client端傳送讀檔案請求給Namenode,如果檔案不存在,返回錯誤資訊,否則,將該檔案對應的block及其所在Datanode位置傳送給client
(2)client收到檔案位置資訊後,與不同Datanode建立socket連線並行獲取資料。
HDFS檔案的寫入

(1) client端傳送寫檔案請求,Namenode檢查檔案是否存在,如果已存在,直接返回錯誤資訊,否則,傳送給client一些可用Datanode節點
(2)client將檔案分塊,並行儲存到不同節點上Datanode上,傳送完成後,client同時傳送資訊給Namenode和Datanode
(3)Namenode收到的client資訊後,傳送確信資訊給Datanode
(4)Datanode同時收到Namenode和Datanode的確認資訊後,提交寫操作。
三、HDFS小檔案解決方案
1、 HDFS上的小檔案問題
現象:在現在的叢集上已經存在了大量的小檔案和目錄。
方案:檔案是許多記錄(Records)組成的,那麼可以通過呼叫HDFS的sync()方法和append方法結合使用,每隔一定時間生成一個大檔案。或者可以通過寫一個程式來來合併這些小檔案。
2、 MapReduce上的小檔案問題
現象:
Map任務(task)一般一次處理一個塊大小的輸入(input)(預設使用FileInputFormat)。如果檔案非常小,並且擁有大量的這種小檔案,那麼每一個map task都僅僅處理非常小的input資料,因此會產生大量的map tasks,每一個map task都會額外增加bookkeeping開銷。一個1GB的檔案,拆分成16個塊大小檔案(預設block size為64M),相對於拆分成10000個100KB的小檔案,後者每一個小檔案啟動一個map task,那麼job的時間將會十倍甚至百倍慢於前者。
方案:
I、Hadoop Archive:
Haddop Archive是一個高效地將小檔案放入HDFS塊中的檔案存檔工具,它能夠將多個小檔案打包成一個HAR檔案,這樣同時在減少Namenode的記憶體使用。
II、Sequence file:
sequence file由一系列的二進位制key/value組成。key為小檔名,value為檔案內容,可以將大批小檔案合併成一個大檔案。
I、II 這裡不做介紹可以參考(http://blog.cloudera.com/blog/2009/02/the-small-files-problem)
III、CombineFileInputFormat:
Hadoop內建提供了一個 CombineFileInputFormat 類來專門處理小檔案,其核心思想是:根據一定的規則,將HDFS上多個小檔案合併到一個 InputSplit中,然後會啟用一個Map來處理這裡面的檔案,以此減少MR整體作業的執行時間。CombineFileInputFormat類繼承自FileInputFormat,主要重寫了List getSplits(JobContext job)方法;這個方法會根據資料的分佈,mapreduce.input.fileinputformat.split.minsize.per.node、mapreduce.input.fileinputformat.split.minsize.per.rack以及mapreduce.input.fileinputformat.split.maxsize 引數的設定來合併小檔案,並生成List。其中mapreduce.input.fileinputformat.split.maxsize引數至關重要,如果使用者沒有設定這個引數(預設就是沒設定),那麼同一個機架上的所有小檔案將組成一個InputSplit,最終由一個Map Task來處理。如果使用者設定了這個引數,那麼同一個節點(node)上的檔案將會組成一個InputSplit。同一個 InputSplit 包含了多個HDFS塊檔案,這些資訊儲存在 CombineFileSplit 類中,它主要包含以下資訊:
摺疊原始碼
| 1 2 3 4 5 |
|
從上面的定義可以看出,CombineFileSplit類包含了每個塊檔案的路徑、起始偏移量、相對於原始偏移量的大小以及這個檔案的儲存節點。因為一個CombineFileSplit包含了多個小檔案,所以需要使用陣列來儲存這些資訊。CombineFileInputFormat是抽象類,如果我們要使用它,需要實現createRecordReader方法,告訴MR程式如何讀取組合的InputSplit。內建實現了兩種用於解析組合InputSplit的類:org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat 和 org.apache.hadoop.mapreduce.lib.input.CombineSequenceFileInputFormat,我們可以把這兩個類理解是 TextInputFormat 和 SequenceFileInputFormat。為了簡便,這裡主要來介紹CombineTextInputFormat。
在 CombineTextInputFormat 中建立了 org.apache.hadoop.mapreduce.lib.input.CombineFileRecordReader,具體如何解析CombineFileSplit中的檔案主要在CombineFileRecordReader中實現。CombineFileRecordReader類中其實封裝了 TextInputFormat的RecordReader,並對CombineFileSplit中的多個檔案迴圈遍歷並讀取其中的內容,初始化每個檔案的RecordReader主要在initNextRecordReader裡面實現;每次初始化新檔案的RecordReader都會設定mapreduce.map.input.file、mapreduce.map.input.length以及mapreduce.map.input.start引數,這樣我們可以在Map程式裡面獲取到當前正在處理哪個檔案。
樣例程式碼如下:
摺疊原始碼
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
|
日誌輸出:
摺疊原始碼
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
|
可以從日誌中很清楚的看出input檔案為Total input paths to process : 152,通過 CombineFileInputFormat處理後splits為 mapreduce.JobSubmitter: number of splits:1,Map數為 Launched map tasks=1。注意體會mapreduce.input.fileinputformat.split.maxsize引數的設定,大家可以不設定這個引數並且和設定這個引數執行情況對比,觀察Map Task的個數變化。
3、Hive上的小檔案問題
現象1:
輸入檔案過多,而Hive對檔案建立的總數是有限制的,這個限制取決於引數:hive.exec.max.created.files,預設值是10000。如果現在你的表有60個分割槽,然後你總共有2000個map,在執行的時候,每一個mapper都會建立60個檔案,對應著每一個分割槽,所以60*2000> 120000,就會報錯:exceeds 100000.Killing the job 。最簡單的解決辦法就是調大hive.exec.max.created.files引數。但是如果說資料檔案只有400G,那麼你調整這個引數比如說40000。平均下來也就差不多每一個檔案10.24MB,這樣的話就有40000多個小檔案,不是一件很好的事情。
方案1:
設定 mapper 輸入檔案合併引數
摺疊原始碼
| 1 2 3 4 5 6 7 8 |
|
現象2:
hive執行中間過程生成的檔案過多
方案2:
設定中間過程合併引數
摺疊原始碼
| 1 2 3 4 5 6 7 8 |
|
現象3:
hive結果檔案過多
方案3:
設定 reducer 引數 (一種是調整reducer個數,另一種是調整reducer大小)
摺疊原始碼
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
參考文章:
1、https://hadoop.apache.org/docs/r2.7.1/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
2、https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties
3、http://blog.cloudera.com/blog/2009/02/the-small-files-problem/