
並查集的實現與優化
阿新 • • 發佈:2018-12-27
並查集是一種樹型的資料結構,用於處理一些不交集(Disjoint Sets)的合併及查詢問題。有一個聯合-查詢演算法(union-find algorithm)定義了兩個用於此資料結構的操作:
Find:確定元素屬於哪一個子集。它可以被用來確定兩個元素是否屬於同一子集。
Union:將兩個子集合併成同一個集合。
由於支援這兩種操作,一個不相交集也常被稱為聯合-查詢資料結構(union-find data structure)或合併-查詢集合(merge-find set)。其他的重要方法,MakeSet,用於建立單元素集合。有了這些方法,許多經典的劃分問題可以被解決。
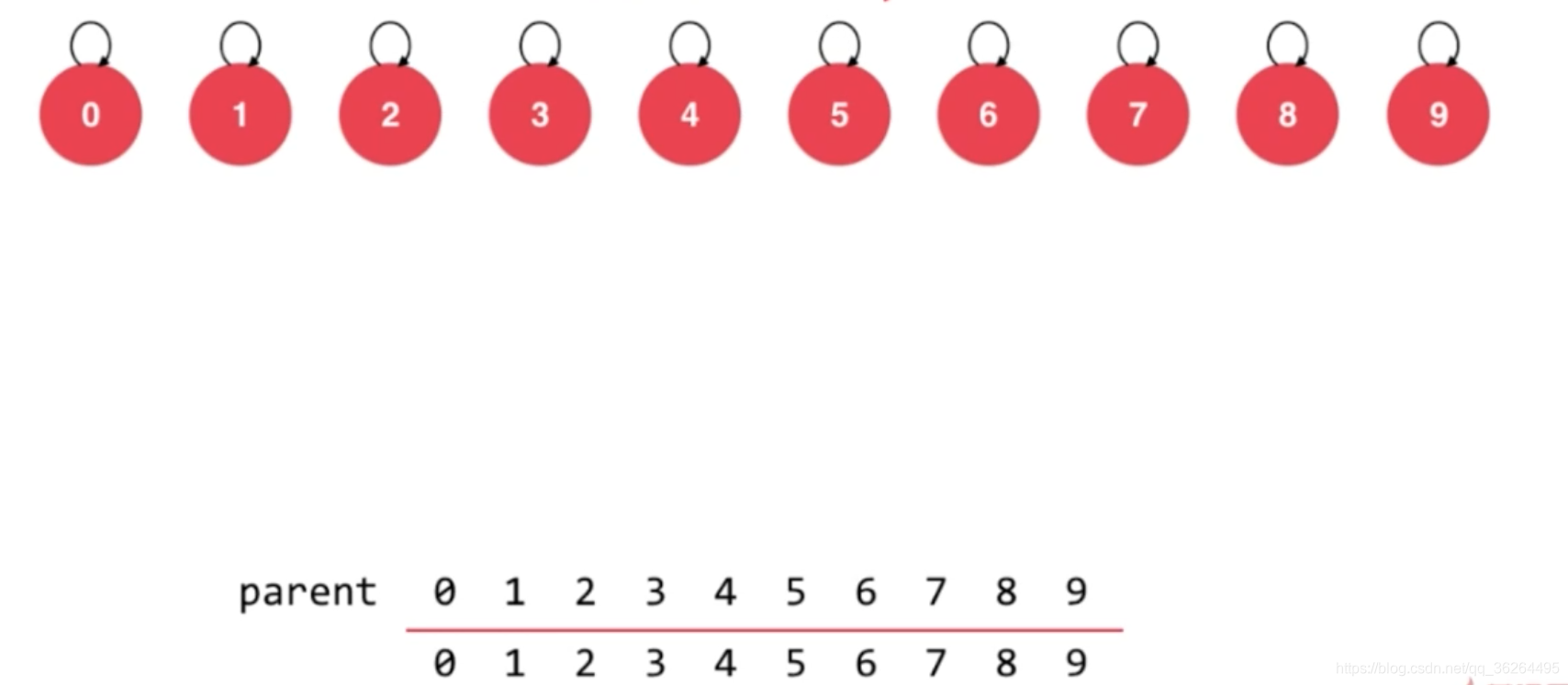
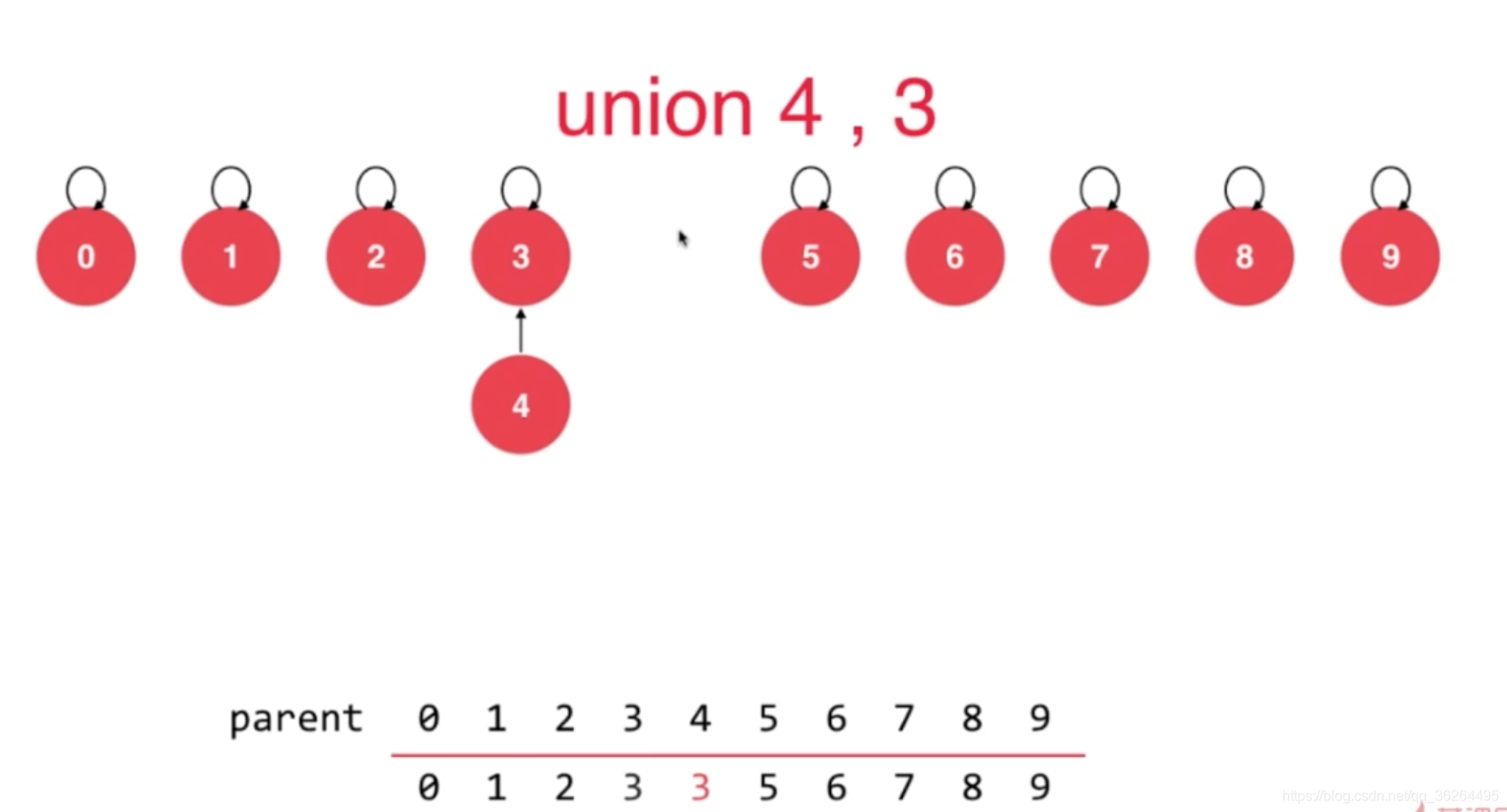

這是並查集森林的最基礎的表示方法,這個方法不會比連結串列法好,這是因為建立的樹可能會嚴重不平衡;然而,可以用兩種辦法優化。
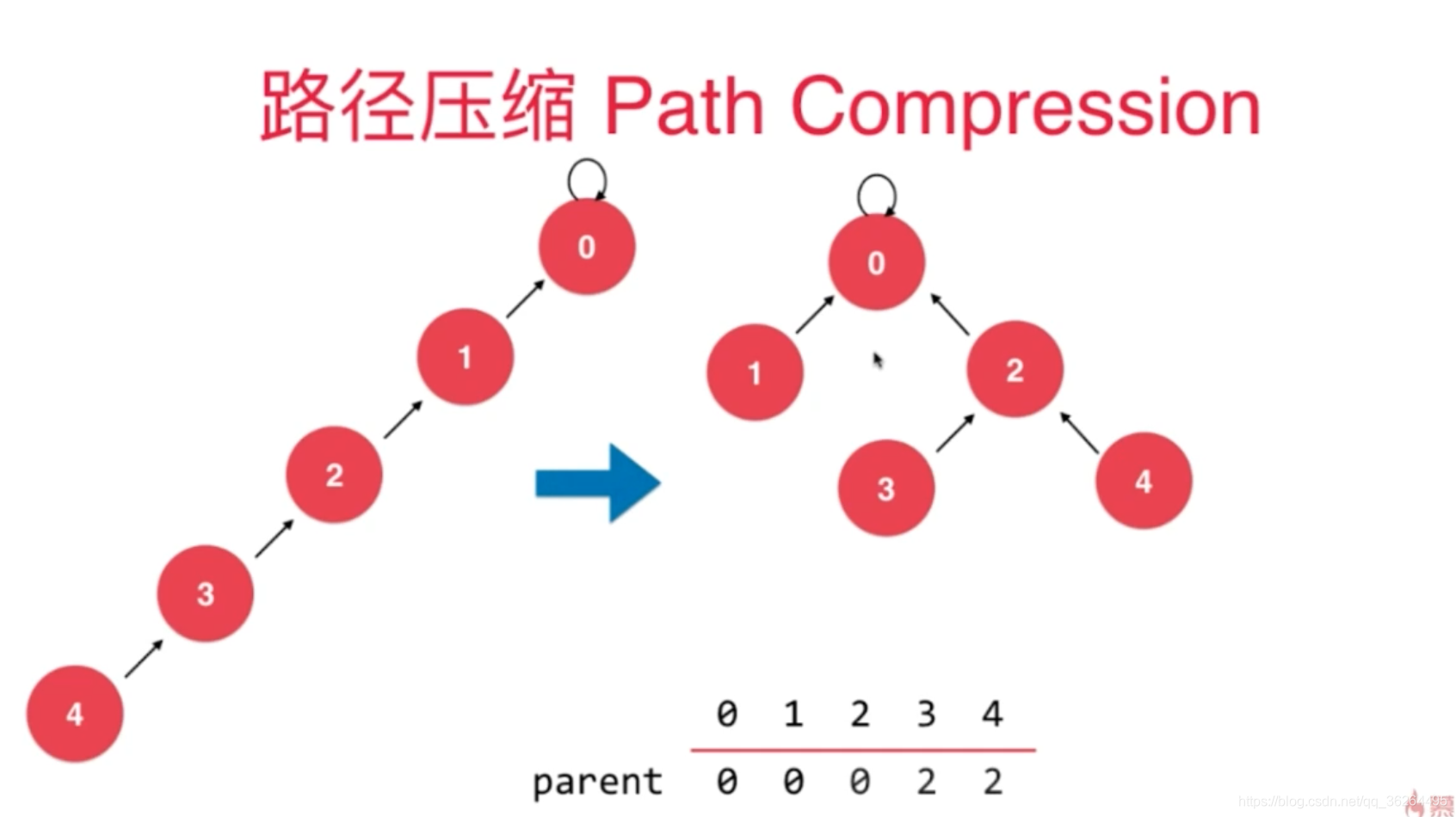
第一種方法,稱為“按秩合併”,即總是將更小的樹連線至更大的樹上。因為影響執行時間的是樹的深度,更小的樹新增到更深的樹的根上將不會增加秩除非它們的秩相同。在這個演算法中,術語“秩”替代了“深度”,因為同時應用了路徑壓縮時(見下文)秩將不會與高度相同。單元素的樹的秩定義為0,當兩棵秩同為r的樹聯合時,它們的秩r+1。只使用這個方法將使最壞的執行時間提高至每個MakeSet、Union或Find操作O(
log n)。

java程式碼實現:
public class UnionFind5